rmsprop专题

adagrad ,RMSProp Momentum
adagrad: 对于每一个 wti w i t w_i^t,都由前t-1对 wi w i w_i的梯度和的平方加上本次对 wi w i w_i梯度的平方再开根号。用这个值去除η。 缺点,随着update的次数增多,learning rate会变得特别小,最终导致提前结束训练。 δ是个小常数,通常设为10^-7。这个是防止右值太小的话稳定学习率。 RMSProp: 对于α我
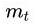
SGD,Momentum,AdaGrad,RMSProp,Adam等优化算法发展历程
各种优化算法层出不穷,看的眼花缭乱,如果不能理清楚其中他们的关系及发展历程,必然会记得很混乱及模糊 最开始做神经网络的时候大家更新参数的时候都是把所有数据计算一遍,求所以数据的平均梯度再进行参数调节,后来觉得这样太慢了,干脆就计算一条数据就调节一次,这就叫随机梯度下降了(SGD),随机两字的由来是因为每条数据可能调节的方向都不一样,下降的过程会很震荡。 这都是两个极

用c++用4个凸函数(觉得啥好用用啥)去测试adam,rmsprop,adagrad算法的性能(谁先找到最优点)
为了测试 Adam、RMSProp 和 Adagrad 算法的性能,你可以使用四个凸函数进行实验。以下是一些常用的凸函数示例: Rosenbrock 函数: Booth 函数: Himmelblau 函数: Beale 函数: 你可以选择其中一个或多个函数来测试算法的性能。对于每个函数,你可以使用不同的初始点,并应用 Adam、RMSProp 和 Adagrad 算法来寻找最优
【机器学习300问】82、RMSprop梯度下降优化算法的原理是什么?
RMSprop,全称Root Mean Square Propagation,中文名称“均方根传播”算法。让我来举个例子给大家介绍一下它的原理! 一、通过举例来感性认识 建议你第一次看下面的例子时忽略小括号里的内容,在看完本文当你对RMSprop有了一定理解时再回过头来读一次这个小例子,这次带上小括号的内容一起读,相信你会有更深刻的体会。

深度学习:基于Keras,使用长短期记忆神经网络模型LSTM和RMSProp优化算法进行销售预测分析
前言 系列专栏:【机器学习:项目实战100+】【2024】✨︎ 在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控循环单元、大型语言模型和强化学习模型 预测是使用过去的值和许多其他因素来预测未来的值。在本文中,我们将使用 Keras

Pytorch常用的函数(八)常见优化器SGD,Adagrad,RMSprop,Adam,AdamW总结
Pytorch常用的函数(八)常见优化器SGD,Adagrad,RMSprop,Adam,AdamW总结 在深度学习中,优化器的目标是通过调整模型的参数,最小化(或最大化)一个损失函数。 优化器使用梯度下降等迭代方法来更新模型的参数,以使损失函数达到最优或接近最优。 如下图,优化算法可分为一阶算法和二阶算法,常用的是一阶算法,今天主要介绍下一阶优化相关的优化器。 1 SGD优化

PyTorch的十个优化器(SGD,ASGD,Rprop,Adagrad,Adadelta,RMSprop,Adam(AMSGrad),Adamax,SparseAdam,LBFGS)
本文截取自《PyTorch 模型训练实用教程》,获取全文pdf请点击:https://github.com/tensor-yu/PyTorch_Tutorial 文章目录 1 torch.optim.SGD 2 torch.optim.ASGD 3 torch.optim.Rprop 4 torch.optim.Adagrad 5 torch.optim.Adadelta 6 torch.op

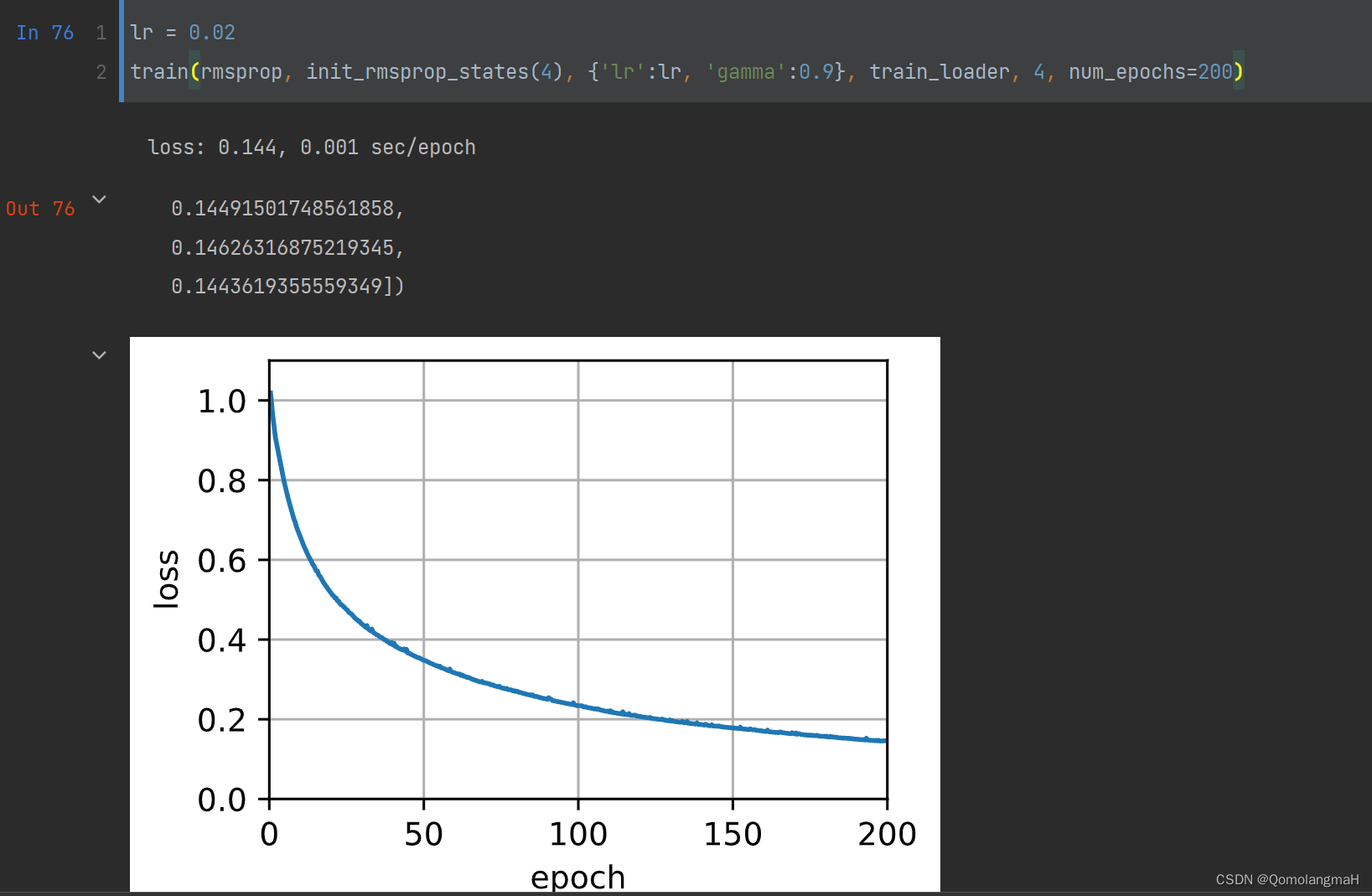
【动手学深度学习】深入浅出深度学习之RMSProp算法的设计与实现
目录 🌞一、实验目的 🌞二、实验准备 🌞三、实验内容 🌼1. 认识RMSProp算法 🌼2. 在optimizer_compare_naive.py中加入RMSProp 🌼3. 在optimizer_compare_mnist.py中加入RMSProp 🌼4. 问题的解决 🌞四、实验心得 🌞一、实验目的 深入学习RMSProp算法的原

sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找 简单logistic分类中的 的应用
参考博文 (4条消息) sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找函数最值的应用_tcuuuqladvvmm454的博客-CSDN博客 在这里随机选择一些数据 生成两类 核心代码如下: def __init__(self, loss,

sgd Momentum Vanilla SGD RMSprop adam等优化算法在寻找函数最值的应用
1\sgd q=q-a*gt a是学习率 gt是函数的梯度 也就是沿着梯度的反方向得到下降最快的,最快能找到函数的最值 2 Momentum 然后q=q-mt 3 RMSprop 4 Adam Adam[6] 可以认为是 RMSprop 和 Momentum 的结合。和 RMSprop 对二阶动量使用指数移动平均类似,Adam 中对一阶动量也是用指

Adagrad求sqrt SGD Momentum Adagrad Adam AdamW RMSProp LAMB Lion 推导
随机梯度下降(Stochastic Gradient Descent)SGD 经典的梯度下降法每次对模型参数更新时,需要遍历所有的训练数据。随机梯度下降法用单个训练样本的损失来近似平均损失。 θ t + 1 = θ t − η g t ( 公式 1 ) \theta_{t+1} = \theta_{t}-\eta g_t (公式1) θt+1=θt−ηgt(公式1) 小批量梯度下降法(

Pytorch-RMSprop算法解析
关注B站可以观看更多实战教学视频:肆十二-的个人空间-肆十二-个人主页-哔哩哔哩视频 (bilibili.com) Hi,兄弟们,这里是肆十二,今天我们来讨论一下深度学习中的RMSprop优化算法。 RMSprop算法是一种用于深度学习模型优化的自适应学习率算法。它通过调整每个参数的学习率来优化模型的训练过程。下面是一个RMSprop算法的用例和参数解析。 用例 假设我们正在训练一个深度学
【深度学习系列】——梯度下降算法的可视化解释(动量,AdaGrad,RMSProp,Adam)!
这是深度学习系列的第二篇文章,欢迎关注原创公众号 【计算机视觉联盟】,第一时间阅读我的原创!回复 【西瓜书手推笔记】 还可获取我的机器学习纯手推笔记! 直达笔记地址:机器学习手推笔记(GitHub地址) 深度学习系列 【深度学习系列】——深度学习简介 笔记预览 在这篇文章中,由于有大量的资源可以解释梯度下降,因此,我想在视觉上引导您了解每种方法的工作原理。借助我构
深度学习记录--RMSprop均方根
RMSprop(root mean square prop) 减缓纵轴方向学习速度,加快横轴方向学习速度,从而加速梯度下降 方法: 原理: 不妨以b为纵轴,w为横轴(横纵轴可能会不同,因为是多维量) 为了让w梯度下降更快,则要使S_dw尽量小,即w每次减去一个大数字,所以w梯度下降更快 为了让b梯度下降更慢,则要使S_db尽量大,即b每次减去一个小数字,所以b梯
【深度学习系列】——梯度下降算法的可视化解释(动量,AdaGrad,RMSProp,Adam)!
这是深度学习系列的第二篇文章,欢迎关注原创公众号 【计算机视觉联盟】,第一时间阅读我的原创!回复 【西瓜书手推笔记】 还可获取我的机器学习纯手推笔记! 直达笔记地址:机器学习手推笔记(GitHub地址) 深度学习系列 【深度学习系列】——深度学习简介 笔记预览 在这篇文章中,由于有大量的资源可以解释梯度下降,因此,我想在视觉上引导您了解每种方法的工作原理。借助我构
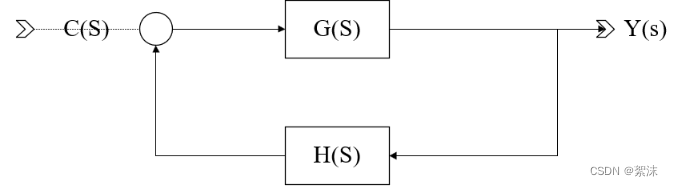
深度学习笔记(六)——网络优化(2):参数更新优化器SGD、SGDM、AdaGrad、RMSProp、Adam
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 在前面的博文中已经学习了构建神经网络的基础需求,搭建了一个简单的双层网络结构来实现数据的分类。并且了解了激活函数和损失函数在神经网络中发挥的重要用途,其中,激活函数优化了神经元的输出能力,损失函数优化了反向传播时参数更新的趋势。 我们知
2020-6-3 吴恩达-改善深层NN-w2 优化算法(2.7 RMSprop -消除梯度下降中的摆动,加速下降,加快学习 -和动量异同点)
1.视频网站:mooc慕课https://mooc.study.163.com/university/deeplearning_ai#/c 2.详细笔记网站(中文):http://www.ai-start.com/dl2017/ 3.github课件+作业+答案:https://github.com/stormstone/deeplearning.ai 2.7 RMSprop RMSprop的
![[work] 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam](https://img-blog.csdn.net/20170806001149509?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMDA4OTQ0NA==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[work] 优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
1. SGD Batch Gradient Descent 在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新: Θ=Θ−α⋅▿ΘJ(Θ)Θ=Θ−α⋅▽ΘJ(Θ) 优点: cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值 缺点
【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momentum4. 自适应学习率Adagrad算法Adadelta算法RMSprop算法算法测试 5.
几种优化算法的比较(BGD、SGD、Adam、RMSPROP)
1、BGD(Batch gradient descent) 梯度更新规则:BGD 采用整个训练集的数据来计算 cost function 对参数的梯度: 缺点:由于这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,遇到很大量的数据集也会非常棘手,而且不能投入新数据实时更新模型。 我们会事先定义一个迭代次数 epoch,首先计算梯度向量 params_grad,然后沿着梯

Tensorflow入门教程(三十三)优化器算法简介(Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
# #作者:韦访 #博客:https://blog.csdn.net/rookie_wei #微信:1007895847 #添加微信的备注一下是CSDN的 #欢迎大家一起学习 # ------韦访 20181227 1、概述 上一讲中,我们发现,虽然都是梯度下降法,但是不同算法之间还是有区别的,所以,这一讲,我们就来看看它们有什么不同。 2、梯度下降常用的三种方法 为了博客的完整性,这里

深度学习笔记之优化算法(六)RMSprop算法的简单认识
深度学习笔记之优化算法——RMSProp算法的简单认识 引言回顾:AdaGrad算法AdaGrad算法与动量法的优化方式区别AdaGrad算法的缺陷 RMProp算法关于AdaGrad问题的优化方式RMSProp的算法过程描述 RMSProp示例代码 引言 上一节对 AdaGrad \text{AdaGrad} AdaGrad算法进行了简单认识,本节将介绍 RMSProp \t