qwen1.5专题

基于SWIFT和Qwen1.5-14B-Chat进行大模型LoRA微调测试
基于SWIFT和Qwen1.5-14B-Chat进行大模型LoRA微调测试 环境准备 基础环境 操作系统:Ubuntu 18.04.5 LTS (GNU/Linux 3.10.0-1127.el7.x86_64 x86_64)Anaconda3:Anaconda3-2023.03-1-Linux-x86_64根据服务器网络情况配置好conda源和pip源,此处使用的是超算山河源服务器硬件配置
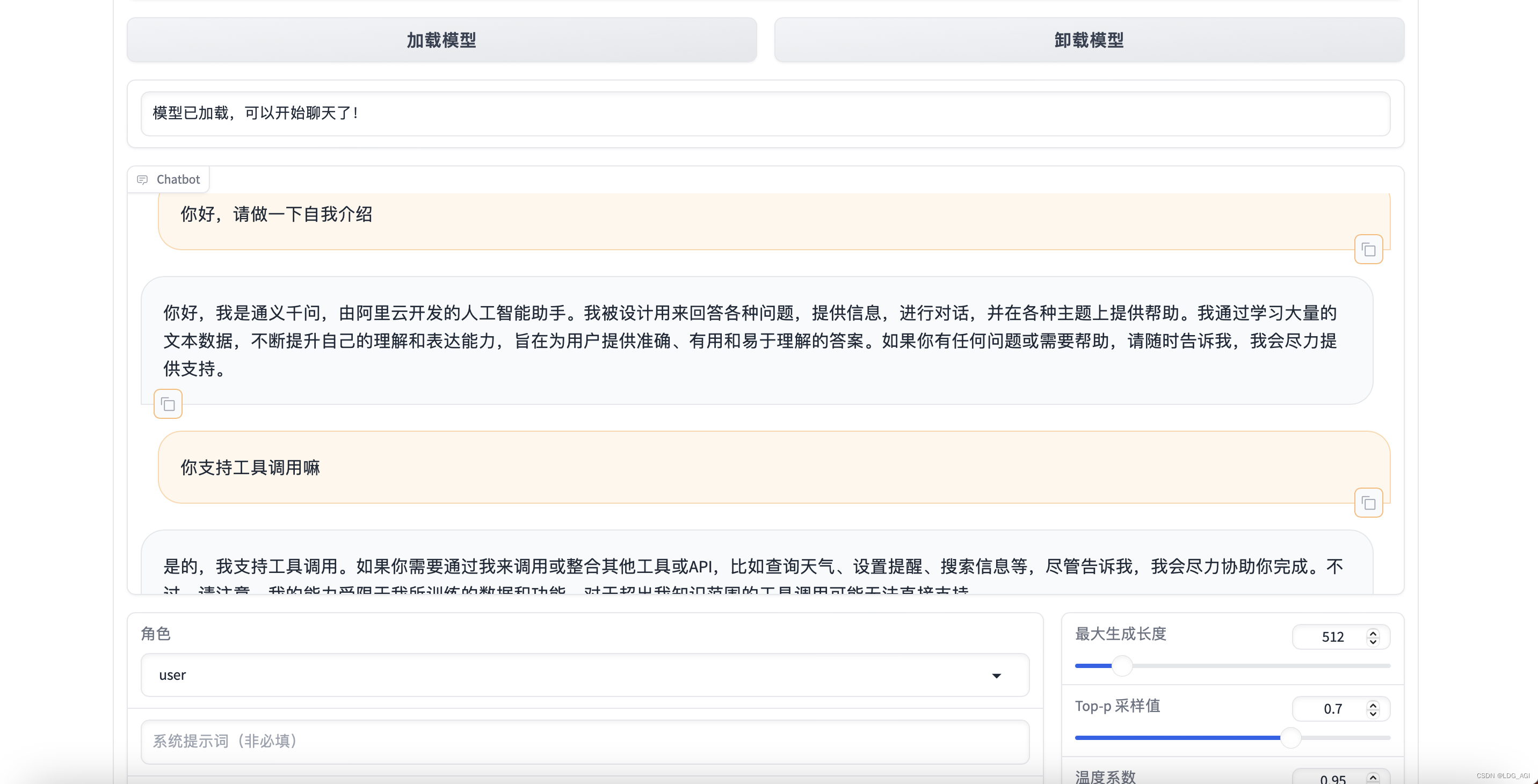
【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
目录 一、引言 二、模型简介 2.1 Qwen1.5 模型概述 2.2 Qwen1.5 模型架构 三、训练与推理 3.1 Qwen1.5 模型训练 3.2 Qwen1.5 模型推理 四、总结 一、引言 Qwen是阿里巴巴集团Qwen团队的大语言模型和多模态大模型系列。现在,大语言模型已升级到Qwen1.5,共计开源0.5B、1.8B、4B、7B、14B、32B、72B、

零一万物Yi-1.5开源,34B/9B/6B多尺寸,34B超Qwen1.5-72B
前言 近年来,大型语言模型(LLM)在各个领域展现出惊人的能力,为人们的生活和工作带来了巨大的改变。然而,大多数开源 LLM 的性能仍然无法与闭源模型相媲美,这限制了 LLM 在科研和商业领域的进一步应用。为了推动 LLM 的开源发展,零一万物团队推出了全新一代的开源语言模型——Yi-1.5,并提供 34B/9B/6B 三种不同尺寸,旨在为研究人员和开发者提供更多选择,助力 LLM 的发展与应用
![如何使用 Hugging Face 的 Transformers 库来下载并使用一个qwen1.5的预训练模型[框架]](/front/images/it_default2.jpg)
如何使用 Hugging Face 的 Transformers 库来下载并使用一个qwen1.5的预训练模型[框架]
要使用Hugging Face的Transformers库下载并使用Qwen1.5预训练模型,你可以按照以下步骤操作: 1.安装Transformers库: 确保你已经安装了transformers库的最新版本,至少是4.37.0,因为Qwen1.5已经被集成到这个版本中。如果还没有安装,可以使用以下命令安装: pip install transformers 2.导入必要的模块: 在P
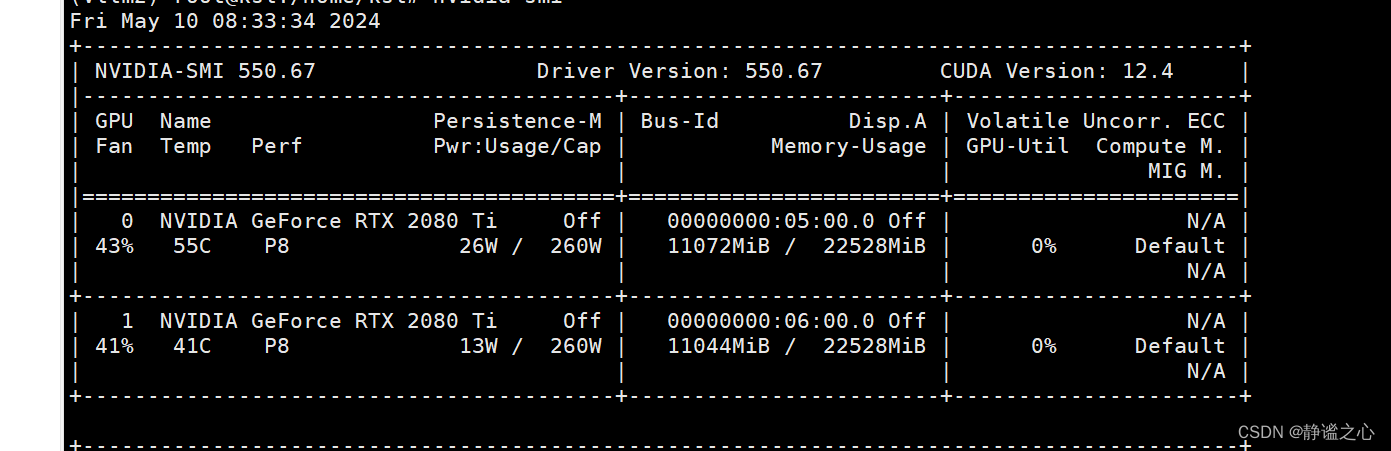
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速
首先先搞清各主要组件的名称与作用: FastChat FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是: 提供SOTA模型的训练和评估代码 提供分布式多模型部署框架 + WebUI + OpenAI API Controller管理分布式模型实例 Model Worker是大模型服务实例,它在启动时向Controller注册 OpenAI API提供OpenAI兼容的A
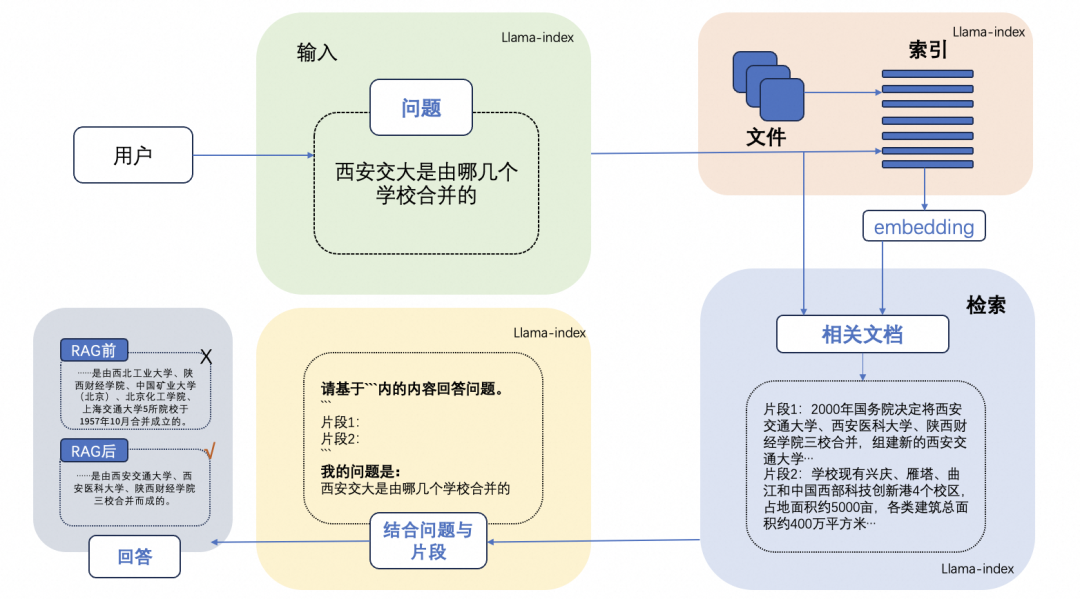
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统 什么是 RAG LLM 会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。 正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为 AI 时代的一大趋势。RAG 通过
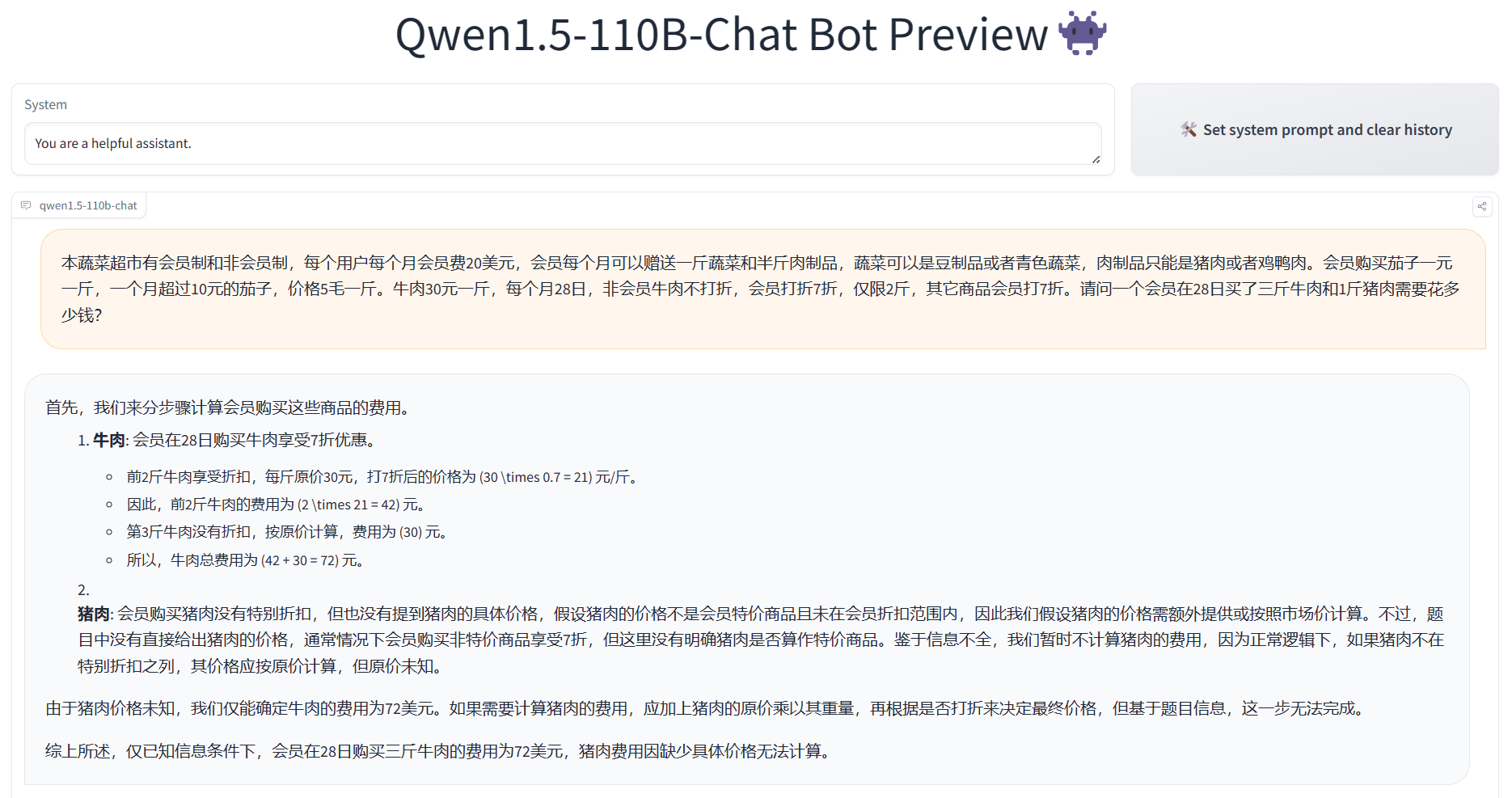
阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B!
本文原文来自DataLearnerAI官方网站:阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051714140775766 Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为

开源模型应用落地-LangChain高阶-集成vllm-QWen1.5-OpenAI-Compatible Server(三)
一、前言 通过langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。vLLM可以部署为类似于OpenAI API协议的服务器,允许用户使用OpenAI API进行模型推理。 相关文章: 开源模型应用落地-LangChain试炼-CPU调用QWen1.5(一) 开源模型应用落地-LangChain高阶-GPU调用
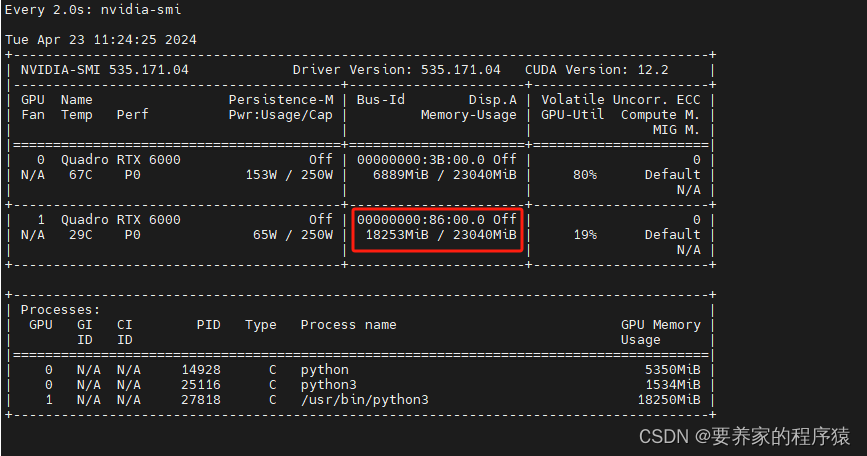
开源模型应用落地-LangChain高阶-集成vllm-QWen1.5(一)
一、前言 通过langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。vLLM是一个快速且易于使用的LLM推理和服务库。通过两者的结合,可以更好地处理对话,提供更智能、更准确的响应,从而提高对话系统的性能和用户体验。 二、术语 2.1.LangChain 是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangCha

利用ollama和open-webui本地部署通义千问Qwen1.5-7B-Chat模型
目录 1 安装ollama 2 安装open-webui 2.1 镜像下载 3 配置ollama的模型转换工具环境 3.1 下载ollama源码 3.2 下载ollama子模块 3.3 创建ollama虚拟环境 3.4 安装依赖 3.5 编译量化工具 7 创建ollama模型 8 运行模型 参考文献: 1 安装ollama curl -fsSL ht
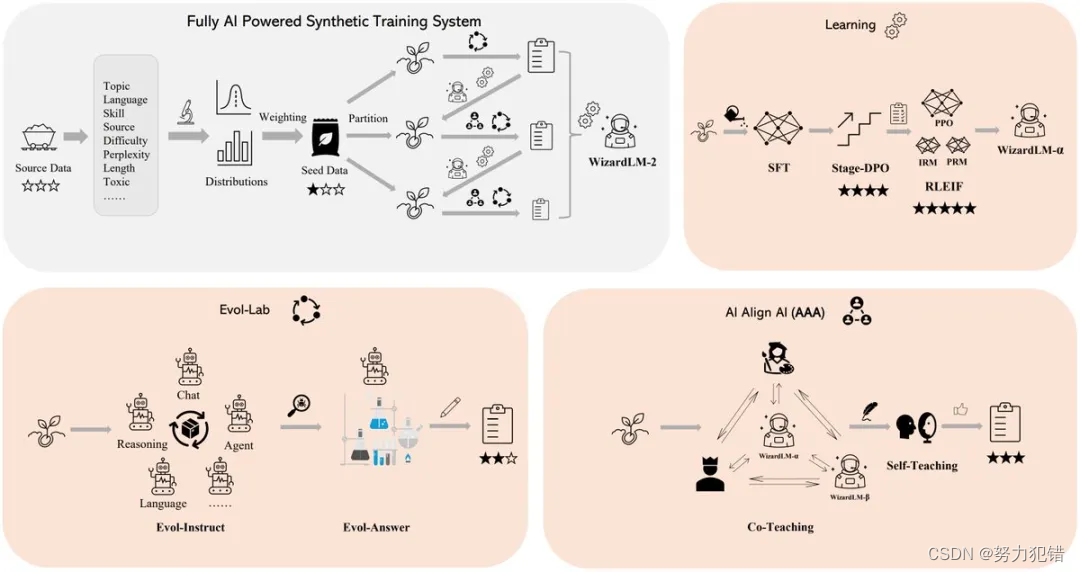
微软刚开源就删库的WizardLM-2:MT-Bench 榜单评测超越GPT-4,7B追平Qwen1.5-32B
前言 微软最近发布的WizardLM-2大型语言模型因其先进的技术规格和短暂的开源后突然撤回,引起了科技界的广泛关注。WizardLM-2包括三个不同规模的模型,分别是8x22B、70B和7B,均展现了在多语言处理、复杂对话、推理和代理任务上的卓越能力。 Huggingface模型下载:https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GG
Qwen1.5大语言模型微调实践
在人工智能领域,大语言模型(Large Language Model,LLM)的兴起和广泛应用,为自然语言处理(NLP)带来了前所未有的变革。Qwen1.5大语言模型作为其中的佼佼者,不仅拥有强大的语言生成和理解能力,而且能够通过微调(fine-tuning)来适应各种特定场景和任务。本文将带领大家深入实战,探索如何对Qwen大语言模型进行微调,以满足实际应用的需求。 一、了解Qwen1.5
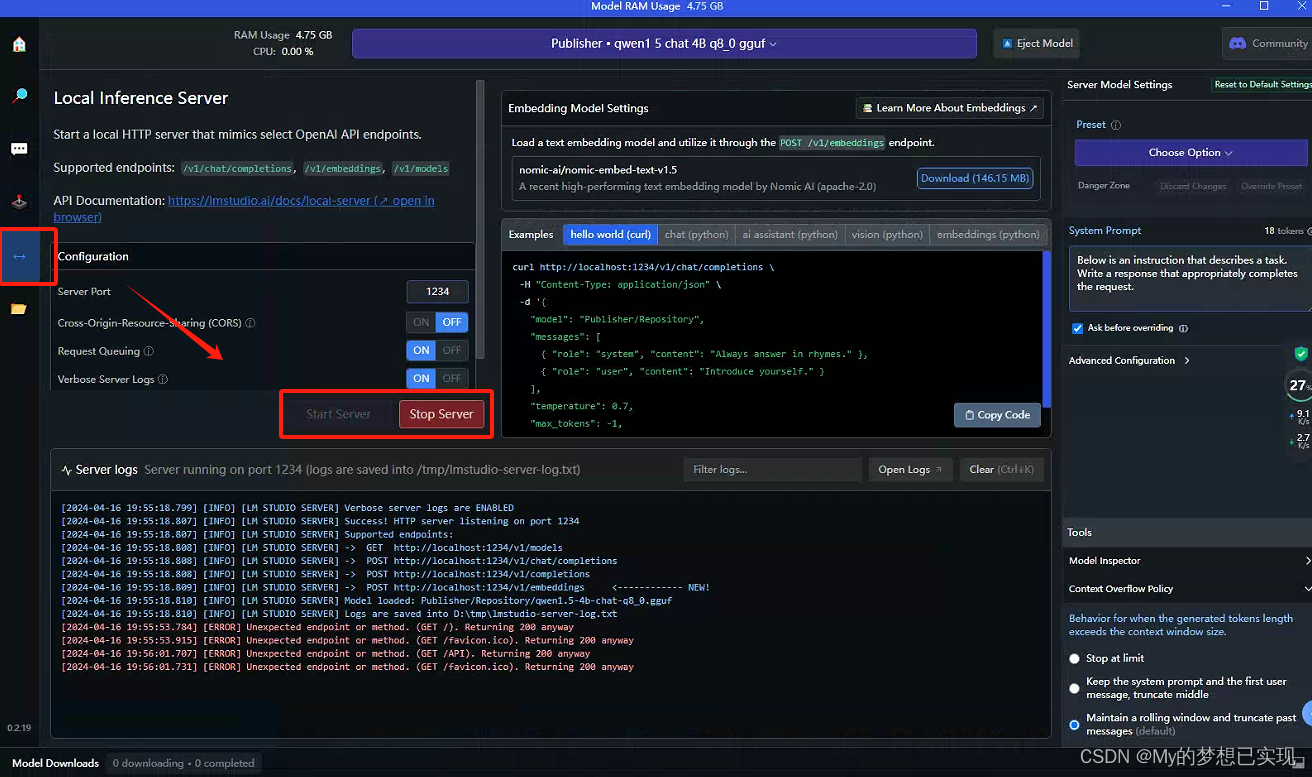
【AI开发:语言】二、Qwen1.5-7B模型本地部署CPU和GPU版
前言 之前文章,我们采用了Koblod运行Yi-34B大模型,本文采用LM Studio来运行千问模型。 LM Studio并没有开源,但是可以免费使用,他是目前本地进行模型测试最好的工具了。 在这里,依然使用Windows 10进行部署和测试,没有GPU。 注意:LM的运行速度相比较Kobold两者差不多,而且也提供WEB服务,稍后也研究下

开源模型应用落地-LangChain高阶-GPU调用QWen1.5(二)
一、前言 通过langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。langchain会自动将任务分解为多个子任务,并将它们传递给适合的语言模型进行处理。 本篇将通过LangChain调用QWen1.5模型实现多轮对话场景 基础调用方式请参考:开源模型应用落地-LangChain试炼-CPU调用QWen1.5(一)
![[大模型]Qwen1.5-4B-Chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/3d5a75cd6f444f10a3132c442ba19ebb.png#pic_center)
[大模型]Qwen1.5-4B-Chat WebDemo 部署
Qwen1.5-4B-Chat WebDemo 部署 Qwen1.5 介绍 Qwen1.5 是 Qwen2 的测试版,Qwen1.5 是基于 transformer 的 decoder-only 语言模型,已在大量数据上进行了预训练。与之前发布的 Qwen 相比,Qwen1.5 的改进包括 6 种模型大小,包括 0.5B、1.8B、4B、7B、14B 和 72B;Chat模型在人类偏好方面的性
通义千问Qwen1.5(Beta Version of Qwen2)代码理解
Qwen1.5的代码已经集成到了transformers>=4.37.0中,下面是对Qwen1.5代码初步阅读后的理解 位置编码:RotaryEmbedding decoder中的FFN(实现类Qwen2MLP):激活函数使用了GLU的变体SiLU(Swish)激活函数 注意力层: 注意力机制有三种实现方式——手动实现、基于FlashAttention2、基于SDPA(torch.nn.f
![[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境](https://img-blog.csdnimg.cn/direct/b8c9ed143e85437fbbad7832cc8b3b8a.png#pic_center)
[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境
Qwen1.5-7B-Chat-GPTQ-Int4 部署环境 说明 Qwen1.5-72b 版本有BF16、INT8、INT4三个版本,三个版本性能接近。由于BF16版本需要144GB的显存,让普通用户忘却止步,而INT4版本只需要48GB即可推理,给普通用户本地化部署创造了机会。(建议使用4×24G显存的机器) 但由于Qwen1.5-72B-Chat-GPTQ-Int4其使用了GPTQ量化

阿里Qwen1.5-32B开源,评测超Mixtral MoE,挑战SOTA性价比
前言 阿里巴巴近日震撼开源其最新力作——Qwen1.5-32B大语言模型。在当前AI领域,大模型的开发与应用已成为评估技术进步的重要标尺。Qwen1.5-32B的问世,不仅再次证明了阿里在AI技术研发领域的深厚实力,更是在性能与成本之间找到了一个新的平衡点。 Qwen1.5-32B模型简介 Qwen1.5-32B继承了Qwen系列模型的卓越传统,拥有320亿参数,是在Qwen1.5系列中规模
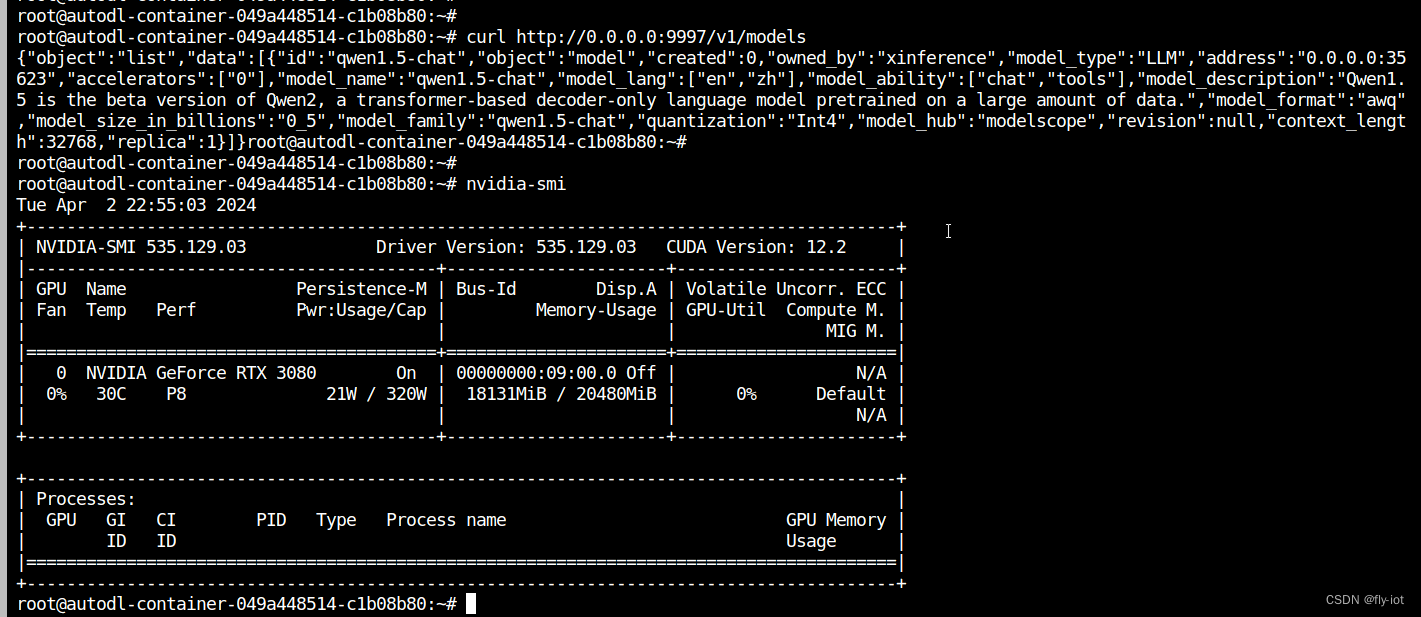
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
1,关于xinference Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(
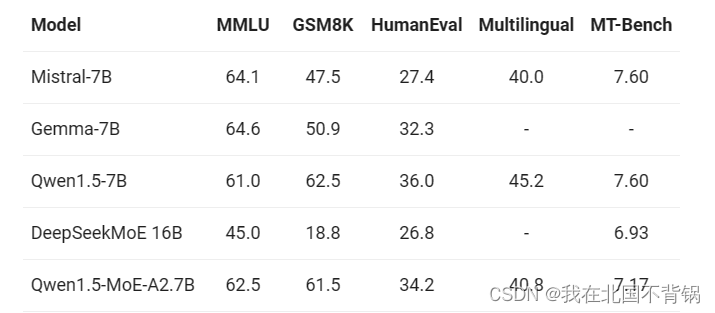
阿里通义千问Qwen1.5开源MoE模型
介绍 2024年3月28日,阿里团队推出了Qwen系列的首个MoE模型,Qwen1.5-MoE-A2.7B。它仅拥有27亿个激活参数,但其性能却能与当前最先进的70亿参数模型,如Mistral 7B和Qwen1.5-7B相媲美。相较于包含65亿个Non-Embedding参数的Qwen1.5-7B,Qwen1.5-MoE-A2.7B只有20亿个Non-Embedding参数,约为原模型大小的三分
开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
一、前言 预训练模型提供的是通用能力,对于某些特定领域的问题可能不够擅长,通过微调可以让模型更适应这些特定领域的需求,让它更擅长解决具体的问题。 本篇是开源模型应用落地-qwen-7b-chat-LoRA微调(一)进阶篇,学习通义千问最新1.5系列模型的微调方式。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank A

【RAG实践】基于 LlamaIndex 和Qwen1.5搭建基于本地知识库的问答机器人
什么是RAG LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。 正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为 AI 时代的一大趋势。 RAG 通过在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程

集简云新增通义千问qwen 72b chat、qwen1.5 等多种大语言模型,提升多语言支持能力
通义千问再开源!继发布多模态模型后,通义千问 1.5 版本也在春节前上线。 此次大模型包括六个型号:0.5B、1.8B、4B、7B、14B 和 72B,性能评测基础能力在在语言理解、代码生成、推理能力等多项基准测试中均展现出优异的性能,且支持多语言。 为了满足用户对多种AI模型的需求,快速体验到更加强大和多样化的AI能力,集简云目前已将以下应用模型快速接入到平台内,您可在通义千问模型开源版(原
通义千问1.5(Qwen1.5)大语言模型在PAI-QuickStart的微调与部署实践
作者:汪诚愚(熊兮)、高一鸿(子洪)、黄俊(临在) Qwen1.5(通义千问1.5)是阿里云最近推出的开源大型语言模型系列。作为“通义千问”1.0系列的进阶版,该模型推出了多个规模,从0.5B到72B,满足不同的计算需求。此外,该系列模型还包括了Base和Chat等多个版本的开源模型,为全球的开发者社区提供了空前的便捷性。阿里云的人工智能平台PAI,作为一站式的机器学习和深度学习平台,对Qwen
开源模型应用落地-qwen1.5-7b-chat与vllm实现推理加速的正确姿势(八)
一、前言 就在前几天开源社区又发布了qwen1.5版本,它是qwen2模型的测试版本。在本篇学习中,将集成vllm实现模型推理加速,现在,我们赶紧跟上技术发展的脚步,去体验一下新版本模型的推理质量。 二、术语 2.1. vLLM vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFac