本文主要是介绍ICCV 2023 Oral | 人类语言演化中学习最优图像颜色编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人类的语言是一种对复杂世界的高度简洁的编码,特别是语言中颜色的概念,成功地将原本极大的色彩空间(如256三次方真色彩空间)压缩至5到10种颜色。受此启发,来自上海交大,日本理化学研究所,东京大学 的研究人员,提出全新的基于视觉任务的色彩量化(colour quantisation)技术,利用深度学习重现人类数万年的颜色概念的演化。这项技术不但能推进文化人类学的研究,更是为网络量化(neural network quantisation)以及多模态大语言模型提供坚实的研究基础。目前大语言模型依赖于英语,中文等实际的语言,本工作通过模仿人类语言自然演化,为设计大预言模型-人类同步理解的人造语言打下了基础。
论文题目:
Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer
论文链接:
https://arxiv.org/abs/2212.03434
项目主页:
GitHub - ryeocthiv/CQFormer: [ICCV 2023] "Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer"
研究背景
本工作旨在从机器学习的角度探讨人工智能能否拥有类似人类的的颜色命名分类机制。人类对颜色的感知来自于光谱与眼睛中的锥细胞相互作用时,视神经接收到的光刺激。通过定义像RGB,HSV等颜色空间,颜色被可量化成一些具体的如数值。与纯生理性色调分类相比,颜色命名(colour naming)或颜色分类(colour categorisation)的复杂现象涉及多个学科。
从认知科学到人类学,研究发现,人类语言不断演变以获取新的颜色名称,导致颜色命名系统越来越精细化。比如来自加纳西北部的纳凡拉语,1978年的时候只有如图1.a所示的三种颜色(浅色(fiNge')、暗色(wOO')和温暖或红色(`nyiE')),但是到了2018年,该语言演化出了如图1.b所示的另外七种颜色。
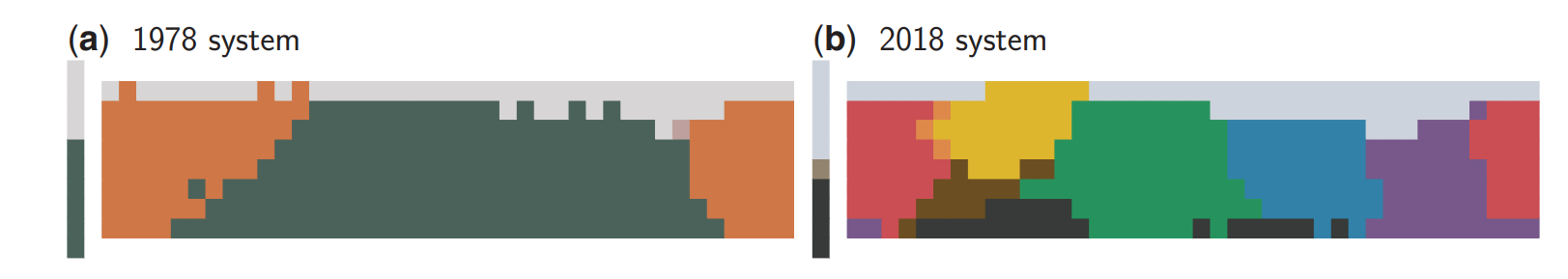
如图2左图所示,现有的研究认为这个演化过程来自于沟通效率(Communication efficiency)和知觉结构(perceptual structure) 的双重演化压力。沟通效率要求通过尽可能少量的词汇来准确传达共享的颜色划分。颜色知觉结构与人类的颜色感知相关。例如,相邻颜色之间的颜色空间距离应与它们的知觉差异相对应。
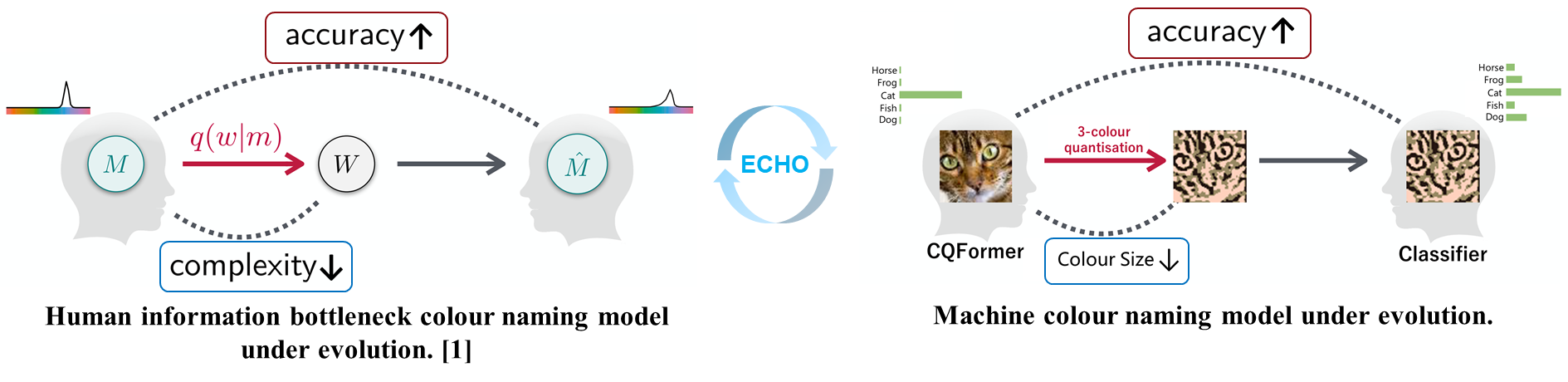
在图2右图里,本项工作通过用检测,分类等视觉任务的性能来定义沟通效率的方法,提出了一套基于QFormer全新的颜色量化(colour quantisation)算法。这个算法不但能整合人类和机器视觉的不同需求,更是一种人工颜色命名系统。
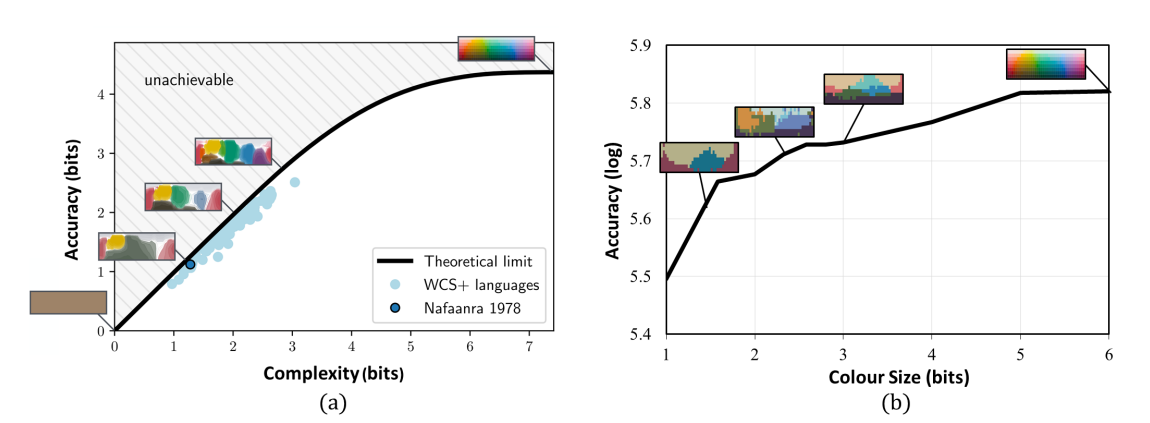
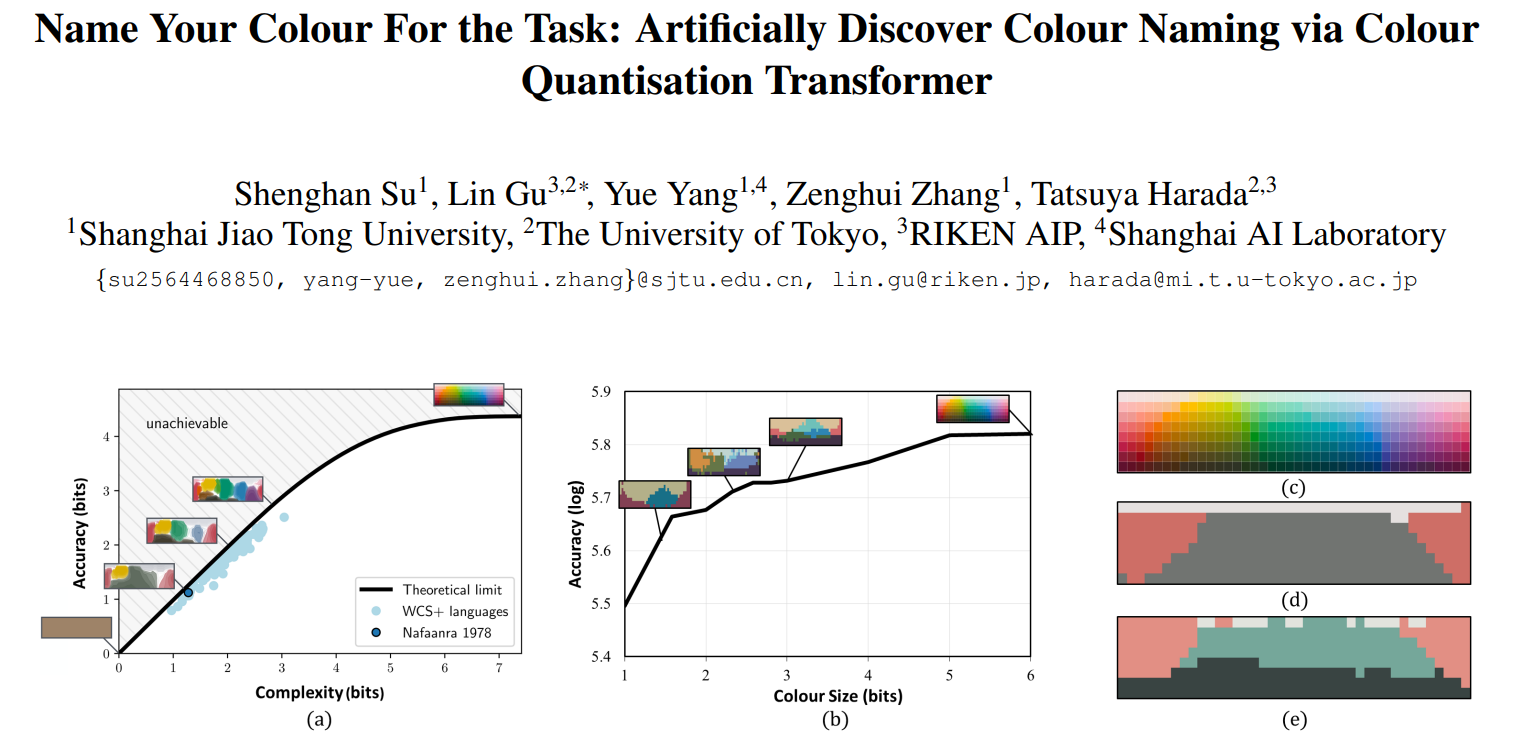
图3(a)显示了不同种类的真实人类语言的理论沟通效率随着颜色名称数量的提升而提高。令人惊讶的是,如图3(b)所显示,人工发现的颜色命名系统中,随着颜色数量的增加,识别准确性也在提高。
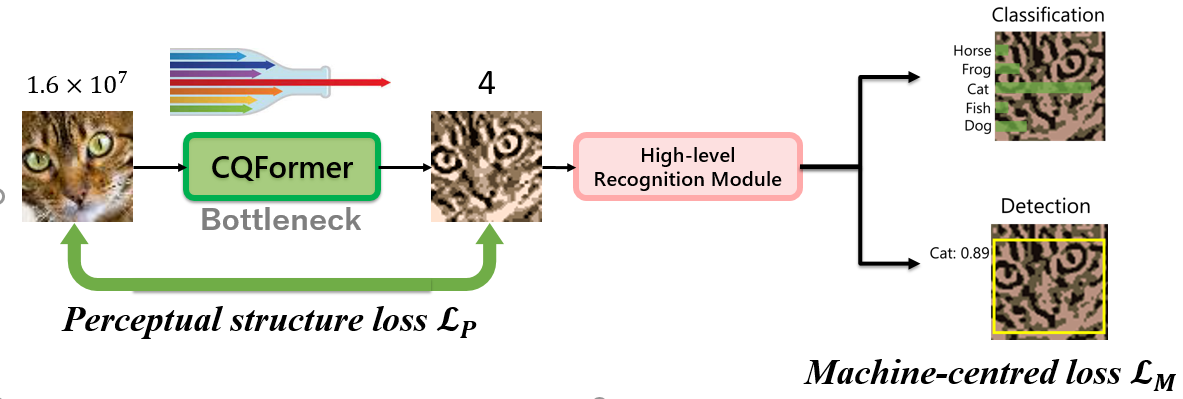
CQFormer的方法如图4所示,使用perceptual structure loss来定量控制来自perceptual structure的演化压力。而用machine-centred loss 来表示Communication efficiency的压力。
本文方法
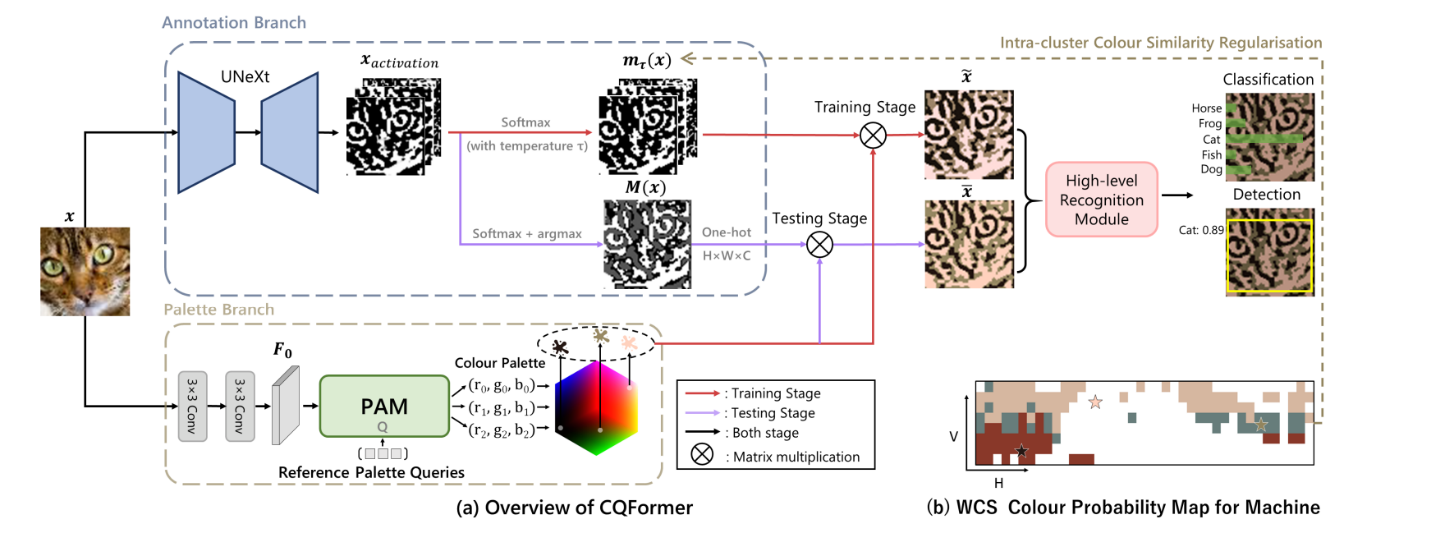
具体的方法如图5所示,包括两个分支:注释分支和调色板分支。
注释分支在将索引映射到对应的颜色调色板之前,为输入的RGB图像的每个像素注释合适的量化颜色索引。通过一个新颖的调色板分支在整个RGB颜色空间中定位颜色调色板,该分支使用变换器的显式注意力查询检测关键点。
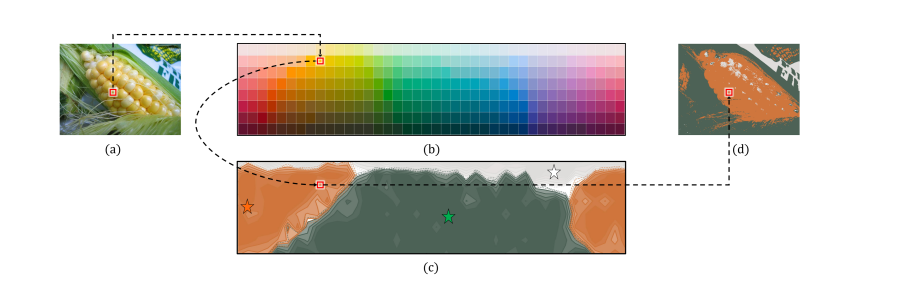
在训练阶段,如图5的红线和黑线所示,调色板分支与输入图像和参考调色板查询进行交互,通过减少感知结构损失来维持知觉结构。这种以感知为中心的设计将相似的颜色分组,并确保颜色调色板充分表示由世界颜色调查(WCS)颜色命名刺激网格定义的颜色命名系统。如图5.(b)所示,调色板中的每个项目(用星号标注)位于WCS颜色命名概率图中对应颜色分布的中间位置。最后,量化图像传递给高级识别模块进行机器准确性任务,如分类和检测。通过CQFormer和随后的高级模块的联合优化,所提出的方法可以平衡感知和机器的需求。
除了自动发现颜色命名系统外, CQFormer还为极端压缩图像存储提供了有效解决方案,同时在高级识别任务中保持高性能。例如,CQFormer在只有1位颜色空间(即,两种颜色)的情况下,在CIFAR100数据集上实现了50.6%的top-1准确率。这种极低比特量化可以用于neural network quantisation研究,实现从图像到权重和激活的端到端优化。
网络结构

颜色演化
通过CQFormer,本工作探索了基于分类任务的颜色演化,包括两个连续阶段,使用不同的损失函数。由于CQFormer最初没有与相应的人类语言相关联的颜色命名系统的先验知识,第一个嵌入阶段旨在将某种语言的颜色感知知识嵌入到CQFormer的潜在表示中。
例如,CQFormer首先通过强制CQFormer输出与Nafaanra对应的相似的WCS颜色概率图来学习和匹配1978年的Nafaanra三色系统。如图6所示,这里设计了两个嵌入解决方案和损失函数,即LFull-Embedding和LCentral-Embedding,以将完整的颜色概率图嵌入或仅将代表性颜色提炼到CQFormer中。
第二个演化阶段让CQFormer演化更多颜色,即在准确性和感知结构的压力下从学到的三色系统中分离出第四种颜色。
实验
本研究在主流的目标检测任务和图像分类任务的基准数据集上评估了CQFormer。此外,还专门设计了一个颜色演化实验以展示CQFormer如何自动演化以增加细粒度的颜色。
表格1显示了在MS COCO数据集上使用Sparse-RCNN检测器进行目标检测的结果。CQFormer在所有颜色量化级别(从1位到6位)下的AP值性能方面均优于所有其他方法。这一显著的改进表明了CQFormer在目标检测任务中的有效性。
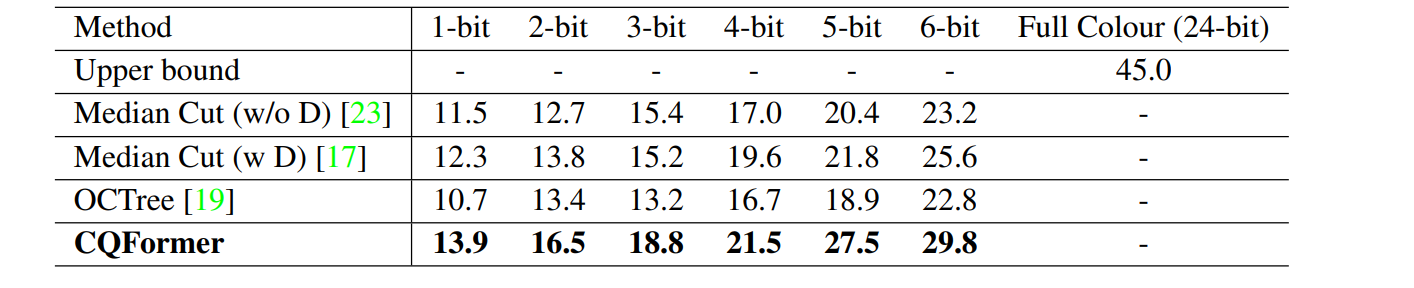
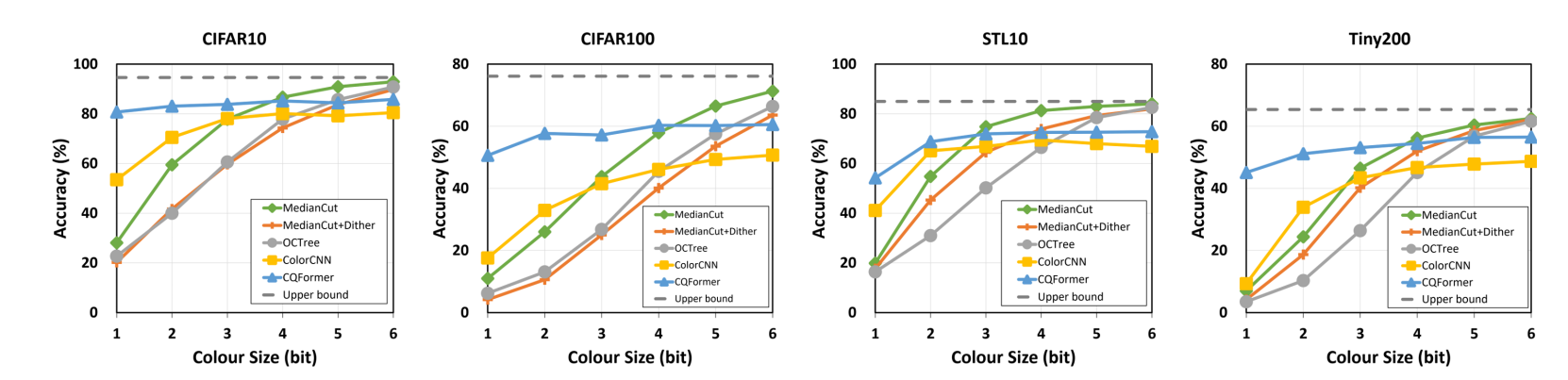
图7对四个数据集上的最新方法进行了比较。CQFormer(实线蓝色线)在极低比特颜色空间(小于3位)上与所有其他方法相比都有持续明显的改进。此外, CQFormer在从1位到6位的所有颜色量化级别下都比以任务为中心的方法ColorCNN表现更优秀。
展望
虽然如图3所示,机器发现的颜色概念的复杂性-准确性权衡与人类语言的分类对应的理论沟通效率极限非常相似,但当前的工作仍处于初步阶段。新发现的WCS颜色概率图与人类的颜色概率图仍然存在很大差异。更准确的语言演化复制需要考虑更复杂的变量,如环境特异性、文化特殊性、功能需求、技术成熟度、学习经验和跨文化交流。
这次提出的 工作除了对技术领域,也有望为人类学语言学领域里的普遍主义-相对主义(linguistic determinism vs relativity)争论做出自己的贡献。尽管没有完全排除颜色方案的文化特异性,但这里机器的发现强烈支持了一种先天的、生理学原则对不同文化传统社区的基本颜色术语的演化顺序和分布可能性。从原始的“暗-亮-红”颜色,人工智能独立地发现了“绿-黄”类别,指向了神经算法与人类认知的一致性,并为通过机器模拟在社会科学中测试有争议的假设拓展了新的前沿。
目前大语言模型依赖于英语,中文等实际的语言,本工作期望跳出特定语言的藩篱,而是从人类语言自然演化本身出发,为设计大预言模型-人类同步理解的人造语言打下基础。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于ICCV 2023 Oral | 人类语言演化中学习最优图像颜色编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







