sigmoid专题

SigLIP——采用sigmoid损失的图文预训练方式
SigLIP——采用sigmoid损失的图文预训练方式 FesianXu 20240825 at Wechat Search Team 前言 CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练,本文进行介绍。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注

理解Sigmoid激活函数原理和实现
Sigmoid 激活函数是一种广泛应用于机器学习和深度学习中的非线性函数,特别是在二分类问题中。它的作用是将一个实数值映射到(0, 1)区间,使得输出可以被解释为概率值,这在处理二分类问题时非常有用。 Sigmoid 函数的定义 Sigmoid 函数的数学表达式为: σ ( x ) = 1 ( 1 + e − x ) σ(x)= \frac{1}{(1+e^{-x})} σ(x)=(1+e−

深度学习-激活函数:饱和激活函数【Sigmoid、tanh】、非饱和激活函数【ReLU、Leaky ReLU、RReLU、PReLU、ELU、Maxout】
深度学习-激活函数:饱和激活函数【Sigmoid、tanh】、非饱和激活函数【ReLU、Leaky ReLU、RReLU、PReLU、ELU、Maxout】 一、激活函数的定义:二、激活函数的用途1、无激活函数的神经网络2、带激活函数的神经网络 三、饱和激活函数与非饱和激活函数1、饱和激活函数2、非饱和激活函数 四、激活函数的种类1、Sigmoid函数2、TanH函数3、ReLU(Recti

Caffe Prototxt 激活层系列:Sigmoid Layer
Sigmoid Layer 是DL中非线性激活的一种,在深层CNN中,中间层用得比较少,容易造成梯度消失(当然不是绝对不用);在GAN或一些网络的输出层常用到 首先我们先看一下 SigmoidParameter message SigmoidParameter {enum Engine {DEFAULT = 0;CAFFE = 1;CUDNN = 2;}optional Engine engi
torchvision笔记 torchvision.ops.sigmoid_focal_loss
理论部分:机器学习笔记:focal loss-CSDN博客 torchvision.ops.sigmoid_focal_loss(inputs: Tensor, targets: Tensor, alpha: float = 0.25, gamma: float = 2, reduction: str = 'none') inputs每个样本的预测值targets 与 inputs 形状相同
matlab画sigmoid函数和其一阶倒数
最近在做神经网络CNN的仿真,发现matlab中竟然没有直接对激活函数sigmoid的实现, 其实也是非常简单,但是由于matlab不是很常用,于是乎就有了这个,我估计很多网友都会遇到,写这个是为了方便大家吧。 x=-10:2:10;y=1./(1+exp(-x));plot(x,y); 一定要用点除‘./’,因为是矩阵运算,所以要把纬度保持一致。 运行结果如下: 该sigmoi

ReLU Sigmoid and Tanh(2)
Sigmoid 它能够把输入的连续实值“压缩”到0和1之间。如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1. 缺点: 当输入非常大或者非常小的时候,这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradientkill

ReLU Sigmoid and Tanh
ReLU 激活函数: ReLu使得网络可以自行引入稀疏性,在没做预训练情况下,以ReLu为激活的网络性能优于其它激活函数。 数学表达式: y=max(0,x) Sigmoid 激活函数: sigmoid 激活函数在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。 数学表达式(正切函数): y=(1+exp(−x))−1 导数:f(z)' = f(z)(1
关于sigmoid与binary_crossentropy,以及softmax与categorical_crossentropy的关系,以及各损失函数的定义。
1,用sigmoid作为激活函数,为什么往往损失函数选用binary_crossentropy 参考地址:https://blog.csdn.net/wtq1993/article/details/51741471 2,softmax与categorical_crossentropy的关系,以及sigmoid与bianry_crossentropy的关系。 参考地址:https://www.
整理Sigmoid~Dice常见激活函数,从原理到实现
本文首发于我的个人博客: 激活函数:https://fuhailin.github.io/activation-functions/ 并同步于我的公众号:赵大寳Note(ID:StateOfTheArt),回复关键词【激活函数】下载全部代码。 激活函数之性质 1. 非线性:即导数不是常数。保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。 2. 可微性:保证了在优化中梯度的可计算性
Softmax和Sigmoid
Softmax和Sigmoid函数在机器学习和深度学习中都扮演着重要的角色,但它们在功能和应用上存在一些关键的区别。 功能和应用领域: Softmax函数:主要用于多分类问题。它将一组实数(通常是神经网络的输出)转换为一组概率分布,这些概率表示输入数据属于各个类别的可能性。因此,在机器学习和深度学习中,Softmax函数常用于多分类任务的输出层,如图像分类、文本分类等。 Sigmoid函数:主
![[机器学习] softmax,sigmoid,relu,tanh激活函数](https://img-blog.csdnimg.cn/img_convert/25145fe35a0055a899553c9c5dad10e8.png)
[机器学习] softmax,sigmoid,relu,tanh激活函数
参考: https://blog.csdn.net/weixin_43483381/article/details/105232610 参考 :https://blog.csdn.net/zhuiyuanzhongjia/article/details/80576779 参考: https://www.sohu.com/a/452666201_809317 softmax 与 sigmoid 结

15_岭回归-Ridge、岭回归API、线性回归和岭回归的对别;逻辑回归、sigmoid函数、逻辑回归公式、损失函数、逻辑回归API、逻辑回归案例、逻辑回归的优缺点、逻辑回归 VS 线性回归等
1、岭回归 岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。 1.1 Ridge线性回归sklearn API sklearn.linear_model.Ridge class sklearn.linear_model
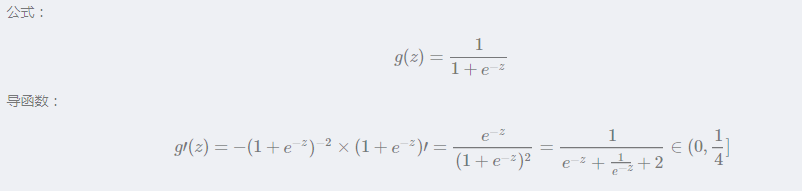
sigmoid函数温习【函数曲线可视化与导函数曲线可视化】
今天晚上遇到一个问题就是sigmoid函数,我只记得sigmoid函数的原始函数曲线是什么样子的,但是导函数是什么样子我还真的是不记得了,恰巧就被问到了这个问题,还顺便问了一下导函数的取值范围是多少,如果当时有纸和笔的话我倒是可是现场算一算的,但是当时是在阳台上没有办法去算,尴尬...... 结束了这一次的尴尬之后,回到工位上抓紧温习一下,先绘制一下sig
Sigmoid Belief Net
概率生成模型(generative model)的目标就是要最大化输入数据x的概率p(x),信念网络是图理论与概率论结合,信念网(Belief Nets)需要解决两个问题: 1. 推理(inference),推导未观察变量的状态。 2. 学习(learning),调整权值使得观察变量生成的概率最大。 早期的图模型是人工定义图结构(各节点之间的关系)和各变量之间的条件概率。对于随机生成神经网来
【机器学习300问】65、为什么Sigmoid和Tanh激活函数会导致梯度消失?
一、梯度消失现象 当神经网络的输入值较大或较小时,其导数(梯度)都会接近于0。在反向传播过程中,这些微小的梯度经过多层网络逐层传递时,会不断被乘以权重矩阵(权重通常小于1),进一步导致梯度值缩小,直至几乎消失。这种现象称为“梯度消失”,它会使深度神经网络的学习过程变得极其缓慢,甚至无法有效训练深层网络。 二、Sigmoid激活函数 Sigmoid函数的公式为。

sigmoid、 tanh、 tanh、 tanh比较
由上篇文章,我们知道逻辑回归是怎么过渡到神经网络的了 总的来说就一句话——多个逻辑回归模型,前后堆积形成了神经网络! 我引用吴恩达中的一张图,稍微的回顾以下这个过程 对于这张图,它的过程是这样的: 输入1个样本(含3个特征),分别到4个逻辑回归中(中间那一列的4个圈圈)对于样本的输入,逻辑回归模型分别通过y = wx + b后将y值通过Sigmoid函数映射到01区间内,那么这里就有4个输
python绘制激活函数(sigmoid, Tanh, ReLU, Softmax)
import numpy as npimport matplotlib.pyplot as plt# matplotlib的负数显示设置 plt.rcParams['axes.unicode_minus'] = False # 显示负数# 输出高清图像%config InlineBackend.figure_format = 'retina'%matplotlib inline#
为什么交叉熵损失可以提高具有sigmoid和softmax输出的模型的性能,而使用均方误差损失则会存在很多问题
为什么交叉熵损失可以提高具有sigmoid和softmax输出的模型的性能,而使用均方误差损失则会存在很多问题 2017年10月16日 10:42:08 guoyunfei20 阅读数 4052 更多 分类专栏: 深度学习基础理论 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 本文链接:

yolo模型中神经节点Mul与Sigmoid 和 Conv、Concat、Add、Resize、Reshape、Transpose、Split
yolo模型中神经节点Mul与Sigmoid 和 Conv、Concat、Add、Resize、Reshape、Transpose、Split 在YOLO(You Only Look Once)模型中,具体作用和用途的解释:
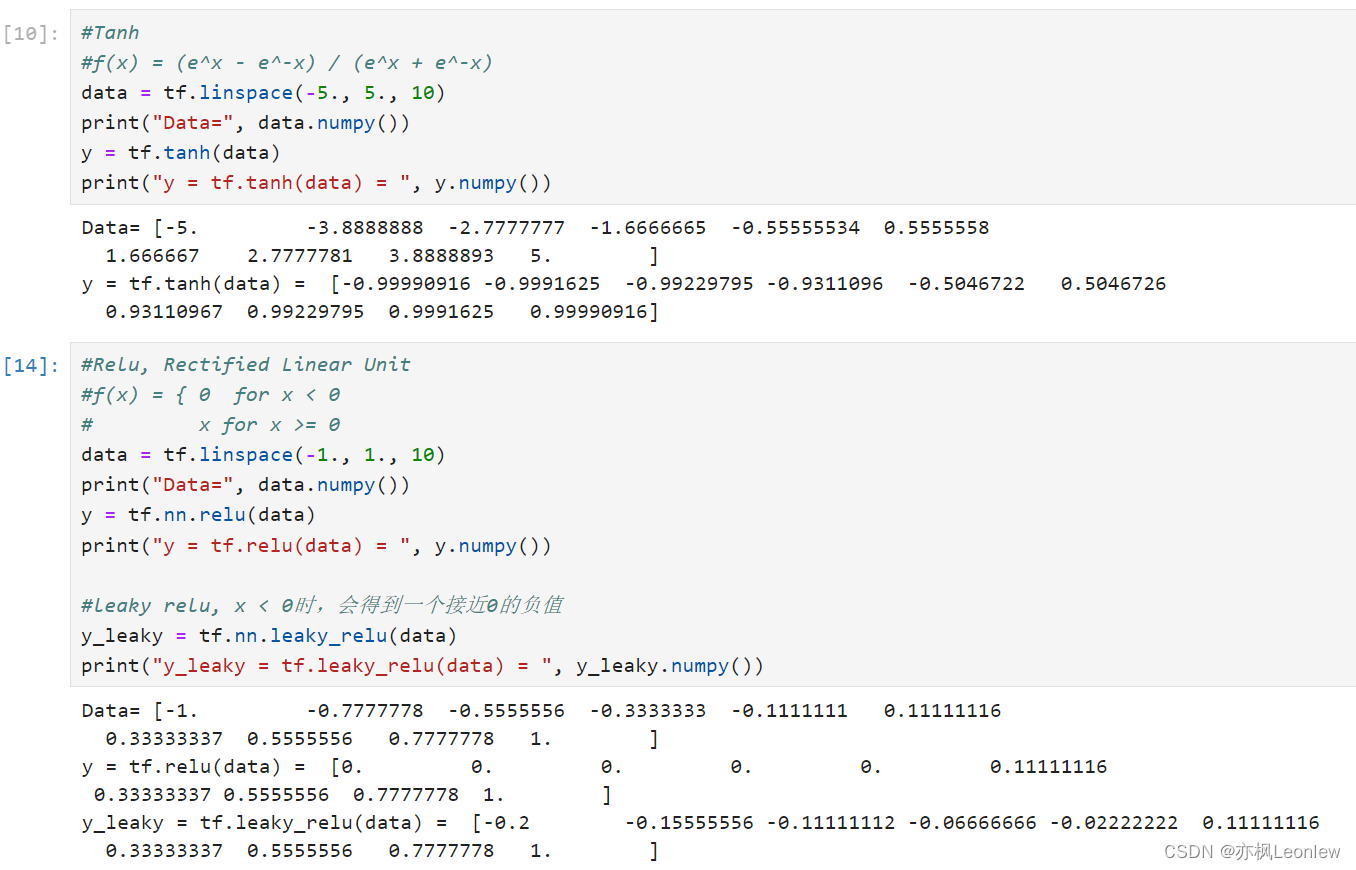
Tensorflow2.0笔记 - 常见激活函数sigmoid,tanh和relu
本笔记主要记录常见的三个激活函数sigmoid,tanh和relu,关于激活函数详细的描述,可以参考这里: 详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等) - 知乎 import tensorflow as tfimport numpy as nptf.__version__#详细的激活函数参考资料#https://zhuanla
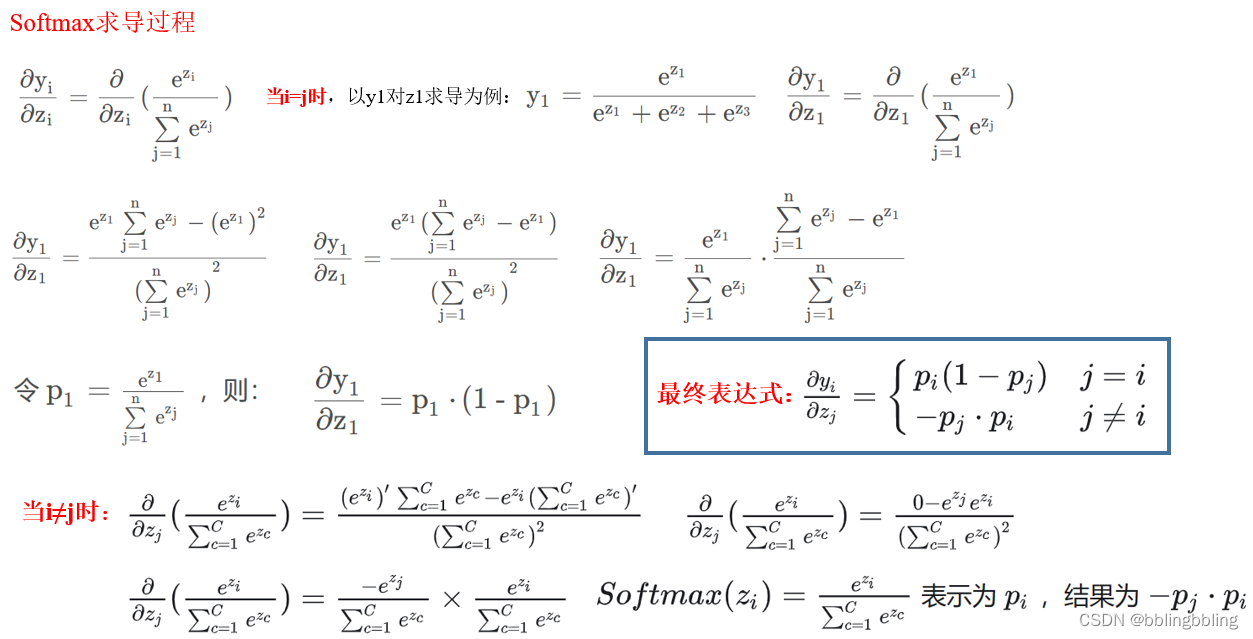
softmax和sigmoid的区别
sigmoid 公式: s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1 + e^{-x}} sigmoid(x)=1+e−x1 函数曲线如下: 导数公式: f ( x ) ′ = e − x ( 1 + e − x ) 2 = f ( x ) ( 1 − f ( x ) ) f(x)\prime = \frac{

逻辑斯蒂回归用sigmoid函数的原因?
sigmoid函数的数学公式 sigmoid函数的因变量x取值范围是-∞到+∞,(-∞,+∞),但是sigmoid函数的值域是(0, 1)。 不管x取什么值其对应的sigmoid函数值一定会落到(0,1)范围内~~~ 漂亮的logistic 曲线 sigmoid函数对应的图形就是logistic曲线,logistic曲线对应的函数就是sigmoid函数。

Sigmoid型函数梯度消失、“死亡”ReLUs 和 RNNs梯度爆炸问题
Sigmoid型函数的梯度消失问题 基础知识 s i g m o i d sigmoid sigmoid 是一种函数类型,具有函数图形为S型曲线,单增,反函数也单增,而且输出值范围为(0,1)等特点,但其一般被默认为是 l o g i s t i c logistic logistic 函数: S ( x ) = 1 1 + exp ( − x ) S(x) = \frac{1}{1

神经网络之激活函数(sigmoid、tanh、ReLU)
神经网络之激活函数(Activation Function) 补充:不同激活函数(activation function)的神经网络的表达能力是否一致? 激活函数理论分析对比 转载:http://blog.csdn.net/cyh_24 :http://blog.csdn.net/cyh_24/article/details/50593400 日常 coding 中,我们会很自然
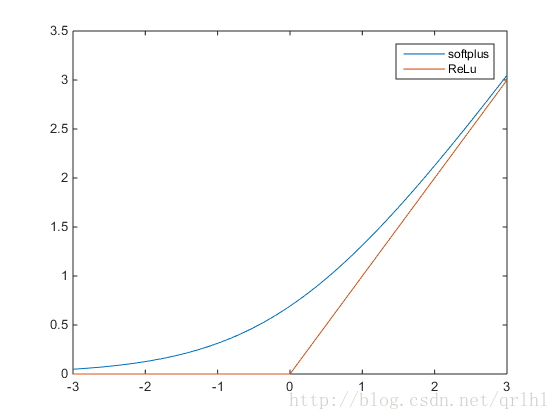
激活函数-Sigmoid,Tanh,ReLu,softplus,softmax
PS:在学习深度学习的搭建时,用到不同的激活函数,因此查阅了这些函数,转自:http://blog.csdn.net/qrlhl/article/details/60883604#t2,对其中我认为有误的地方进行了一点修正。 不管是传统的神经网络模型还是时下热门的深度学习,我们都可以在其中看到激活函数的影子。所谓激活函数,就是在神经网络的神经元上 运行的函数,负责将神经元的输入映射到输出