sharding专题

使用SpringBoot整合Sharding Sphere实现数据脱敏的示例
《使用SpringBoot整合ShardingSphere实现数据脱敏的示例》ApacheShardingSphere数据脱敏模块,通过SQL拦截与改写实现敏感信息加密存储,解决手动处理繁琐及系统改... 目录痛点一:痛点二:脱敏配置Quick Start——Spring 显示配置:1.引入依赖2.创建脱敏

Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现分库分表+读写分离
在上一篇文章介绍了如何使用Sharding-jdbc进行分库+读写分离,这篇文章将讲述如何使用Sharding-jdbc进行分库分表+读写分离。 架构回顾 在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下: 在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。 在数据量继续扩大,这时可以考虑分库分

Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现数据分表+读写分离
读写分离 在上一篇文章介绍了如何使用Sharing-JDBC实现数据库的读写分离。读写分离的好处就是在并发量比较大的情况下,将查询数据库的压力 分担到多个从库中,能够满足高并发的要求。比如上一篇实现的那样,架构图如下: 数据分表 当数据量比较大的时候,比如单个表的数据量超过了500W的数据,这时可以考虑将数据存储在不同的表中。比如将user表拆分为四个表user_0、user_1、 user_2
Sharding-JDBC教程:Spring Boot整合Sharding-JDBC实现读写分离
Sharding-JDBC简介 Sharding-JDBC是的分布式数据库中间件解决方案。Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)是3款相互独立的产品,共同 组成了ShardingSphere。Sharding-JDBC定位于轻量级的Java框架,它使用客户端直连数据库,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
Sharding-JDBC教程:Mysql数据库主从搭建
mysql 5.7 安装 这是系列文章Sharding-jdbc文章的第一篇,本篇文章主要讲述如何搭建Mysql的主从。搭建环境为centos 7.5,数据库版本为5.7。需要三台虚拟机,一主两从,读者可以在自己的电脑上创建虚拟机,也可以在云服务商买三台,按小时计费,一小时几毛钱,比较实惠。Ip分配如下: 10.0.0.5 主 10.0.0.13 从 10.0.0.17 从 安装Mysql 5.

数据库分库分表(sharding)---全局主键生成策略
第一部分:一些常见的主键生成策略 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有: 1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外
Sharding(切片)技术(解决数据库分库一致性问题)
Sharding(切片) 不是一门新技术,而是一个相对简朴的软件理念,就是当我们的数据库单机无法承受高强度的i/o时,我们就考虑利用 sharding 来把这种读写压力分散到各个主机上去。 所以Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是Horizontal Partitioning 水平扩展(或横向扩展)的解决方案,其主要目的是为突破单节点数
数据库分库分表(sharding)(四)
一、多数据源的事务处理 分布式事务 这是最为人们所熟知的多数据源事务处理机制。本文并不打算对分布式事务做过多介绍,读者可参考此文:关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究 。在这里只想对分布式事务的利弊作一下分析。 优势: 1. 基于两阶段提交,最大限度地保证了跨数据库操作的“原子性”,是分布式系统下最严格的事务实现方式。

数据库分库分表(sharding)(二) 全局主键生成策略
第一部分:一些常见的主键生成策略 一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有: 1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外

数据库分库分表(sharding)(一) 拆分实施策略和示例演示
第一部分:实施策略 图1.数据库分库分表(sharding)实施策略图解(点击查看大图) 1.准备阶段 对数据库进行分库分表(Sharding化)前,需要开发人员充分了解系统业务逻辑和数据库schema.一个好的建议是绘制一张数据库ER图或领域模型图,以这类图为基础划分shard,直观易行,可以确保开发人员始终保持清醒思路。对于是选择数据库ER图还是领域模型图
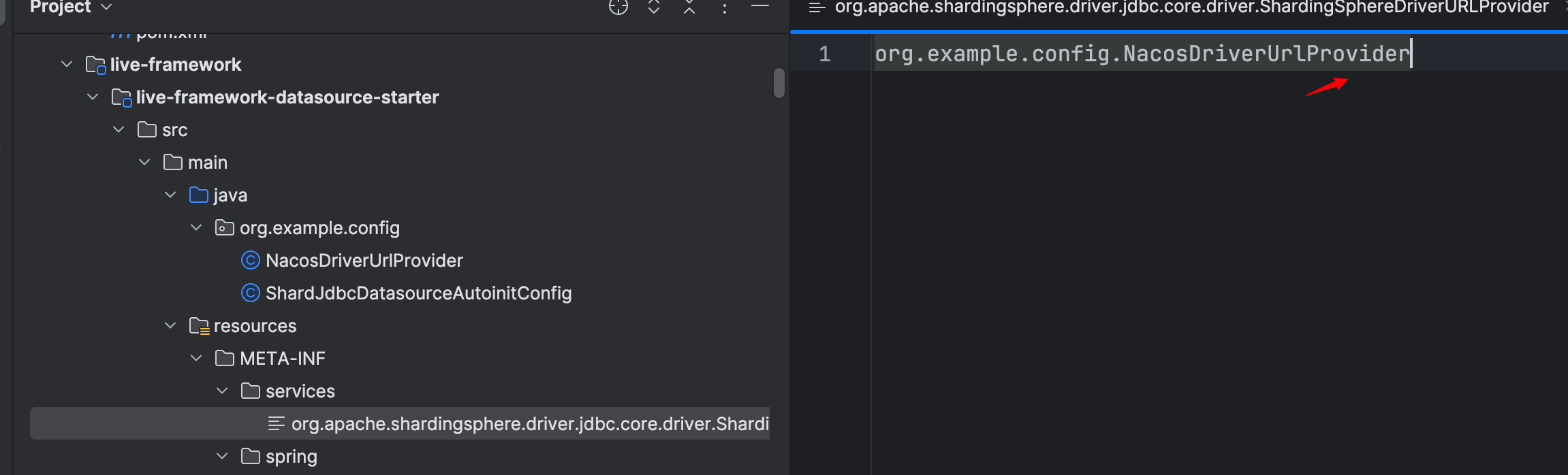
Sharding-JDBC 使用 Nacos 作为配置中心 【下 代码实战】
Sharding-JDBC 使用 Nacos 作为配置中心 【下 代码实战】 1. 实现 ShardingSphereDriverURLProvider 由上一篇博文我们已经知道了 Sharding-JDBC 是基于 Java SPI 机制去加载 并实例化 ShardingSphereDriverURLProvider 的实现类 public interface ShardingSphere

ShardingSphere概述(Sharding-JDBC入门)
ShardingSphere > 概览 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。 Shardin

Sharding-Proxy数据插入报错Sharding value must implements Comparable NoSuchElementException
数据插入报错 做了分库分表,现在需要将已有的单个数据库的数据,迁移到对应的分库分表数据库数据迁移,是读取指定表的表结构信息,使用PreparedStatement,使用占位符将数据拼接提交为了防止迁移出错,多次迁移,每次将sharding表先清空,后迁移迁移中,遇到一些报错,版本5.0 报错一 Sharding value must implements Comparable Comman
Sharding-Proxy分库分表和数据加密
文章目录 Sharding-Proxy分库分表和数据加密使用场景配置文件讲解server.yamlconfig-sharding.yamlconfig-encrypt.yaml其他 使用情况总结 Sharding-Proxy分库分表和数据加密 主要将实际项目中使用shardingshpere-proxy的经历经验,总结分享一下。 使用场景 公司规划研发了两款针对政务新媒体和
sharding切分策略
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sharding缺少基本的了解,请参考我另一篇从基础理论全面介绍sharding的文章:数据库Sharding的基本思想和切分策略 第一部分:实施策略 图1.数据库分库分表
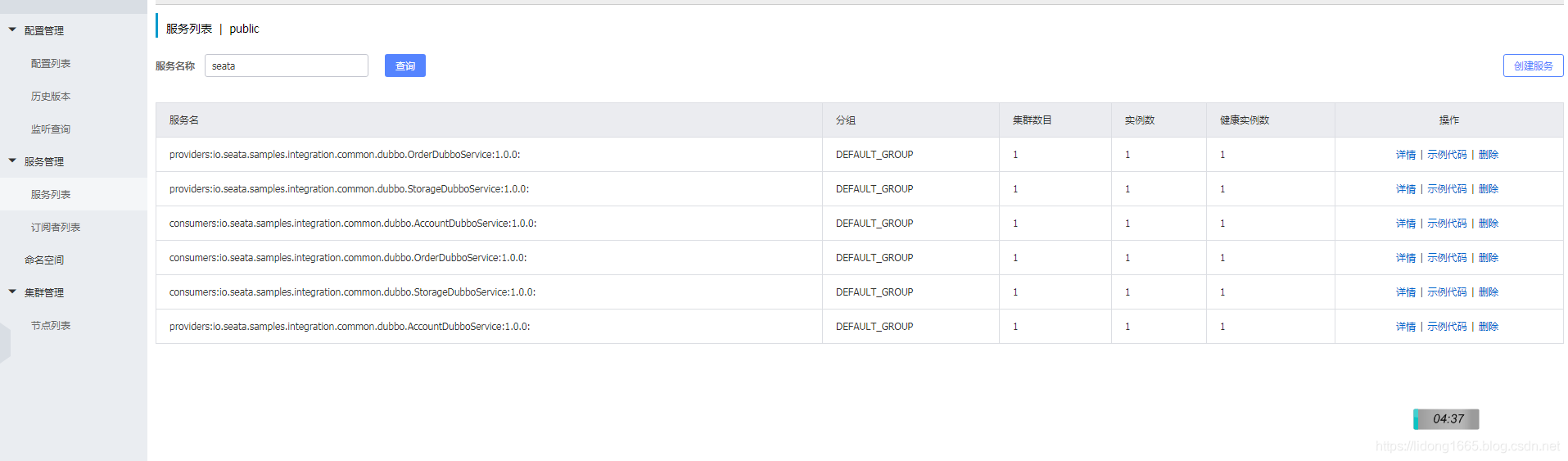
让您轻松入门分布式事务Seata和分库分表sharding-sphere的整合
1.介绍 本篇将介绍,如何进行seata1.2.0、sharding-sphere4.1.0和dubbo2.7.5 的整合,以及使用nacos作为我们的配置中心和注册中心。如果你还是一个初学者,先建议学习一下,陈建斌的七步带你集成Seata 1.2 高可用搭建,这篇文章清楚的阐述了初学者容易遇到的5个问题,并且都提供完整的解决思路。 2.环境配置 mysql: 5.7.12 nacos:

sharding sphere 4.0.0-RC1版本 按年分表(后续优化)
1. sharding sphere 4.0.0-RC1版本 按年分表(后续优化) 1.1. 概述 关于上一篇中LogShardingAlgorithm的tables,我原先是在第一次调用的时候初始化,这样做虽然能实现功能,但每次调用都会走这个if判断,虽然性能损耗不大,但我觉得这不是业务应该走的逻辑顺序,我的理想是在LogShardingAlgorithm被实例化后去自动初始化tables

sharding sphere 4.0.0-RC1版本 按年分表(自动建表)
1. sharding sphere 4.0.0-RC1版本 按年分表(自动建表) 1.1. 概述 上篇文章留了个坑,sharding sphere本身没有提供自动建表功能,但我想了想,我们可以绕过它本身的设定,它本身的数据分片是通过分片算法实现,如下继承一些接口PreciseShardingAlgorithm、RangeShardingAlgorithm等,在范围查询的时候,原本我们需要从a

sharding sphere 4.0.0-RC1版本 按年分表实战
1. sharding sphere 4.0.0-RC1版本 按年分表实战 1.1. 需求 需要对日志表进行按时间划分表,由于用于后台系统,日志量预估不会太大,因此按年划分表 经过我不断的查阅sharding sphere资料和实践,我最后还是决定先建表,再把actual-data-nodes表结点给定下来,为什么这么说? 我纠结的是到底要不要动态创建表,若想要不自己手动每隔几年维护表,我们当然
kingshard--一个支持sharding的MySQL Proxy项目
kingshard简介 kingshard(https://github.com/flike/kingshard)是一个由Go开发高性能MySQL Proxy项目,kingshard在满足基本的读写分离的功能上,致力于简化MySQL分库分表操作;能够让DBA通过kingshard轻松平滑地实现MySQL数据库扩容。 主要功能: 1.读写分离。2.跨节点分表。3.客户端IP访问控制。
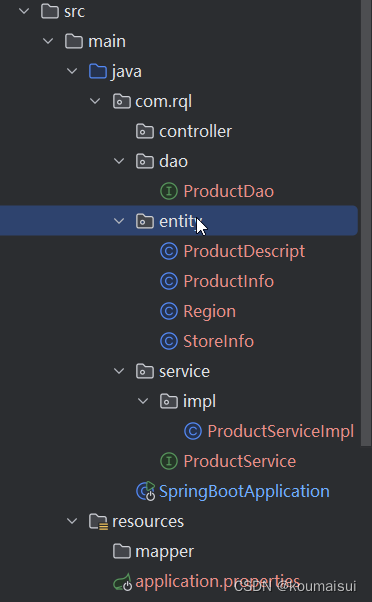
案例:SpringBoot集成Sharding-JDBC实现分表分库与主从同步(详细版)
案例:SpringBoot集成Sharding-JDBC实现分表分库与主从同步:详细版 1. 案例分析2. 主从同步2.1 主从数据库准备2.2 简单插点数据 3 案例代码3.1 application.properties配置信息3.2 测试 4. 遇到的坑4.1 水平分表时的属性设置4.2 绑定表的配置 1. 案例分析 表结构: 垂直分库:STORE_DB与PRODUCT
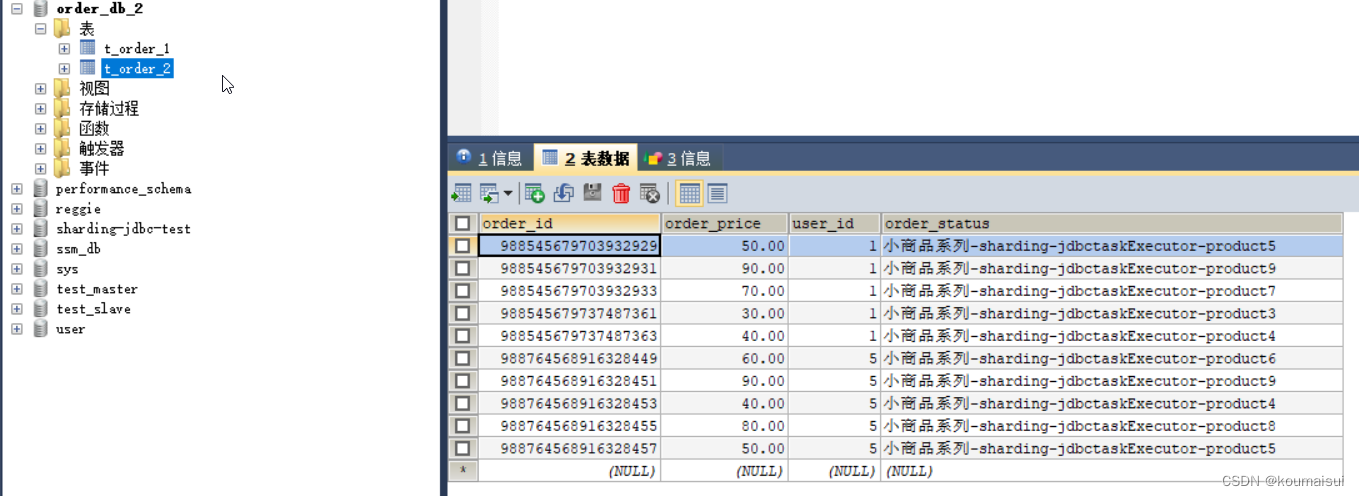
SpringBoot集成Sharding-jdbc水平分表分库
SpringBoot集成Sharding-jdbc水平分表分库 1.水平分表分库2.参数配置2.application.properties 3.代码测试3.1 数据插入 1.水平分表分库 概念在之前写章中:Sharding-JDBC笔记1 2.参数配置 2.application.properties # Server portserver.port=8080# My
SpringBoot集成Sharding-jdbc(水平分表)
SpringBoot集成Sharding-jdbc(水平分表) 1.Sharding-jdbc的应用场景2.实际使用2.0 项目层级2.1 导入依赖2.2 application.yml配置2.3 dao层2.4 对应的mybatis的xml文件2.5 Service层2.6 pojo2.7 controller2.8 多线程配置 1.Sharding-jdbc的应用场景 其实

Mycat\atlas\sharding-jdbc
背景 数据库中间件选型思考 官网上安装、配置信息零散,需要使用者收集整理信息,在理解基础上正确配置,才能保证运行成功。这个工作比较耗时,希望读者看到此博客能快速run起来。 网络博客上也有很多人写Mycat和Atlas,绝大多数是针对Mycat和Atlas读写分离场景配置的。对Atlas,奇虎360在GitHub上开源了2个版本,一个版本为纯代理版,支持分表功能,另一个为Sharding版本。
记录 RuoYi-Vue 项目集成 Sharding-JDBC 遇到的问题与解决办法
目录 前提说明环境需求背景 遇到的问题与解决办法问题1、LocalDateTime转换报错问题描述解决办法 问题2、初始化分表数据,数据量过大,造成内存溢出问题描述解决方法代码如下: 问题3、`count()`查询结果不正确问题描述解决方法代码如下: 问题4、已分表的表需要和其他表联查,并且需要分页,会报错问题描述解决方法代码如下: 问题5、数据统计 sql中用到`group by`和

Sharding-JDBC——分库分表+读写分离
一、简介 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。支持任何第三方的数据库连接池,如:D