cvpr22专题
CVPR22 Oral|通过多尺度token聚合分流自注意力,代码已开源
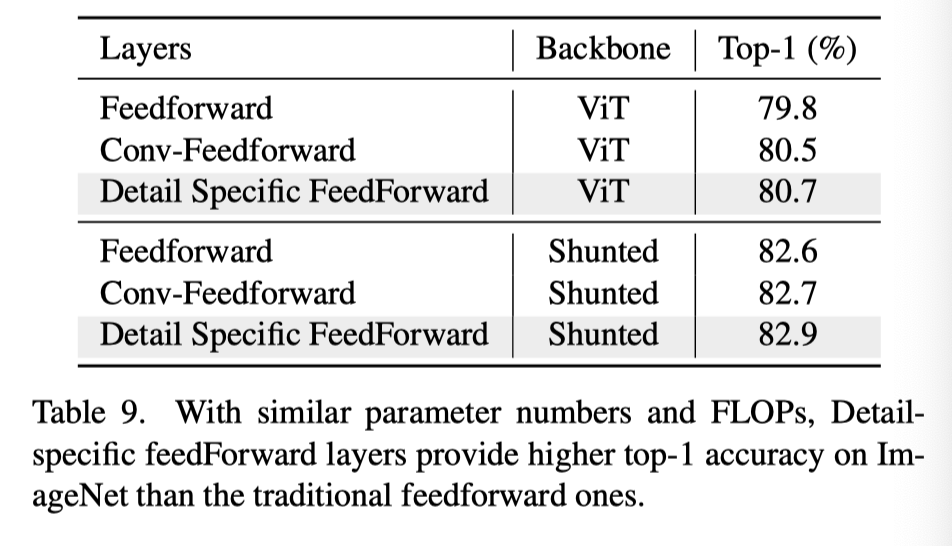
【写在前面】 最近的视觉Transformer(ViT)模型在各种计算机视觉任务中取得了令人鼓舞的结果,这得益于其通过自注意力建模图像块或token的长期依赖性的能力。然而,这些模型通常指定每个层内每个token特征的类似感受野。这种约束不可避免地限制了每个自注意力层捕捉多尺度特征的能力,从而导致处理具有不同尺度的多个对象的图像的性能下降。为了解决这个问题,作者提出了一种新的通用策略,称为