parquet专题

Flink读取kafka数据并以parquet格式写入HDFS
《2021年最新版大数据面试题全面开启更新》 《2021年最新版大数据面试题全面开启更新》 大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中; 目前基于spark进行计算比较主流,需要读取hdfs上的数据,可以通过读取parquet:spark.read

Hive扩展功能(一)--Parquet
软件环境: linux系统: CentOS6.7Hadoop版本: 2.6.5zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这三部机, 每部主机的用户名都为centos 192.168.179.201: m1 192.168.179.202: m2 192.168.179.203: m3 m1: Zookeeper, Namenode, DataNod

Parquet文件存储格式详细解析
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 大数据真好玩 点击右侧关注,大数据真好玩! 猜你想要的: Hive - ORC 文件存储格式详细解析 一、Parquet的组成 Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定,目前能够和Parquet适配的组件包括下面这

parquet-tools工具使用和源码依赖包编译
1. wesleypeck编写的开源parquet-tools parquet-tools出现org/apache/hadoop/conf/Configuration问题的解决 该版本由于原作者不在进行更新,目前网上能够找到的版本大部分无法使用,原因在于源码中pom.xml并没有引入对应hadoop-core的依赖,导致jar包在执行对应命令时会报错: NoClassDefFoundErr
TEXTFILE 和 PARQUET 的区别
TEXTFILE 和 PARQUET 的区别 1. 文件格式 TEXTFILE: 行式存储格式人类可读的纯文本文件每行代表一条记录,字段由分隔符(如逗号、制表符)分隔 PARQUET: 列式存储格式二进制文件,不是人类直接可读的数据按列组织,而不是按行 2. 存储效率 TEXTFILE: 存储效率较低,特别是对于大量数据不提供内置压缩,虽然可以使用外部压缩(如 gzip) PAR

python读取parquet文件并打印内容
要打印 Parquet 文件前五行的所有列信息,并尽可能详细地展示每一列的数据类型和内容,可以使用 pandas 库。以下是一个示例代码,展示如何读取 Parquet 文件并打印前五行的详细信息: 首先,确保你已经安装了 pandas和 pyarrow 库。如果没有安装,可以使用以下命令进行安装: pip install pandas pyarrow 然后,使用以下代码读取并打印Parquet文件

Petastorm库--在pytorch中使用读取parquet格式
Petastorm是一个库,支持使用来自Tensorflow、Pytorch和其他基于python的ML培训框架的拼板存储。 Petastorm是Uber ATG开发的一个开源数据访问库。这个库支持从Apache Parquet格式的数据集直接对单个机器或分布式的深度学习模型进行训练和评估。Petastorm支持流行的基于python的机器学习(ML)框架,如Tensorflow、PyTorch

parquet学习总结
深入分析Parquet列式存储格式 Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0。 列式存储 列式存储和行式存储相比有哪些优势呢? 1.可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。 2.压缩编码可以降低磁盘存储空间。由于同一列的数据类型是
再来聊一聊 Parquet 列式存储格式
Parquet 是 Hadoop 生态圈中主流的列式存储格式,最早是由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 孵化器里毕业成为 Apache 顶级项目。 有这样一句话流传:如果说 HDFS 是大数据时代文件系统的事实标准,Parquet 就是大数据时代存储格式的事实标准。 01 整体介绍 先简单介绍下: Parquet 是一种支持嵌套结构的列式存
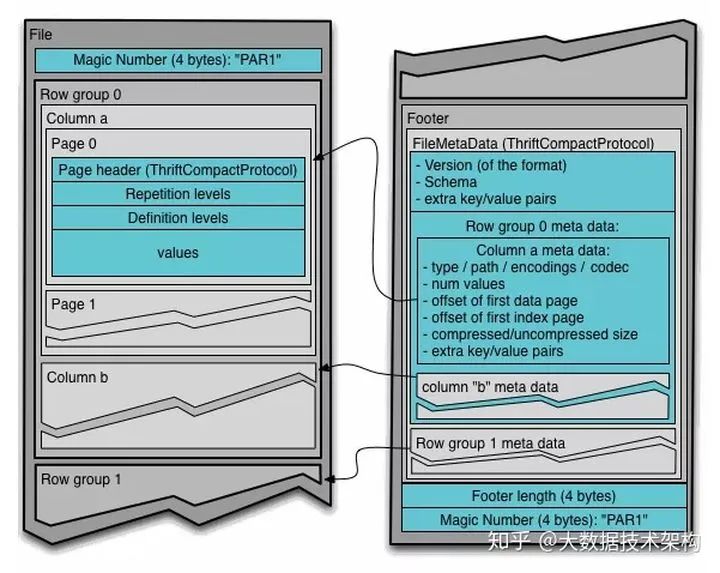
干货 | 再来聊一聊 Parquet 列式存储格式
Parquet 是 Hadoop 生态圈中主流的列式存储格式,最早是由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 孵化器里毕业成为 Apache 顶级项目。 圈内有这样一句话流传:如果说 HDFS 是大数据时代文件系统的事实标准,Parquet 就是大数据时代存储格式的事实标准。 整体介绍 先简单介绍下: Parquet 是一种支持嵌套结构的列式存储格
Spark SQL数据源 - Parquet文件
当使用Spark SQL处理Parquet文件时,你可以使用spark.read.parquet()方法从文件系统中加载Parquet数据到一个DataFrame中。Parquet是一种列式存储格式,非常适合用于大数据集,因为它提供了高效的压缩和编码方案。 以下是一个简单的例子,展示了如何使用Spark SQL读取Parquet文件: 首先,假设你有一个Parquet文件people.parq
待续 总结 - parquet 与 avro
paruet列存文件结构 可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量 压缩编码可以降低磁盘存储空间 只读取需要的列,支持向量运算,能够获取更好的扫描性能 Schema :Parquet文件尾部存储了文件的元数据信息和统计信息,自描述的,方便解析 Parquet列式存储带来
学习笔记 --- Spark SparkSQL下Parquet中PushDown的实现
PushDown是一种SQL优化方式,通常用在查询。应用场景: 假设通过DataFrame,df.select(a,b,c).filter(by a).filter(by b).select(c).filter(by c)这样的查询,在optimizer阶段,需要合并多个filters(CombineFilters),并调整算子间的顺序,例如将部分filter移到select等前面(PushPr

Parquet 文件生成和读取
文章目录 一、什么是 Parquet二、实现 Java 读写 Parquet 的流程方式一:遇到的坑:坑1:ClassNotFoundException: com.fasterxml.jackson.annotation.JsonMerge坑2:No FileSystem for scheme "file"坑3:与 spark-sql 的引入冲突 方式二: 一、什么是 Par
sparksql文件的读写-json和parquet
//1.读取一个json文本val df1= ssc.read.json("E:\\sparkdata\\person.json")//2.读取数据,在format方法中指定类型val df2=ssc.read.format("json").load("E:\\sparkdata\\person.json")val df3=ssc.read.format("parquet").loa
Spark中写parquet文件是怎么实现的
背景 本文基于 Spark 3.5.0 写本篇文章的目的是在于能够配合spark.sql.maxConcurrentOutputFileWriters参数来加速写parquet文件的速度,为此研究一下Spark写parquet的时候会占用内存的大小,便于配置spark.sql.maxConcurrentOutputFileWriters的值,从而保证任务的稳定性 结论 一个spark par

【python】pyarrow.parquet+pandas:读取及使用parquet文件
文章目录 一、前言1. 所需的库2. 终端指令 二、pyarrow.parquet1. 读取Parquet文件2. 写入Parquet文件3. 对数据进行操作4. 导出数据为csv 三、实战1. 简单读取2. 数据操作(分割feature)3. 迭代方式来处理Parquet文件4. 读取同一文件夹下多个parquet文件 Parquet是一种用于列式存储和压缩数据的文件格式
python导出数据为parquet格式
import duckdb import pandas as pd from sqlalchemy import create_engine # 定义连接到您的 MySQL 或 PostgreSQL 数据库的参数 db_type = 'mysql' # 或 'postgresql' user = 'your_username' password = 'your_password' host =
记csv、parquet数据预览一个bug的解决
文章目录 一、概述二、实现过程1. 业务流程如图:2. 业务逻辑3. 运行结果 三、bug现象1. 单元测试2.运行结果 三、流程梳理1. 方向一2. 方向二 一、概述 工作中遇到通过sparksession解析csv、parquet文件并预览top100的需求。 二、实现过程 1. 业务流程如图: #mermaid-svg-NGM5biIgcYfLpKxi {fon
第64课:SparkSQL下Parquet的数据切分和压缩内幕详解学习笔记
第64课:SparkSQL下Parquet的数据切分和压缩内幕详解学习笔记 本期内容: 1 SparkSQL下Parquet数据切分 2 SparkSQL下的Parquet数据压缩 以Spark官网上的SparkSQL操作Parquet的实例进行讲解: Schema Merging Like ProtocolBuffer, Avro, and Thrift, Parquet
第62课:SparkSQL下的Parquet使用最佳实践和代码实践学习笔记
第62课:SparkSQL下的Parquet使用最佳实践和代码实践学习笔记 本期内容: 1 SparkSQL下的Parquet使用最佳实践 2 SparkSQL下的Parquet实战 一:Spark SQL下的Parquet使用最佳实践 1, 过去整个业界对大数据的分析的技术栈的Pipeline一般分为以下两种方式: a) Data Source->HDFS->MR/Hive/S

iceberg org.apache.iceberg.parquet.Parquet parquet file read
org.apache.iceberg.parquet.Parquet#read public static ReadBuilder read(InputFile file) {return new ReadBuilder(file);} org.apache.iceberg.parquet.Parquet.ReadBuilder public static class ReadBuil
JDBC,CaseClass,JSON,Parquet和Schema五种方式创建DataFrame
1.JDBC的方式创建DataFrame import java.util.HashMap;import java.util.List;import java.util.Map;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import org.apache.s

Hive数仓建表时选用ORC还是PARQUET,压缩选Lzo还是snappy?
目录 1 文件存储格式1.1 ORC1.1.1 ORC的存储结构1.1.2 关于ORC的hive配置 1.2 Parquet1.2.1 Parquet的存储结构1.2.2 Parquet的表配置属性 1.3 ORC和Parquet对比 2 压缩方式3 存储和压缩结合该如何选择?3.1 ORC格式存储,Snappy压缩3.2 Parquet格式存储,Lzo压缩3.3 Parquet格式存储,S