pyflink专题

pyflink的窗口
PyFlink 中的窗口操作教程 在流处理应用中,窗口(Window)是一个非常重要的概念,它用于对无界的数据流进行切分,使得我们可以对流中的数据执行聚合、计数、排序等操作。PyFlink 提供了丰富的窗口类型和操作,可以对流数据进行时间和计数等维度的切片,进行实时的数据处理。 在本教程中,我们将介绍 PyFlink 中的几种常见窗口类型,并展示如何使用窗口进行数据处理。 1. 安装 PyF

pyflink中UDTF和UDF的区别
UDTF(User Defined Table-Valued Functions)和UDF(User Defined Functions)在Flink和其他数据处理系统中有着明显的区别,主要体现在以下几个方面: 输出类型: UDF: UDF是用户定义的标量函数。它接收一个或多个标量值作为输入,并返回一个标量值作为输出。 UDTF: UDTF是用户定义的表值函数。它接收一个或多个标量值作为输入,
0基础学习PyFlink——使用datagen生成流式数据
大纲 可控参数字段级规则生成方式数值控制时间戳控制 表级规则生成速度生成总量 结构生成环境定义行结构定义表信息 案例随机Int型顺序Int型随机型Int数组带时间戳的多列数据 完整代码参考资料 在研究Flink的水位线(WaterMark)技术之前,我们可能需要Flink接收到流式数据,比如接入Kafka等。这就要求引入其他组件,增加了学习的难度。而Flink自身提供了data
0基础学习PyFlink——使用datagen生成流式数据
大纲 可控参数字段级规则生成方式数值控制时间戳控制 表级规则生成速度生成总量 结构生成环境定义行结构定义表信息 案例随机Int型顺序Int型随机型Int数组带时间戳的多列数据 完整代码参考资料 在研究Flink的水印(WaterMark)技术之前,我们可能需要Flink接收到流式数据,比如接入Kafka等。这就要求引入其他组件,增加了学习的难度。而Flink自身提供了datag
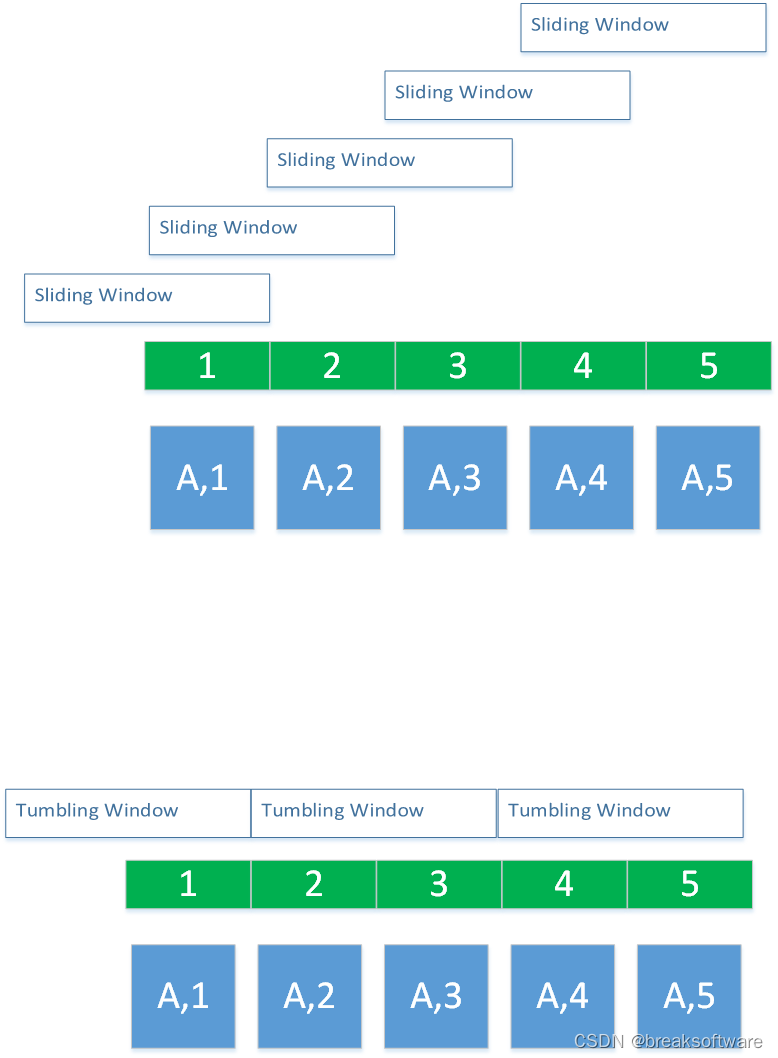
0基础学习PyFlink——事件时间和运行时间的窗口
大纲 定制策略运行策略Reduce完整代码滑动窗口案例参考资料 在 《0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)》一文中,我们使用的是运行时间(Tumbling ProcessingTimeWindows)作为窗口的参考时间: reduced=keyed.window(TumblingProcessingTimeWindo
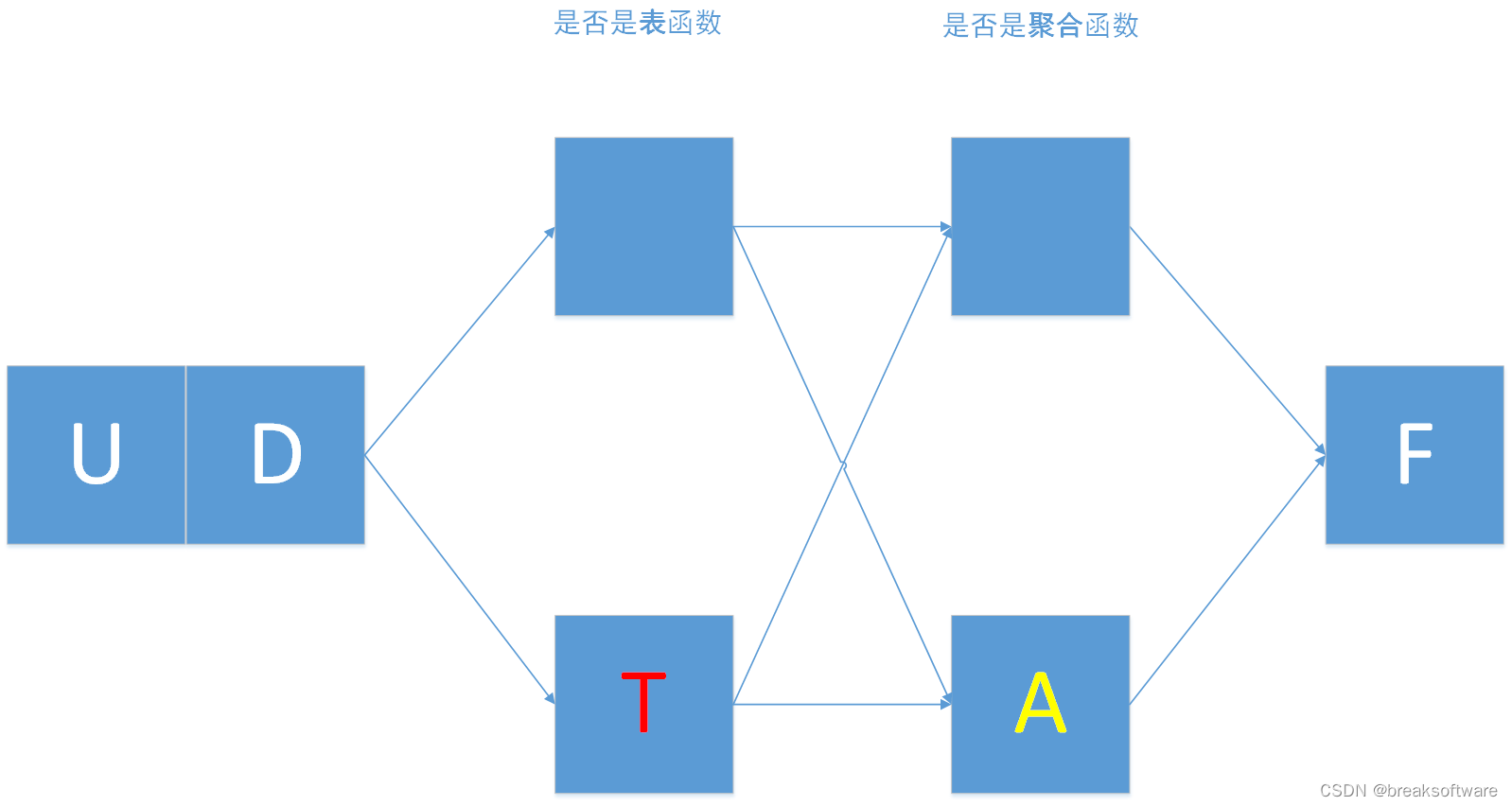
0基础学习PyFlink——用户自定义函数之UDF
大纲 标量函数入参并非表中一行(Row)入参是表中一行(Row)alias PyFlink中关于用户定义方法有: UDF:用户自定义函数。UDTF:用户自定义表值函数。UDAF:用户自定义聚合函数。UDTAF:用户自定义表值聚合函数。 这些字母可以拆解如下: UD表示User Defined(用户自定义);F表示Function(方法);T表示Table(表);A表示Ag

0基础学习PyFlink——用户自定义函数之UDTAF
大纲 UDTAFTableAggregateFunction的实现累加器定义创建累加 返回类型计算 完整代码 在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。 UDTAF UDTAF函数即具备了UDTF的特点,也具备UDAF的特点。即它可以像《0基础学习PyFlink——用户自
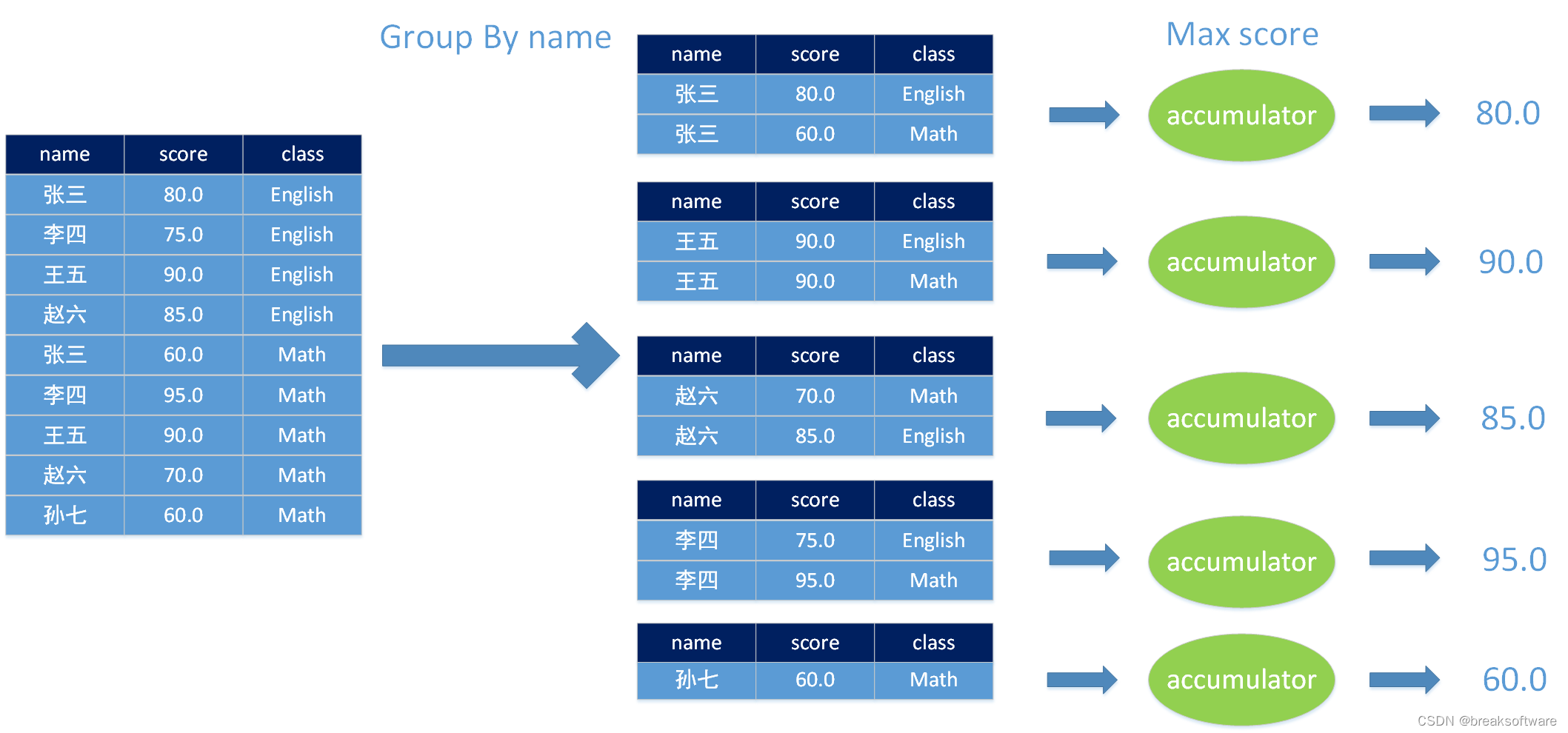
0基础学习PyFlink——用户自定义函数之UDAF
大纲 UDAF入参并非表中一行(Row)的集合计算每个人考了几门课计算每门课有几个人考试计算每个人的平均分计算每课的平均分计算每个人的最高分和最低分 入参是表中一行(Row)的集合计算每个人的最高分、最低分以及所属的课程计算每课的最高分数、最低分数以及所属人 完整代码入参并非表中一行(Row)的集合入参是表中一行(Row)的集合 在前面几篇文章中,我们学习了非聚合类的用户自定义
0基础学习PyFlink——用户自定义函数之UDTAF
大纲 UDTAFTableAggregateFunction的实现累加器定义创建累加 返回类型计算 完整代码 在前面几篇文章中,我们分别介绍了UDF、UDTF和UDAF这三种用户自定义函数。本节我们将介绍最后一种函数:UDTAF——用户自定义表值聚合函数。 UDTAF UDTAF函数即具备了UDTF的特点,也具备UDAF的特点。即它可以像《0基础学习PyFlink——用户自
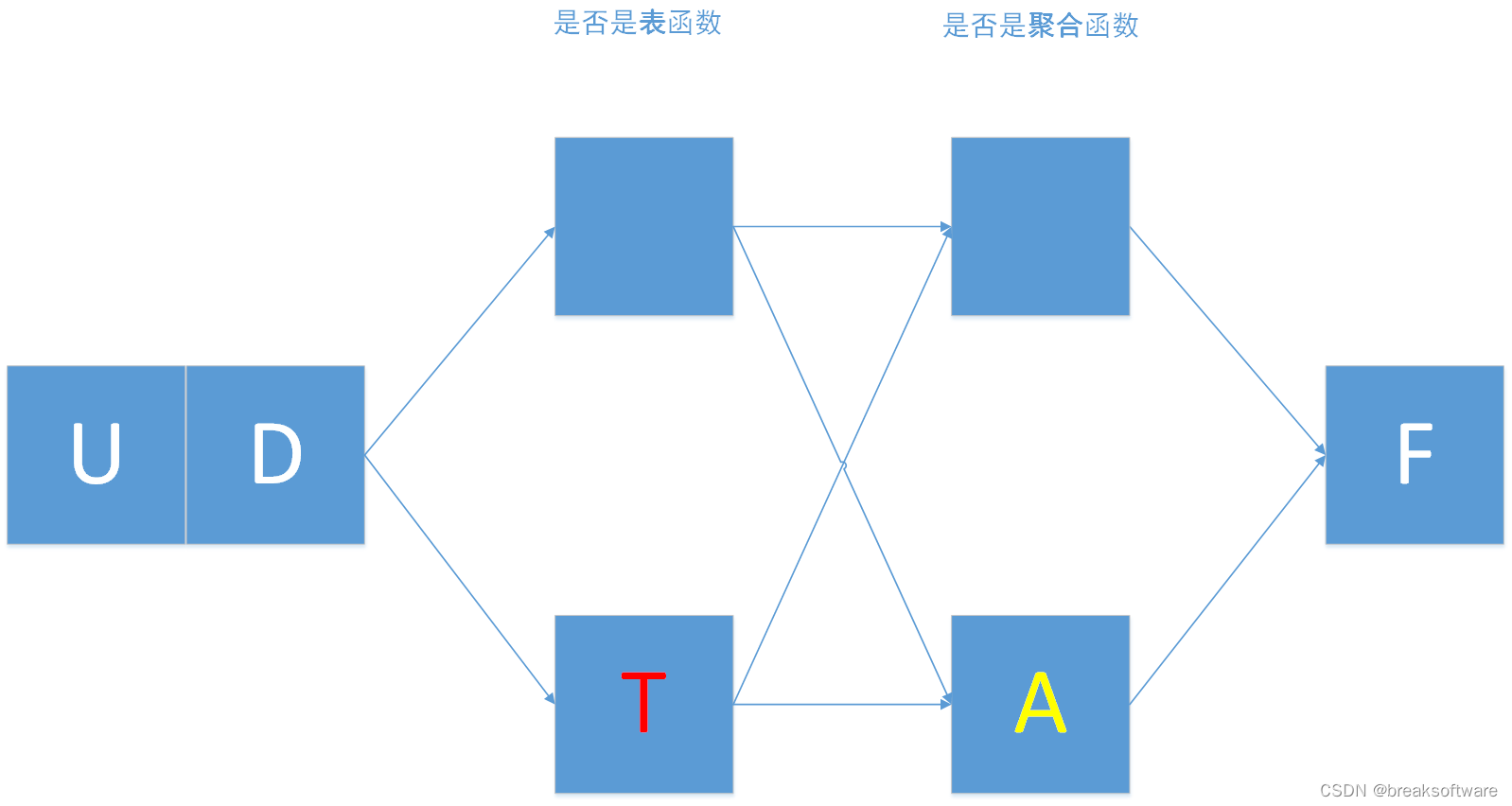
0基础学习PyFlink——用户自定义函数之UDTF
大纲 表值函数完整代码 在《0基础学习PyFlink——用户自定义函数之UDF》中,我们讲解了UDF。本节我们将讲解表值函数——UDTF 表值函数 我们对比下UDF和UDTF def udf(f: Union[Callable, ScalarFunction, Type] = None,input_types: Union[List[DataType], DataType,
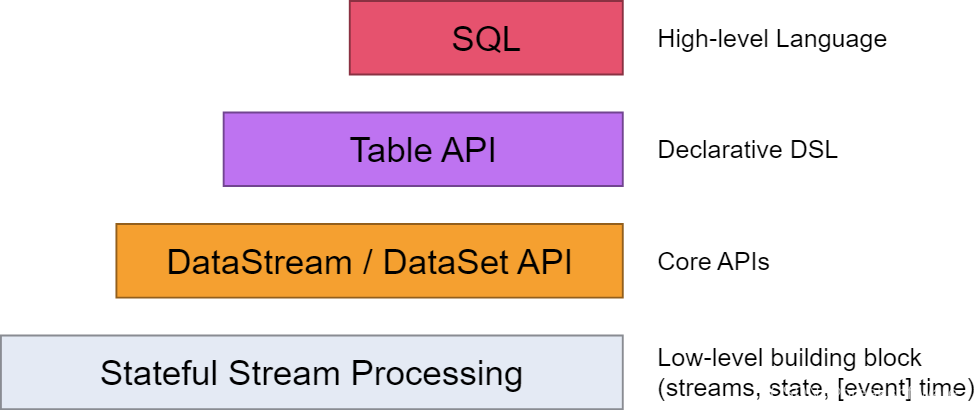
0基础学习PyFlink——使用Table API实现SQL功能
在《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。 如下图所示SQL是最高层级的抽象,在它之下是Table API。本文我们会将例子中的SQL翻译成Table API来实现等价的功能。 Souce # """create table sour
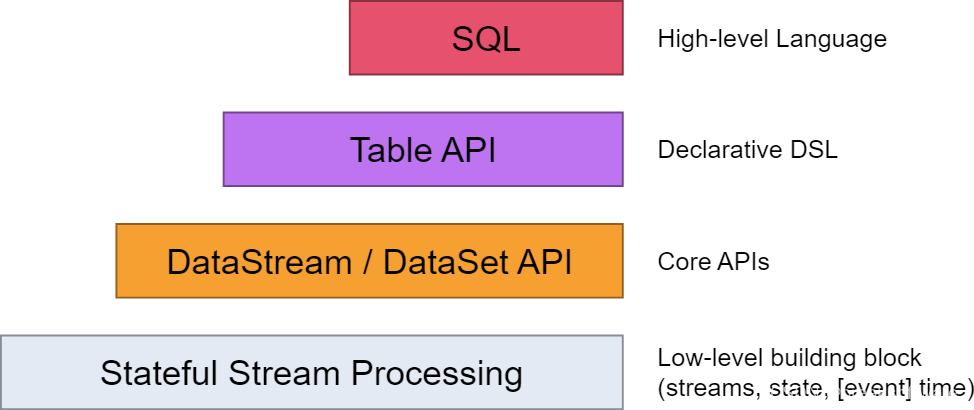
0基础学习PyFlink——使用Table API实现SQL功能
在《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。 如下图所示SQL是最高层级的抽象,在它之下是Table API。本文我们会将例子中的SQL翻译成Table API来实现等价的功能。 Souce # """create table sour
0基础学习PyFlink——使用PyFlink的SQL进行字数统计
在《0基础学习PyFlink——Map和Reduce函数处理单词统计》和《0基础学习PyFlink——模拟Hadoop流程》这两篇文章中,我们使用了Python基础函数实现了字(符)统计的功能。这篇我们将切入PyFlink,使用这个框架实现字数统计功能。 PyFlink安装 安装Python sudo apt install python3.10sudo ln -s /usr/bin/py
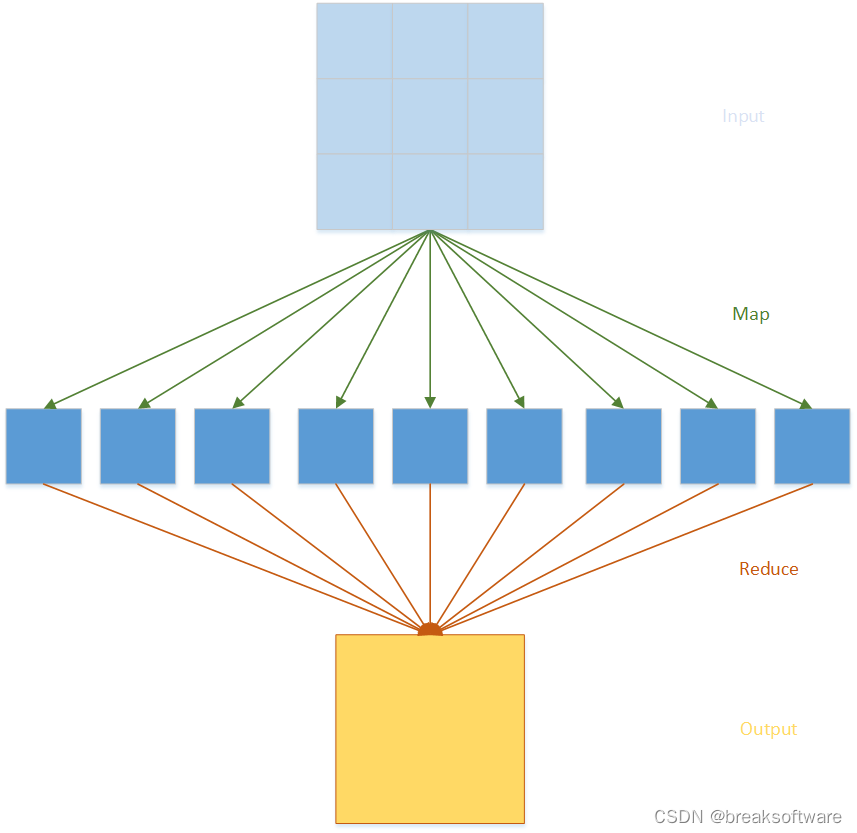
0基础学习PyFlink——Map和Reduce函数处理单词统计
在很多讲解大数据的案例中,往往都会以一个单词统计例子来抛砖引玉。本文也不免俗,例子来源于PyFlink的《Table API Tutorial》,我们会通过几种方式统计不同的单词出现的个数,从而达到循序渐进的学习效果。 常规方法 # input.pyword_count_data = ["To be, or not to be,--that is the question:--","Whet
pyflink读取kafka数据写入mysql实例
依赖包下载 https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.17.1/ 版本 flink:1.16.0 kafka:2.13-3.2.0 实例 import loggingimport sysfrom pyflink.common import Typesfrom p