本文主要是介绍Sharding-JDBC 使用 Nacos 作为配置中心 【下 代码实战】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Sharding-JDBC 使用 Nacos 作为配置中心 【下 代码实战】
1. 实现 ShardingSphereDriverURLProvider
由上一篇博文我们已经知道了 Sharding-JDBC 是基于 Java SPI 机制去加载 并实例化 ShardingSphereDriverURLProvider 的实现类
public interface ShardingSphereDriverURLProvider {boolean accept(String var1);byte[] getContent(String var1);
}
ShardingSphereDriverURLProvider接口有两个抽象方法 accept()方法用于判断当前的url是否满足条件,如果满足将调用 getContent ()方法获取数据源配置信息。因此我们可以新建一个 NacosDriverUrlProvider 实现 ShardingSphereDriverURLProvider ,并在 META-INF/services下新建一个文件 org.apache.shardingsphere.driver.jdbc.core.driver.ShardingSphereDriverURLProvider ,文件内容为 NacosDriverUrlProvider 的全限定类名。

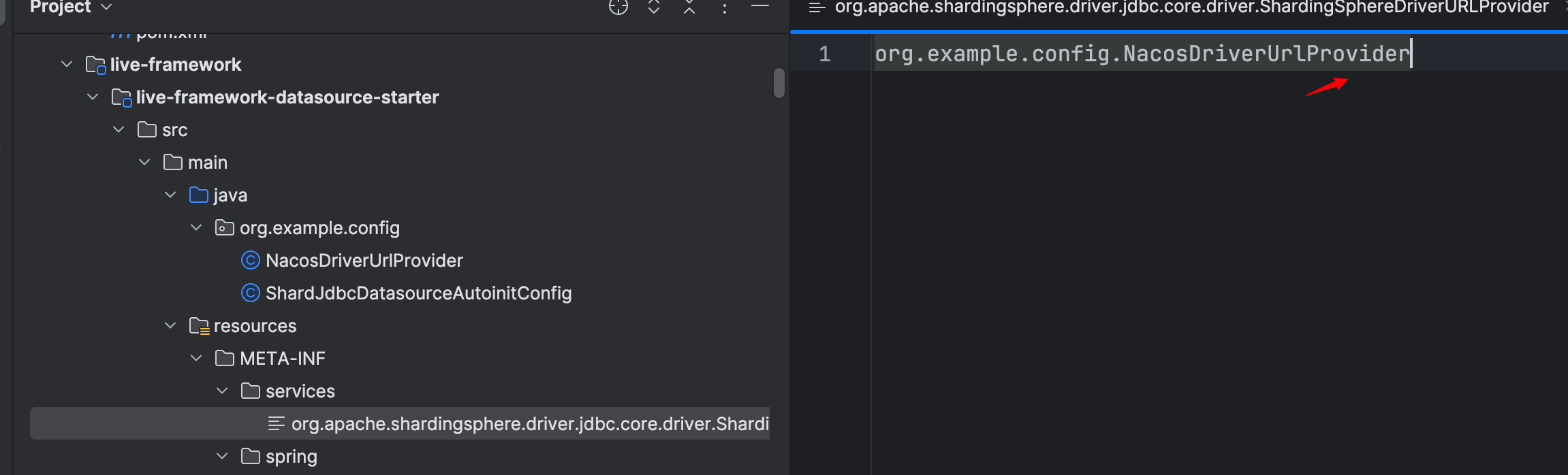
2.NacosDriverUrlProvider
2.1 重写 accept() 方法
我们先重写 accept()方法,判断url中是否包含 “nacos:”,如果有,则适用于 NacosDriverUrlProvider 类去加载配置
private final static String NACOS_MARK = "nacos:";@Override
public boolean accept(String url) {return StringUtils.isNotBlank(url) && url.contains(NACOS_MARK);
}
2.2 重写 getContent() 方法
我们获取到nacos的url的连接后,通过 NacosFactory.createConfigService 去获取 nacos的配置信息,相关案例在nacos官网也有实例代码
try {String serverAddr = "{serverAddr}";String dataId = "{dataId}";String group = "{group}";Properties properties = new Properties();properties.put("serverAddr", serverAddr);ConfigService configService = NacosFactory.createConfigService(properties);String content = configService.getConfig(dataId, group, 5000);System.out.println(content);
} catch (NacosException e) {// TODO Auto-generated catch blocke.printStackTrace();
}
将url分割获取到参数后,封装到 Properties 中,然后通过 NacosFactory.createConfigService 获取 ConfigService 对象后获取到配置信息
private final static String FIXED_PREFIX = "jdbc:shardingsphere:";public byte[] getContent(String url) {int nacosPrefix = url.indexOf(FIXED_PREFIX + NACOS_MARK);String realUrl = url.substring(nacosPrefix + (FIXED_PREFIX + NACOS_MARK).length(), url.length());int serverAddrEndIndex = realUrl.indexOf("?");String serverAddr = realUrl.substring(0, serverAddrEndIndex);String args = realUrl.substring(serverAddrEndIndex+1, realUrl.length());String[] split = args.split("&");String dataId = "";String group = "";String namespace = "";String username = "";String password = "";for (String str : split) {int index = str.indexOf("=");String substring = str.substring(0, index);switch (substring){case "dataId" :dataId = str.substring(index+1,str.length());break;case "group" :group = str.substring(index+1,str.length());break;case "namespace" :namespace = str.substring(index+1,str.length());break;case "username" :username = str.substring(index+1,str.length());break;case "password" :password = str.substring(index+1,str.length());break;}}String content = "";try {Properties properties = new Properties();properties.put("serverAddr", serverAddr);properties.put("namespace", namespace);properties.put("username", username);properties.put("password", password);ConfigService configService = NacosFactory.createConfigService(properties);content = configService.getConfig(dataId, group, 5000);} catch (NacosException e) {// TODO Auto-generated catch blocke.printStackTrace();}return content.getBytes();
}
这篇关于Sharding-JDBC 使用 Nacos 作为配置中心 【下 代码实战】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





