本文主要是介绍CVPR22 Oral|通过多尺度token聚合分流自注意力,代码已开源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

【写在前面】
最近的视觉Transformer(ViT)模型在各种计算机视觉任务中取得了令人鼓舞的结果,这得益于其通过自注意力建模图像块或token的长期依赖性的能力。然而,这些模型通常指定每个层内每个token特征的类似感受野。这种约束不可避免地限制了每个自注意力层捕捉多尺度特征的能力,从而导致处理具有不同尺度的多个对象的图像的性能下降。为了解决这个问题,作者提出了一种新的通用策略,称为分流自注意力(SSA),该策略允许VIT在每个注意力层的混合尺度上对注意力进行建模。SSA的关键思想是将异质感受野大小注入token:在计算自注意力矩阵之前,它选择性地合并token以表示较大的对象特征,同时保留某些token以保留细粒度特征。这种新的合并方案使自注意力能够学习不同大小对象之间的关系,同时减少了token数和计算成本。跨各种任务的大量实验证明了SSA的优越性。具体来说,基于SSA的Transformer达到了84.0%的Top-1精度,优于ImageNet上最先进的Focal Transformer,模型尺寸和计算成本仅为其一半,在相似的参数和计算成本下,在COCO上超过了Focal Transformer 1.3 mAP,在ADE20K上超过了2.9 mIOU。
1. 论文和代码地址

Shunted Self-Attention via Multi-Scale Token Aggregation
论文地址:https://arxiv.org/abs/2111.15193[1]
代码地址:https://github.com/oliverrensu/shunted-transformer[2]
2. Motivation
最近的视觉Transformer(ViT)模型在各种计算机视觉任务中表现出了卓越的性能。与专注于局部建模的卷积神经网络不同,ViTs将输入图像划分为一系列patch,并通过全局自注意力逐步更新token特征。自注意力可以有效地模拟token的长期依赖性,并通过聚合来自其他token的信息来逐步扩大其感受野的大小,这在很大程度上解释了VIT的成功。
然而,自注意力机制也带来了昂贵的内存消耗成本,即输入token数量的平方比。因此,最先进的Transformer模型采用了各种降采样策略来减少特征大小和内存消耗。一些方法努力计算高分辨率特征的自注意力,并通过将token与token的空间缩减合并来降低成本。然而,这些方法倾向于在一个自注意力层中合并过多的token,从而导致来自小对象和背景噪声的token的混合。这种行为反过来会降低模型捕获小对象的效率。
此外,以前的Transformer模型在很大程度上忽略了注意力层内场景对象的多尺度性质,使得它们在涉及不同大小对象的野生场景中变得脆弱。从技术上讲,这种无能归因于其潜在的注意机制:现有方法仅依赖token的静态感受野和一个注意层内的统一信息粒度,因此无法同时捕获不同尺度的特征。
为了解决这一局限性,作者引入了一种新的通用自注意力方案,称为分流自注意力(SSA),该方案明确允许同一层内的自注意力头分别考虑粗粒度和细粒度特征。与以前合并过多token或捕捉小对象失败的方法不同,SSA有效地在同一层的不同注意头上同时对不同规模的对象建模,使其具有良好的计算效率和保留细粒度细节的能力。

作者在上图中展示了自注意力(来自ViT)、下采样辅助注意力(来自PVT)和SSA之间的定性比较。当对相同大小的特征映射应用不同的注意时,ViT捕捉细粒度的小对象,但具有计算成本极高(上图(a));PVT降低了计算成本,但其注意力仅限于粗粒度较大的对象(上图(b))。相比之下,提出的SSA保持了较轻的计算负载,但同时考虑了混合尺度注意(上图(c))。有效地,SSA不仅精确地关注粗粒度的大对象(如沙发),而且还关注细粒度的小对象(如灯光和风扇),甚至一些位于角落的对象,这些对象不幸被PVT忽略。作者还在下图中展示了注意力图的视觉比较,以突出SSA的学习尺度自适应注意力。

SSA的多尺度注意力机制是通过将多个注意力头分成几个组来实现的。每个组都有一个专用的注意力粒度。对于细粒度组,SSA学习聚合少量token并保留更多局部细节。对于剩余的粗粒度头组,SSA学习聚合大量token,从而降低计算成本,同时保持捕获大型对象的能力。多粒度组共同学习多粒度信息,使模型能够有效地建模多尺度对象。
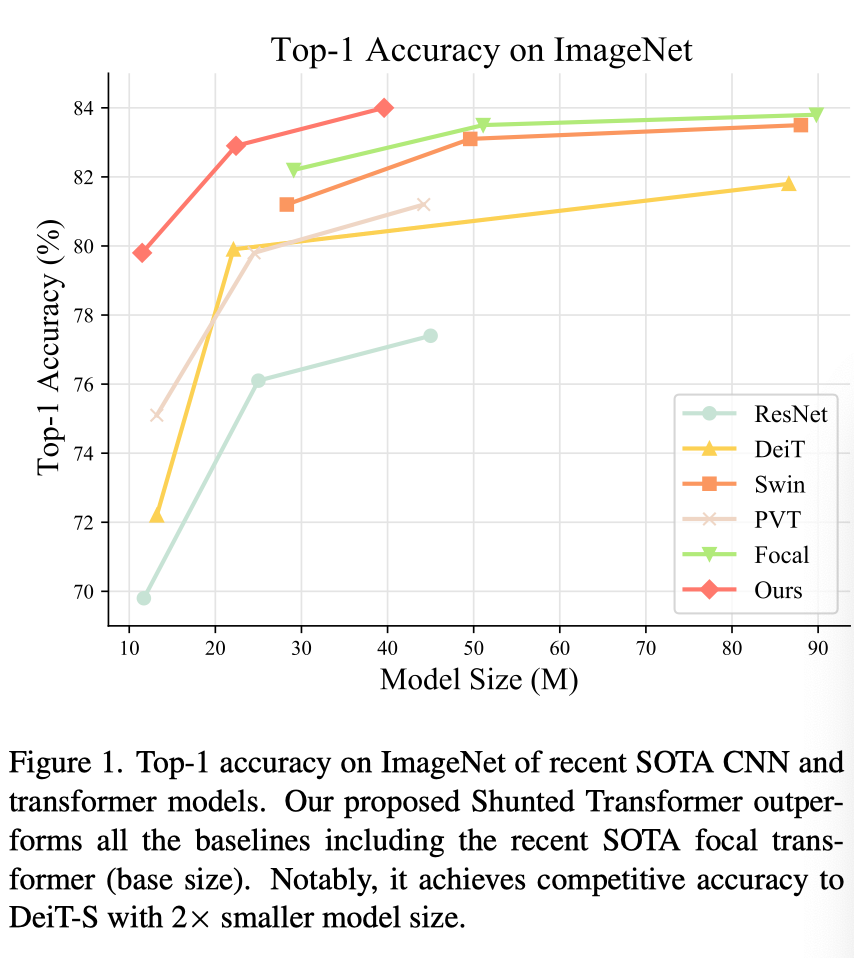
如上图所示,作者展示了从堆叠多个基于SSA的块获得的分流Transformer模型的性能。在ImageNet上,本文的分流Transformer优于最先进的聚焦Transformer,同时将模型尺寸减半。当缩小到微小尺寸时,分流Transformer实现了与DeiT Small相似的性能,但只有50%的参数。对于对象检测、实例分割和语义分割,在模型大小相似的COCO和ADE20K上,分流Transformer始终优于聚焦Transformer。
本文的贡献如下:
作者提出了分流自注意力(SSA),它通过多尺度token聚合在一个自注意力层内统一多尺度特征提取。本文的SSA自适应地合并大对象上的token以提高计算效率,并保留小对象的token。
基于SSA,作者构建了分流Transformer,能够有效捕获多尺度对象,尤其是小型和远程孤立对象。
作者评估了提出的分流Transformer的各种研究,包括分类,目标检测和分割。实验结果表明,在相似的模型尺寸下,本文的分流Transformer始终优于以前的视觉Transformer。
3. 方法
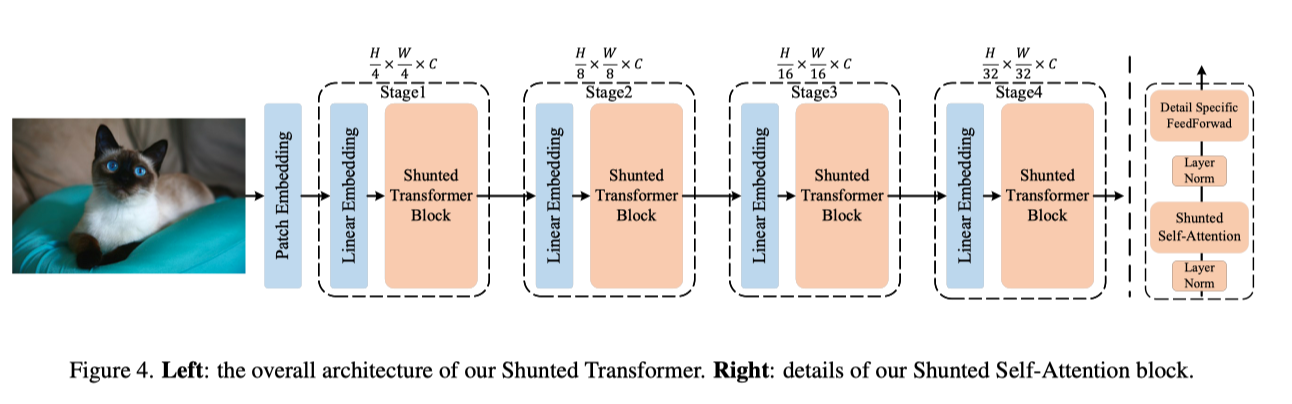
本文提出的分流Transformer的整体架构如上图所示。它建立在新型分流自注意力(SSA)块的基础上。本文的SSA块与ViT中的传统自注意力块有两个主要区别:1)SSA为每个自注意力层引入了分流注意力机制,以捕获多粒度信息和更好地建模不同大小的对象,尤其是小对象;2) 它通过增强跨token交互,增强了在逐点前馈层提取局部信息的能力。此外,本文的分流Transformer部署了一种新的patch嵌入方法,用于为第一个注意力块获得更好的输入特征图。在下文中,作者将逐一阐述这些新颖之处。
3.1. Shunted Transformer Block
在提出的分流Transformer的第i个阶段,有 个Transformer块。每个transformer块包含一个自注意力层和一个前馈层。为了减少处理高分辨率特征图时的计算成本,PVT引入了空间归约注意力(spatial-reduction attention,SRA)来取代原来的多头自注意力(multi-head self attention,MSA)。然而,SRA倾向于在一个自注意力层中聚合太多token,并且仅在单个尺度上提供token特性。这些局限性阻碍了模型捕捉多尺度对象尤其是小尺寸对象的能力。因此,作者在一个自注意力层内并行引入了具有学习多粒度的分流自注意力。
3.1.1 Shunted Self-Attention
输入序列 首先投影到查询(Q)、键(K)和值(V)张量中。然后,多头自注意力采用H个独立注意头并行计算自注意力。为了降低计算成本,作者遵循PVT并减少K和V的长度,而不是像在Swin Transformer中那样将{Q,K,V}分割为多个区域。
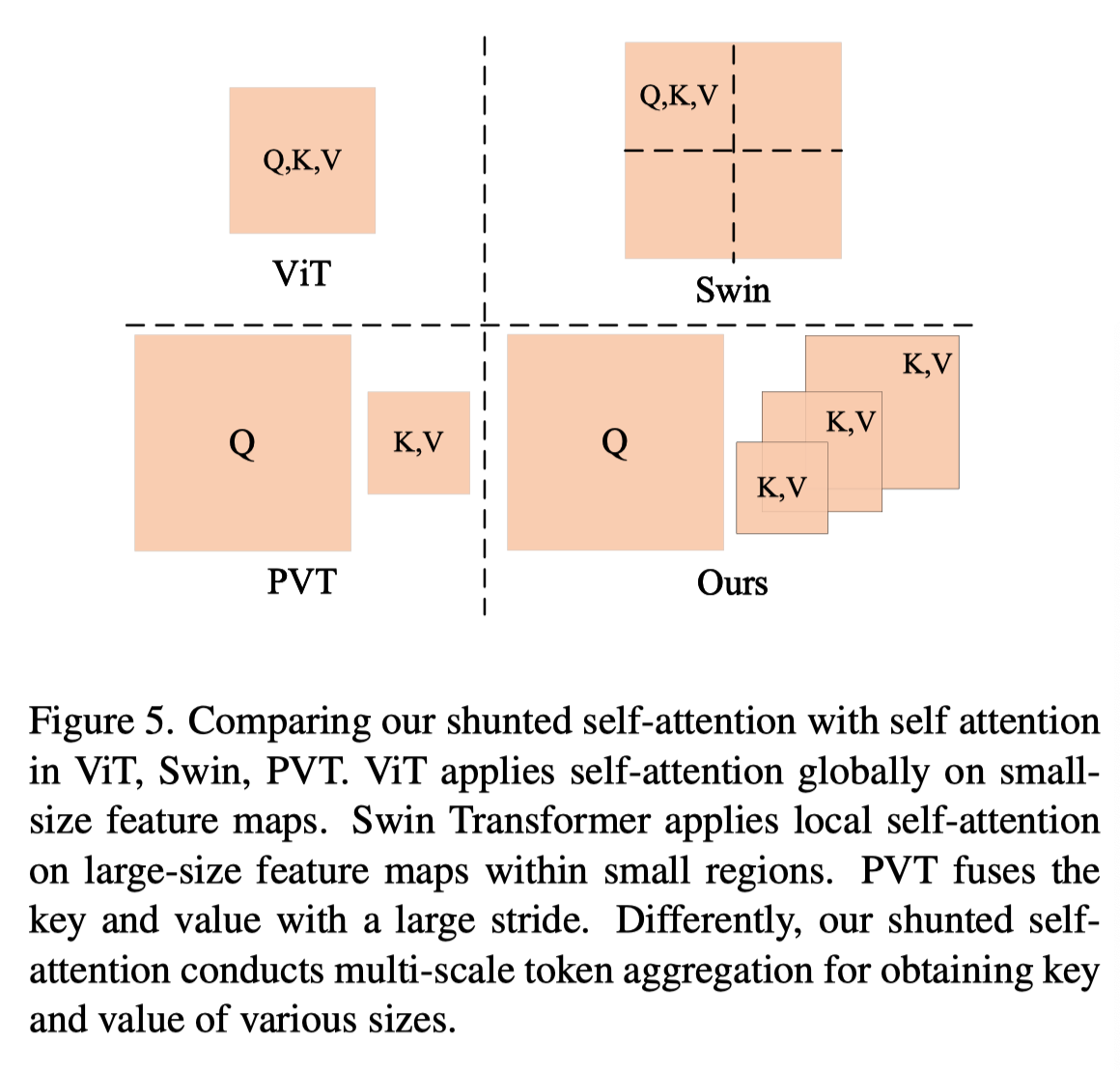
如上图所示,本文的SSA不同于PVT的SRA,因为K,V的长度在同一个自注意力层的注意头之间不相同。相反,长度在不同的头部不同,用于捕获不同粒度的信息。这提供了多尺度token聚合(MTA)。具体而言,对于由i索引的不同头部,将键K和值V下采样到不同大小:
这里, 是第i个头中的多尺度token聚合层,下采样率为 。在实践中,作者使用卷积核和步长为 的卷积核进行卷积层。 是第i个头中线性投影的参数。在注意力头的一层中有变体 。因此,键和值可以在自注意力中捕捉不同的尺度。 是MTA的局部增强分量,用于深度卷积的V值。与空间缩减相比,保留了更多细粒度和低层次的细节。
然后通过以下公式计算分流的自注意力:
其中 是尺寸。多亏了多尺度键和值,本文分流的自注意力在捕捉多尺度对象时更强大。计算成本的降低可能取决于r的值,因此,可以很好地定义模型和r,以权衡计算成本和模型性能。当r变大时,K,V中合并了更多token,并且K,V的长度较短,因此,计算成本较低,但仍保持捕获大型对象的能力。相反,当r变小时,保留了更多细节,但带来了更多计算成本。在一个自注意力层中集成各种r使其能够捕获多粒度特征。
3.1.2 Detail-specific Feedforward Layers
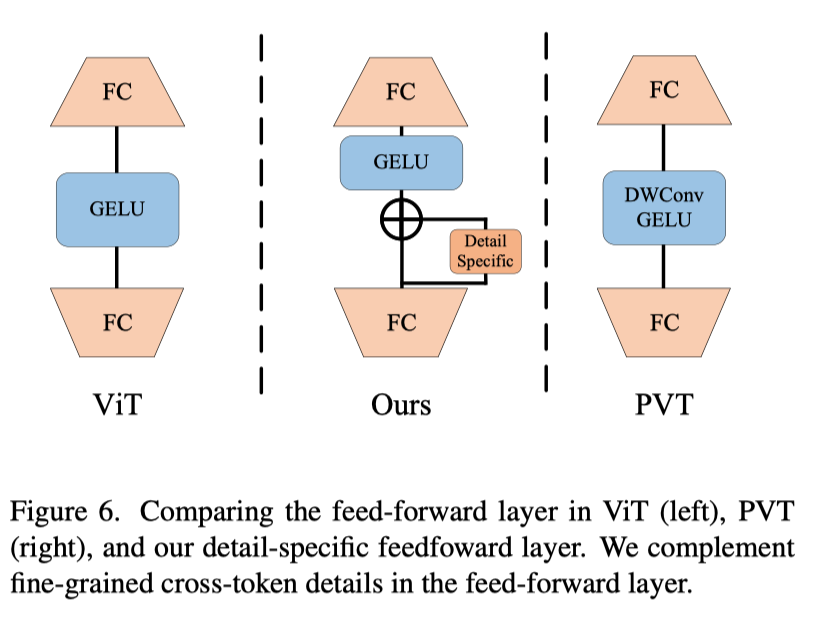
在传统的前馈层中,全连接层是逐点的,无法学习交叉token信息。在这里,作者的目标是通过指定前馈层中的细节来补充局部信息。如上图所示,作者通过在前馈层的两个完全连接的层之间添加数据特定层来补充前馈层中的局部细节:
其中 是具有参数θ的细节特定层,在实践中通过深度卷积实现。
3.2. Patch Embedding
Transformer首先设计用于处理顺序数据。如何将图像映射到序列对于模型的性能很重要。ViT直接将输入图像分割为16×16非重叠patch。最近的一项研究发现,在patch嵌入中使用卷积可以提供更高质量的token序列,并有助于transformer比传统的大步非重叠patch嵌入“看得更好”。因此,一些文献使用7×7卷积进行重叠patch嵌入。
在本文的模型中,作者根据模型大小采用不同的重叠卷积层。作者将步长为2且零填充的7×7卷积层作为patch嵌入的第一层,并根据模型大小增加步长为1的额外3×3卷积层。最后,使用步长为2的非重叠投影层生成大小为 的输入序列。
3.3. Architecture Details and Variants
给定一个大小为H×W×3的输入图像,作者采用上述patch嵌入方案获得长度为 、token维数为C的信息量更大的token序列。根据之前的设计,本文的模型中有四个阶段,每个阶段包含几个分流Transformer块。在每个阶段,每个块输出相同大小的特征图。作者采用带步长2(线性嵌入)的卷积层来连接不同的阶段,在进入下一阶段之前,特征图的大小将减半,但维数将加倍。因此,有每个阶段输出的特征映射 , 的大小为 。

作者提出了本文模型的三种不同配置,以便在类似参数和条件下进行公平比较。如上表所示,head和 表示一个块中的头数和一个阶段中的块数。变体仅来自不同阶段的层数。具体来说,每个块中的头数设置为2,4,8,16。patch嵌入中的卷积范围为1到3。
4.实验
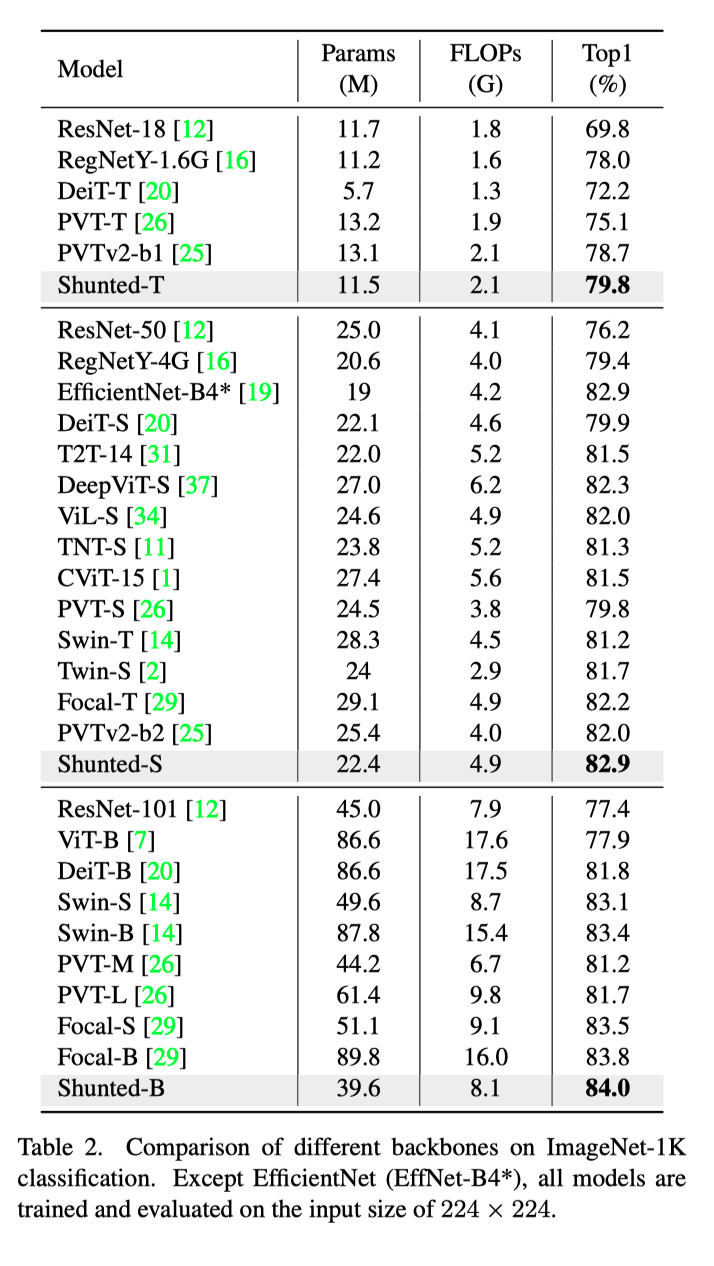
上表展示了本文方法在ImageNet-1K上的实验结果,,可以看出,本文的方法在各个模型大小上都能达到SOTA结果。
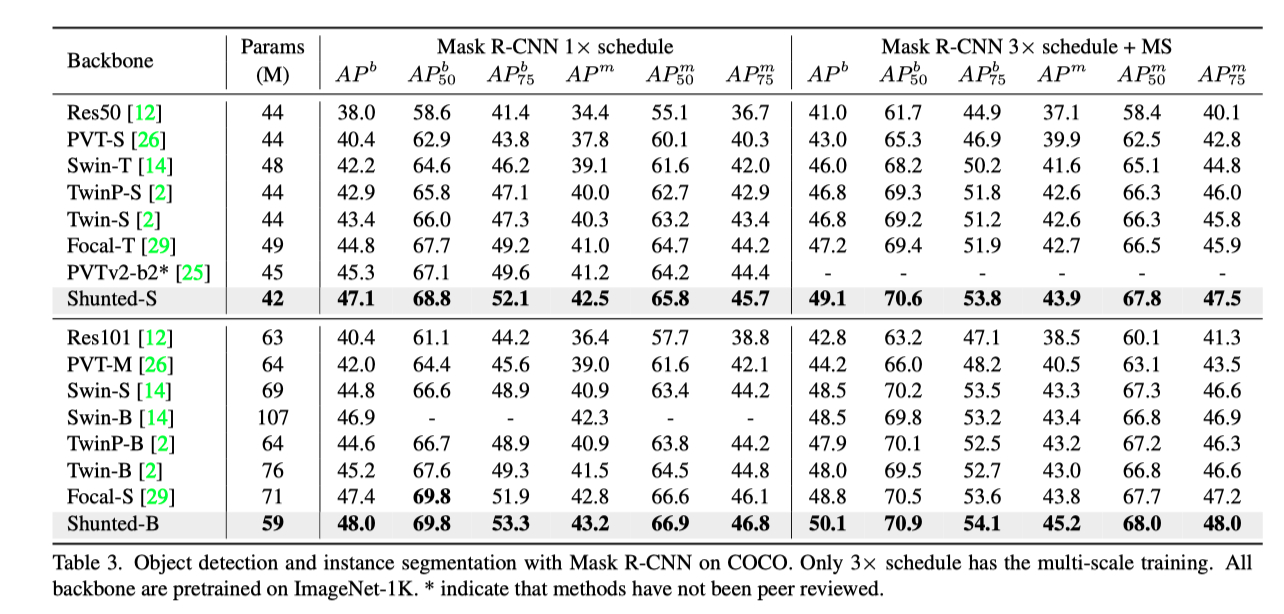
上表展示了用Mask R-CNN进行目标检测和语义分割时,各个模型的性能,可以看出,本文的方法在性能上具有明显优势。
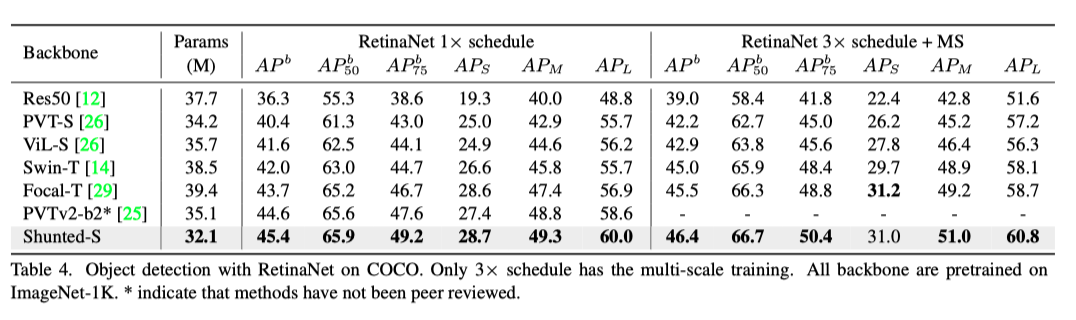
上表展示了用RetinaNet进行目标检测和语义分割时,各个模型的性能。
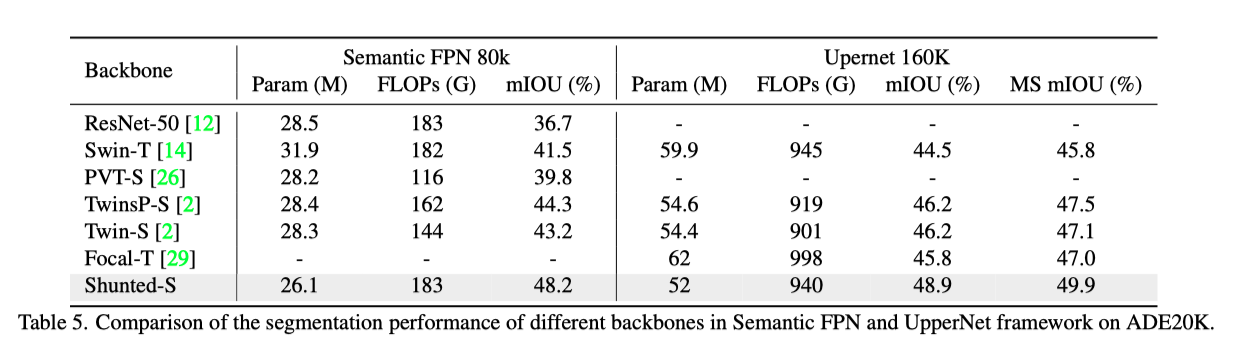
结果如上表所示。本文的分流Transfomer在所有框架中都具有较高的性能和较少的参数,优于以前最先进的Transfomer。
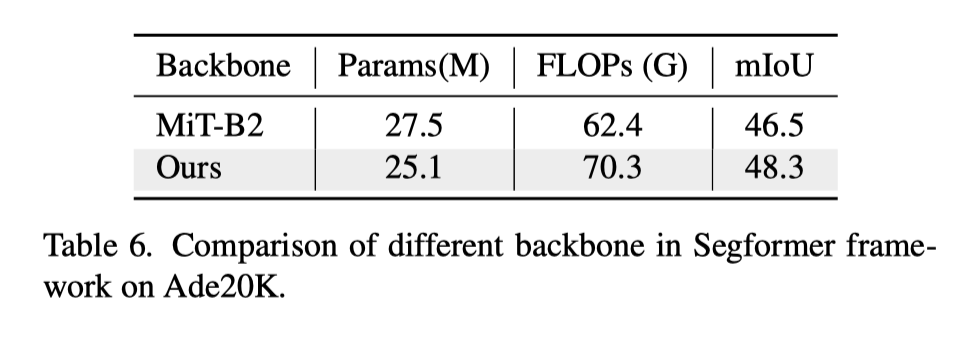
作者还以SegFormer为框架,在Segformers中比较了本文的主干与MiT的主干。结果见上表。
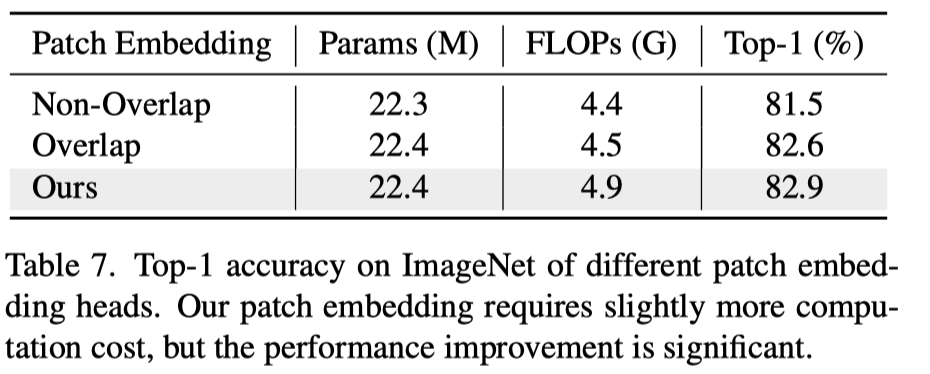
上表展示了不同patch embedding的实验结果。
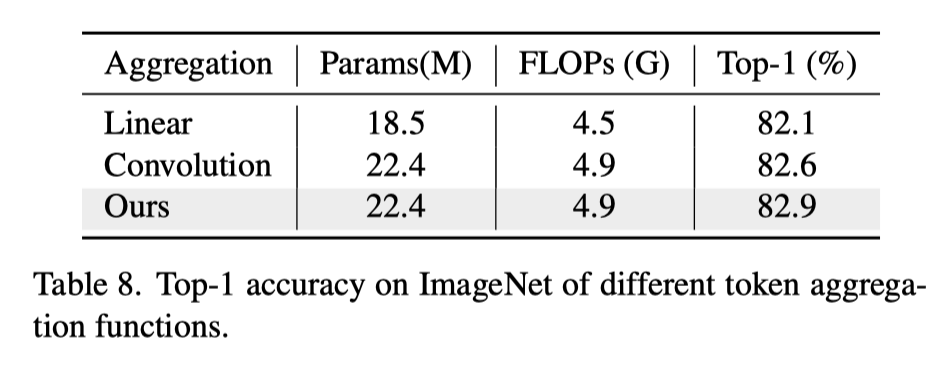
作者提出了一种新的token聚合函数,用于合并多尺度对象的令牌,同时保留全局和局部信息。从上表中可以看出,本文的新token聚合函数具有与卷积空间归约相似的计算,但获得了更多改进。
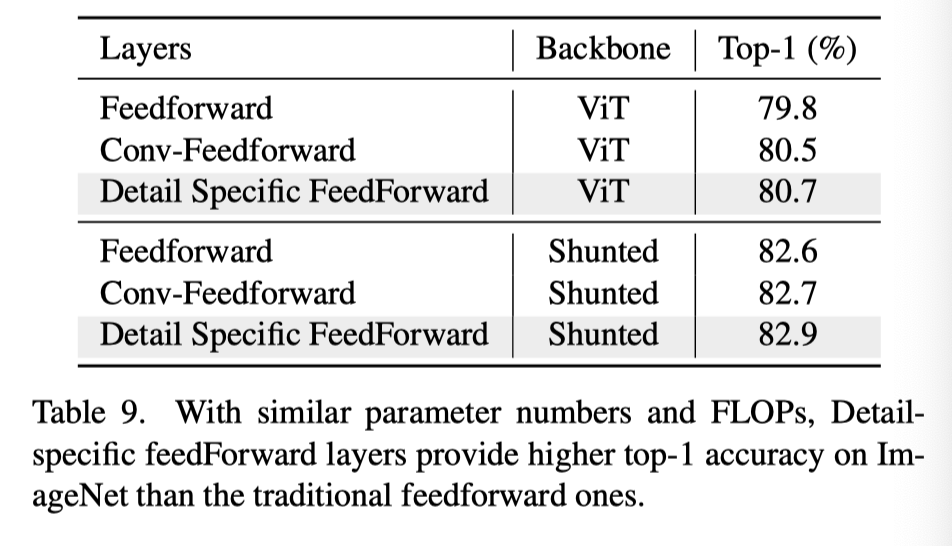
上表展示了本文提出的FFN的性能改进结果。
5. 总结
在本文中,作者提出了一种新的分流自注意力(SSA)方案来明确说明多尺度特征。与以往只关注一个注意力层中静态特征图的工作不同,作者维护了多尺度特征图,这些特征图关注一个自注意力层中的多尺度对象。大量实验表明,本文的模型作为各种下游任务的主干是有效的。具体来说,该模型优于先前的Transformers,并在分类、检测和分割任务上实现了最先进的结果。
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://arxiv.org/abs/2111.15193: https://arxiv.org/abs/2111.15193
[2]https://github.com/oliverrensu/shunted-transformer: https://github.com/oliverrensu/shunted-transformer
本文由 mdnice 多平台发布
这篇关于CVPR22 Oral|通过多尺度token聚合分流自注意力,代码已开源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






