本文主要是介绍微软刚开源就删库的WizardLM-2:MT-Bench 榜单评测超越GPT-4,7B追平Qwen1.5-32B,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
微软最近发布的WizardLM-2大型语言模型因其先进的技术规格和短暂的开源后突然撤回,引起了科技界的广泛关注。WizardLM-2包括三个不同规模的模型,分别是8x22B、70B和7B,均展现了在多语言处理、复杂对话、推理和代理任务上的卓越能力。
-
Huggingface模型下载:https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF
-
AI快站模型免费加速下载:https://aifasthub.com/models/MaziyarPanahi

模型性能和架构
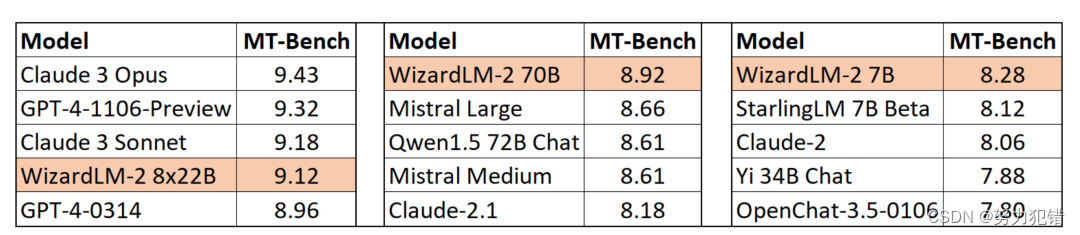
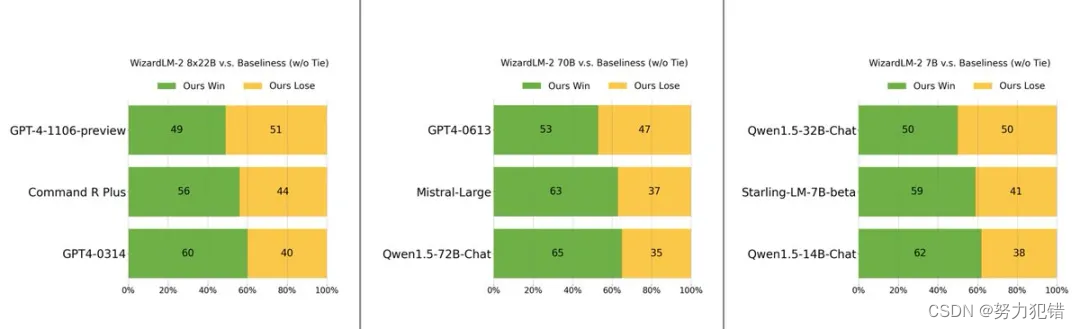
WizardLM-2系列模型在多个基准测试中表现出色。其中,7B版本在基准任务上与Qwen1.5-32B相当;70B版本超过了同类的GPT-4-0613;最高规格的8x22B版本则在MT-Bench上取得了9.12的高分,超越了所有现有的GPT-4版本。这些成绩彰显了微软在模型优化和多任务处理技术上的领先地位。
独特的训练方法
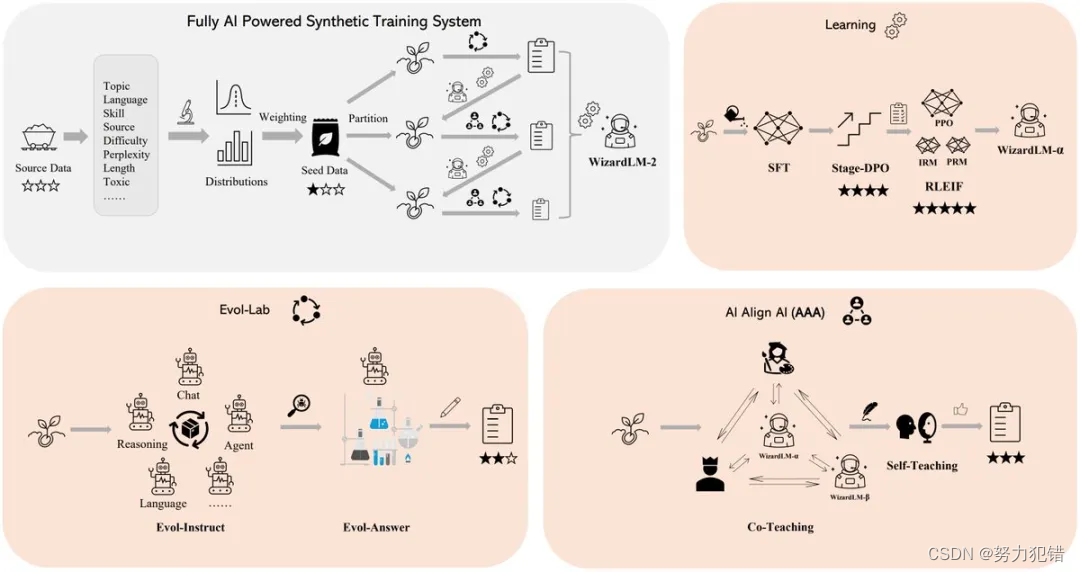
WizardLM-2的训练方法体现了多个创新点:
-
加权抽样和数据预处理: 微软通过分析数据源中不同属性的分布情况,并通过加权抽样调整训练数据中各属性的权重,使得最终的数据集更符合实际应用场景的需要。
-
渐进式学习: 与传统的全量数据训练不同,微软采用渐进式学习方法,通过逐步增加训练数据的复杂性,使模型能在较少的数据中学到更有效的信息。
-
Evol Lab和AI Align AI: 这一框架允许多个最先进的语言模型相互教学和改进。Evol-Instruct和Evol-Answer的方法使模型能自动生成高质量的指令并优化响应。
训练阶段的详细创新
-
Evol-Instruct和Evol-Answer: 这两种方法通过重新设计和评估指令生成过程,增强了模型生成指令的质量和响应的相关性。
-
监督学习与强化学习的结合使用: 通过结合使用监督学习和强化学习,微软优化了模型的学习过程。特别是,通过Stage-DPO和RLEIF技术,模型能在离线和在线环境下进行更为精确的学习和优化。
撤回原因与未来展望
尽管WizardLM-2在技术上取得了显著进展,但微软因忘记进行毒性测试而短暂撤回了模型。这一事件突显了在开发和部署前对AI模型进行全面测试的重要性,确保技术的安全性和可靠性。
结论
WizardLM-2的开发和短暂撤回事件虽然带来了一定的争议,但也展示了微软在人工智能领域的强大实力和对高标准的承诺。预计在完成必要的测试和优化后,这些模型将为AI研究和应用带来新的可能性,特别是在处理多语言和复杂交互任务方面。微软的这一步也可能推动整个行业向更开放、更安全的AI应用方向迈进。
模型下载
Huggingface模型下载
https://huggingface.co/MaziyarPanahi/WizardLM-2-7B-GGUF
AI快站模型免费加速下载
https://aifasthub.com/models/MaziyarPanahi
这篇关于微软刚开源就删库的WizardLM-2:MT-Bench 榜单评测超越GPT-4,7B追平Qwen1.5-32B的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!