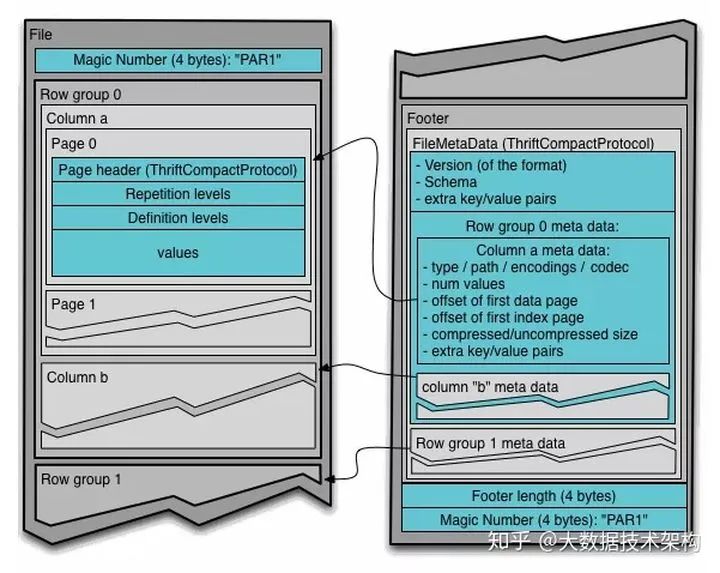
本文主要是介绍关于parquet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Parquet与ORC:高性能列式存储格式
http://blog.csdn.net/yu616568/article/details/51868447
Using Apache Parquet Data Files with CDH
https://www.cloudera.com/documentation/enterprise/5-8-x/topics/cdh_ig_parquet.html#parquet_examples
hive 存储格式和压缩方式 一:Snappy + SequenceFile
http://blog.csdn.net/lucien_zong/article/details/10569073
这篇关于关于parquet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!