oral专题

Talk|CVPR‘24 Oral:超越3D - Point Transformer V3中的多模态特征提取新构想
本期为TechBeat人工智能社区第599期线上Talk。 北京时间6月12日(周三)20:00,香港大学博士生—吴虓杨的Talk已经准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “超越3D - Point Transformer V3中的多模态特征提取新构想”,他通过PTv3的两个核心思想——骨干网络设计的规模准则与非结构化数据的序列化技术,探究3D点云骨干网络作为一种多

Training Region-based Object Detectors with Online Hard Example Mining(CVPR2016 Oral)
转载自:http://zhangliliang.com/2016/04/13/paper-note-ohem/ Training Region-based Object Detectors with Online Hard Example Mining是CMU实验室和rbg大神合作的paper,cvpr16的oral,来源见这里:http://arxiv.org/pdf/1604.03540
The Clock and the Pizza [NeurIPS 2023 oral]
本篇文章发表于NeurIPS 2023 (oral),作者来自于MIT。 文章链接:https://arxiv.org/abs/2306.17844 一、概述 目前,多模态大语言模型的出现为人工智能带来新一轮发展,相关理论也逐渐从纸面走向现实,影响着人们日常生活的方方面面。在享受着技术提供给我们福利的同时,人们也在不断尝试去探索这些模型/算法背后的原理究竟是什么,不禁思考这样几个
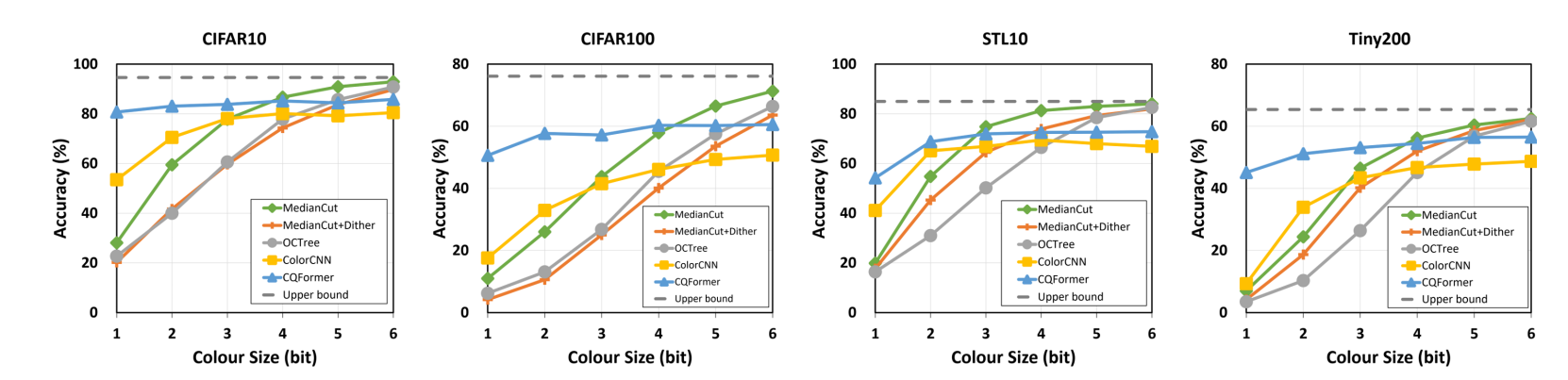
ICCV 2023 Oral | 人类语言演化中学习最优图像颜色编码
人类的语言是一种对复杂世界的高度简洁的编码,特别是语言中颜色的概念,成功地将原本极大的色彩空间(如256三次方真色彩空间)压缩至5到10种颜色。受此启发,来自上海交大,日本理化学研究所,东京大学 的研究人员,提出全新的基于视觉任务的色彩量化(colour quantisation)技术,利用深度学习重现人类数万年的颜色概念的演化。这项技术不但能推进文化人类学的研究,更是为网络量化(neural n
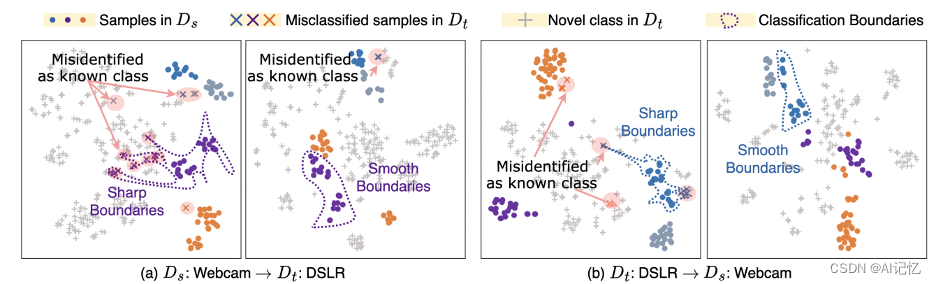
【ICCV Oral】SAN:利用软对比学习和全能分类器提升新类发现,FaceChain团队联合出品
本文提出了一个领域适应框架Soft-contrastive All-in-one Network(SAN),旨在高效、准确、原生地控制领域间新类别的发现和适应。具体来说,SAN采用了一种新颖的基于数据增强的软对比学习(SCL)损失来微调深度神经网络,并引入了全能(All-in-One, AIO)分类器,这种策略不仅有效地解决了数据增强中的视图噪声问题,还显著提高了新类别发现的能力,

NTU S-Lab等提出基于GPT的3D舞蹈生成新框架(CVPR 2022 Oral)
关注公众号,发现CV技术之美 本篇文章分享 CVPR 2022 Oral 论文『Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory』,由 NTU S-Lab 等提出基于 GPT 的 3D 舞蹈生成新框架。 详细信息如下: 论文链接:https://arxiv.org/abs/2203.13055

Frequently oral english sentence!
1. I see. 我明白了。2. I quit! 我不干了!3. Let go! 放手!4. Me too. 我也是。5. My god! 天哪!6. No way! 不行!7. Come on. 来吧(赶快)8. Hold on. 等一等。9. I agree。 我同意。10. Not bad. 还不错。11. Not yet. 还没。12. See you. 再见。13. Shut up!
3DV 2024 Oral | SlimmeRF:可动态压缩辐射场,实现模型大小和建模精度的灵活权衡
目前大多数NeRF模型要么通过使用大型模型来实现高精度,要么通过牺牲精度来节省内存资源。这使得任何单一模型的适用范围受到局限,因为高精度模型可能无法适应低内存设备,而内存高效模型可能无法满足高质量要求。为此,本文研究者提出了SlimmeRF,一种在测试阶段随时(即不需要对模型进行重新训练)通过动态压缩实现模型大小与精度之间权衡的模型,从而使模型同时适用于不同计算预算的场景。实验结果显示,Slim

【SiamDW(CVPR2019)oral】论文阅读Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Deeper and Wider Siamese Networks for Real-Time Visual Tracking 论文地址 代码 写在前面 又是一篇关于SiamRPN的改进,加深了网络宽度与深度,优化特征提取过程,效果很好。 Motivation 深度的网络如ResNet在其他视觉任务上都有很好的表现,然而却不能移植到目标跟踪领域中;网络太深导致最后特征的感受野太大,更加关注
CVPR2020 Oral|实例分割新思路: Deep Snake
点击上方“AI算法修炼营”,选择加星标或“置顶” 标题以下,全是干货 本文授权转自知乎作者彭思达,整理:极市平台 地址:https://zhuanlan.zhihu.com/p/134111177 记得点击文章最后:阅读原文,支持原作者 仅做学术交流,如有侵权,请联系删文 我们介绍一篇2020 CVPR Oral的实例分割的论文:Deep Snake for Real-Time Instance
CVPR 2015 Oral概览 - 第二天上午
第二天上午两大主题:富有新意活力的图像与语言部分,以及在传统中更上层楼的多视几何。 D2-AM-A. Image and Language 【Show and Tell: A Neural Image Caption Generator】 看图说话:神经网络图像标题生成器 (Google) 输入图片,输出一句描述性语言。 训练:最大化训

CVPR 2015 Oral概览 - 第一天下午
第一天下午两大主题:脑洞大开的图像信息挖掘,以及三维对象分析。 D1-PA-2A. Discovery and Dense Correspondence 【Discovering States and Transformations in Image Collections 】 在图像集合中发现状态和变化。 (MIT) 不再识别一

CVPR 2015 Oral概览 - 第一天上午
第一天上午的两大主题:迅猛发展的深度学习和枝繁叶茂的3D摄像头。 D1-AM-A. CNN Architectures 【Hypercolumns for Object Segmentation and Fine-Grained Localizatio】 利用Hypercolumn进行目标分割和精细定位 (Ross Girshick, Jitendra Malik) 一个像素

CVPR 2015 Oral概览 - 综述
CVPR 2015于今天6月8号到10号在波士顿召开。其中Oral部分每天上下午各一场,每场同时进行两个主题。 本系列先综述各个主题,而后介绍每篇Oral论文。 介绍主要集中在“干了什么”,如果看得懂也简单说说“怎么干”。 点击每个半天标题跳转至逐篇论文介绍。 个人感觉,排在前面的主题更有趣。 -----------------------------------------
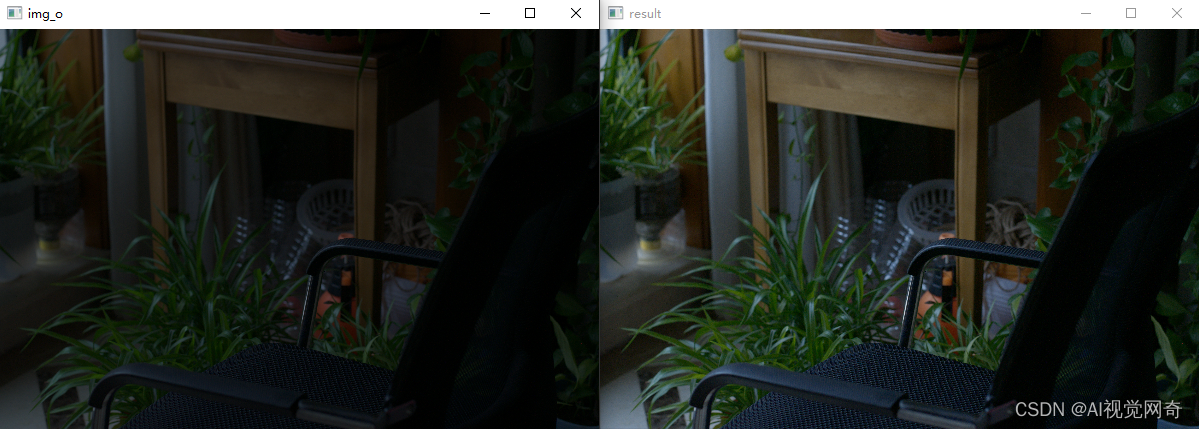
CVPR 2022 Oral 大连理工提出的SCI 快速、超强的低光照图像增强方法 可视化代码
模型43M,1060显卡 640*400 图像耗时1-2毫秒,速度挺快的。 开源地址: GitHub - vis-opt-group/SCI: [CVPR 2022] This is the official code for the paper "Toward Fast, Flexible, and Robust Low-Light Image Enhancement". demo效果:
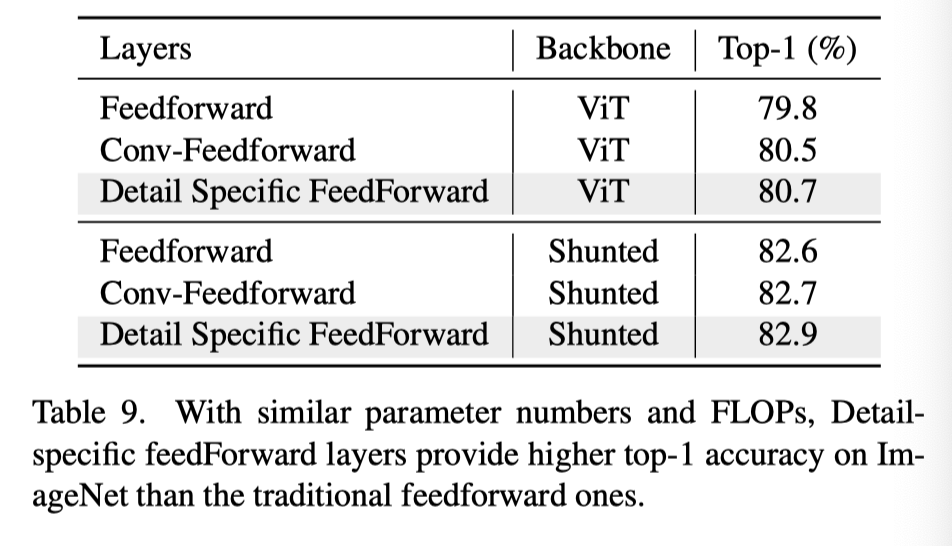
CVPR22 Oral|通过多尺度token聚合分流自注意力,代码已开源
【写在前面】 最近的视觉Transformer(ViT)模型在各种计算机视觉任务中取得了令人鼓舞的结果,这得益于其通过自注意力建模图像块或token的长期依赖性的能力。然而,这些模型通常指定每个层内每个token特征的类似感受野。这种约束不可避免地限制了每个自注意力层捕捉多尺度特征的能力,从而导致处理具有不同尺度的多个对象的图像的性能下降。为了解决这个问题,作者提出了一种新的通用策略,称为
CVPR 2020 Oral | 旷视研究院提出密集场景检测新方法:一个候选框,多个预测结果...
IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含 6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,
【ICCV 2023 Oral】解读Text2Video-Zero:解锁 Zero-shot 视频生成任务
Diffusion Models视频生成-博客汇总 前言:上一篇博客讲了Sketching the Future,里面大部分的方法和思路都来自于Text2Video-Zero。Text2Video-Zero开辟了zero-shot视频生成任务,除此之外,用运动动力学和跨帧注意力机制有效解决时间连贯性问题;Text2Video-Zero结合ControlNet可以在条件文生图领域得到非常好

CVPR 2022 Oral | AdaFace:人脸识别新损失函数!用于人脸识别的质量自适应Margin
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 转载自:集智书童 AdaFace: Quality Adaptive Margin for Face Recognition 论文:https://arxiv.org/abs/2204.00964 代码(已开源): https://github.com/mk-minchul/AdaFace 一直以来,低质量图像的人脸识别都

CVPR2022 Oral:GAN监督的密集视觉对齐
1 引言 该论文发表于CVPR2022,主要是关于GAN监督学习在密集视觉对齐中的应用,并且论文代码已经开源。在该论文中作者提出了一种用于端到端联合学习的GAN生成数据的框架。受到经典方法的启发,论文中作者联合训练一个空间变换器,将随机样本从基于未对齐数据训练的GAN映射到共同的、联合学习的目标模式。实验展示了8个数据集上的结果(如下图所示),可以直观的发现该论文的方法成功地对齐了复杂数据,并
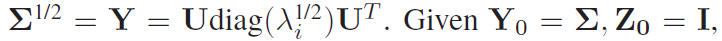
【CVPR19 超分辨率】(Oral)Second-order Attention Network for Single Image Super-Resolution
今天介绍一篇CPVR19的Oral文章,用二阶注意力网络来进行单图像超分辨率。作者来自清华深研院,鹏城实验室,香港理工大学以及阿里巴巴达摩院。 文章地址 github code 文章的出发点:现存的基于CNN的模型仍然面临一些限制: 大多数基于CNN的SR方法没有充分利用原始LR图像的信息,导致相当低的性能大多数CNN-based models主要专注于设计更深或是更宽的网络,以学习更有判别力的
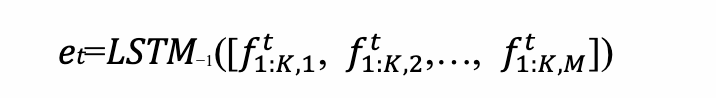
顶会最强的前20%!电影情感效应预测论文拿下ACMMM Oral收录!
本文内容出自阿里文娱AI大脑北斗星团队,研究成果已发表在ACMMM 2022 论文名:Enlarging the Long-time Dependencies via RL-based Memory Network in Movie Affective Analysis 作者:张杰、赵寅、钱凯 背景 三流的导演拍故事,一流的导演拍情绪。纵观古往今外,经典的高分电影之所以经久不衰,无一不是因