iccv专题

CvT(ICCV 2021)论文与代码解读
paper:CvT: Introducing Convolutions to Vision Transformers official implementation:https://github.com/microsoft/CvT 出发点 该论文的出发点是改进Vision Transformer (ViT) 的性能和效率。传统的ViT在处理图像分类任务时虽然表现出色,但在数据量较小的情况下,
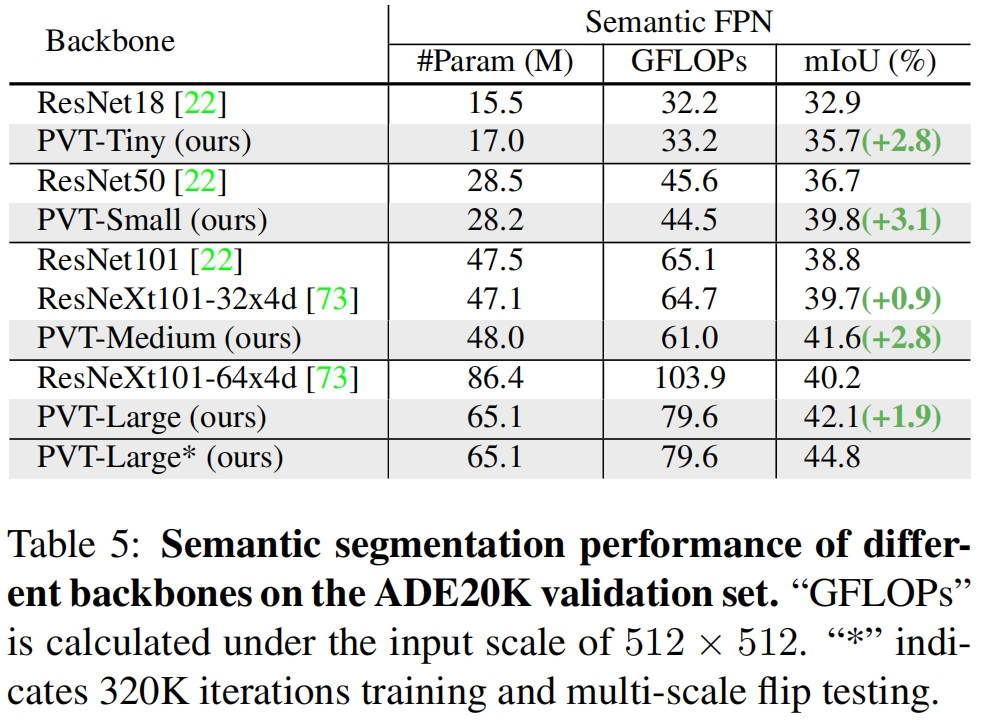
Pyramid Vision Transformer, PVT(ICCV 2021)原理与代码解读
paper:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions official implementation:GitHub - whai362/PVT: Official implementation of PVT series 存在的问题 现有的 Vision
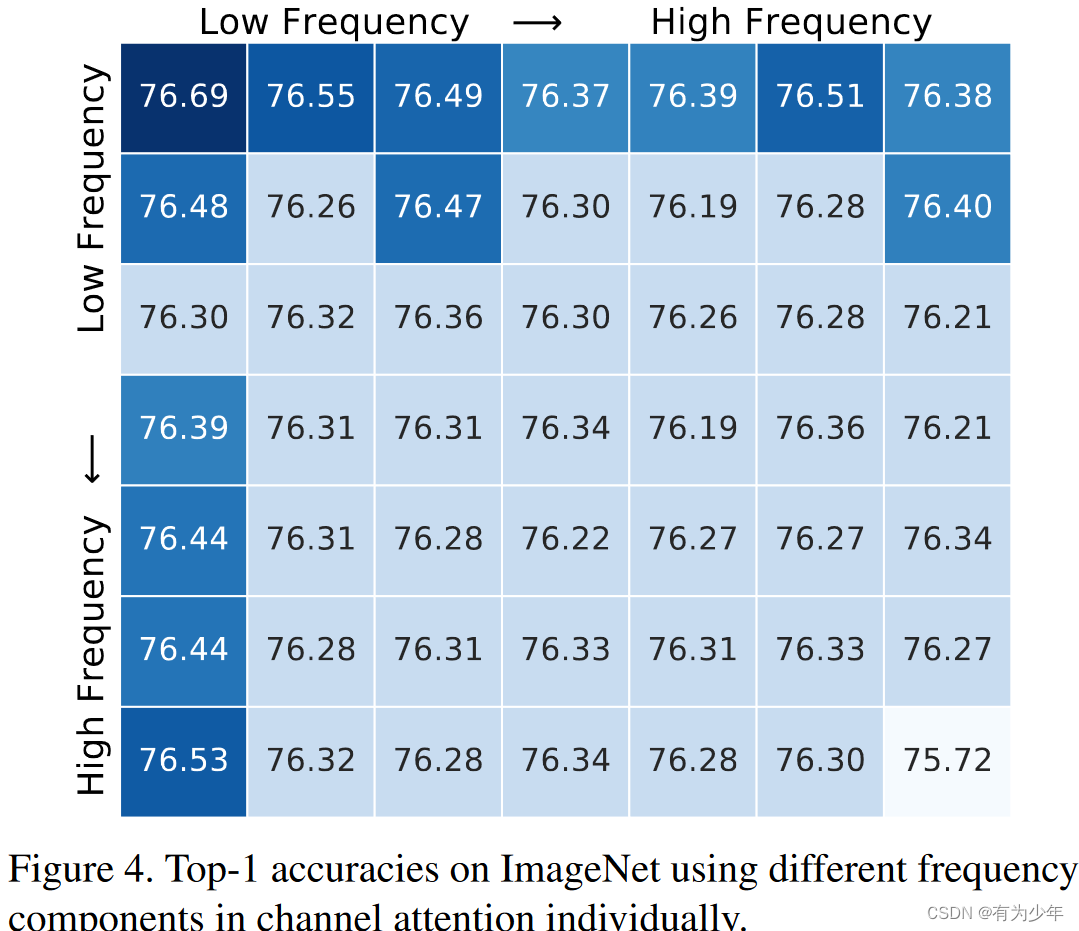
ICCV 2021 | FcaNet: Frequency Channel Attention Networks 中的频率分析
ICCV 2021 | FcaNet: Frequency Channel Attention Networks 中的频率分析 论文:https://arxiv.org/abs/2012.11879代码:https://github.com/cfzd/FcaNet 文章是围绕 2D 的 DCT 进行展开的,本文针对具体的计算逻辑进行梳理和解析。 f ( u , v ) = α u α v

计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR
计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR CVPR、ICCV和ECCV是计算机视觉领域顶级的三个国际会议,而NeurIPS、ICML和ICLR则是机器学习领域最具影响力的三个国际会议。下面是它们的详细介绍: 计算机视觉领域 CVPR (Computer Vision and Pattern Recognition) 主办方:IEEE频率:
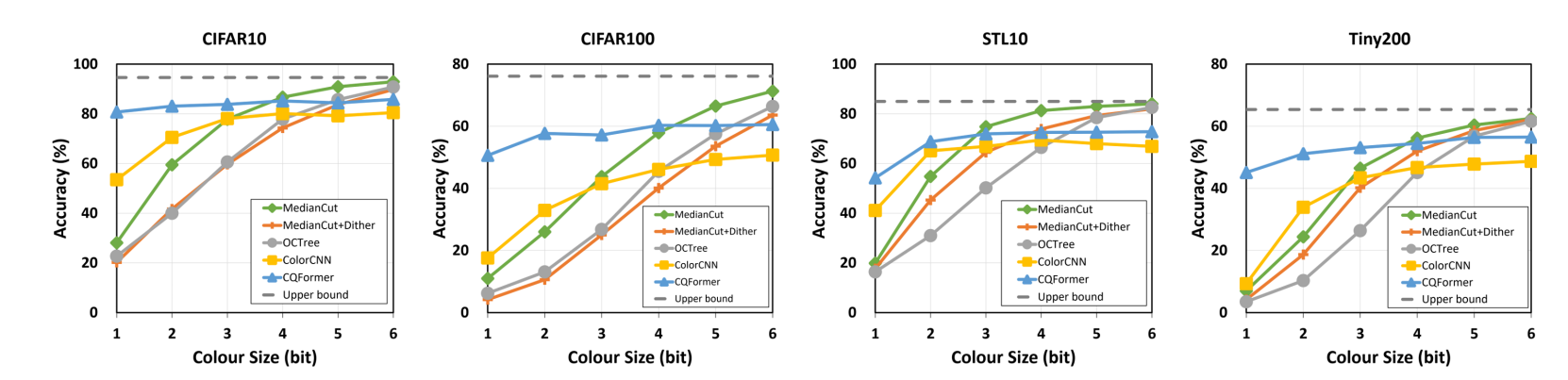
ICCV 2023 Oral | 人类语言演化中学习最优图像颜色编码
人类的语言是一种对复杂世界的高度简洁的编码,特别是语言中颜色的概念,成功地将原本极大的色彩空间(如256三次方真色彩空间)压缩至5到10种颜色。受此启发,来自上海交大,日本理化学研究所,东京大学 的研究人员,提出全新的基于视觉任务的色彩量化(colour quantisation)技术,利用深度学习重现人类数万年的颜色概念的演化。这项技术不但能推进文化人类学的研究,更是为网络量化(neural n

Keras复现 ICCV 2017论文 AOD—net
声明:本人是无神论者,信奉“神经网络黑盒不黑”。 本机配置: python 3.5(.1) keras 任何版本 tensorflow NVIDIA显卡+CUDA 8.0+cuDNN(训练时间CPU时间就很短,嫌弃predict速度较慢的建议使用GPU) opencv-python numpy 文章简介: Li, Boyi, et al. “Aod-net: All

ICCV 2021 | Anti-UAV 无人机跟踪竞赛启动!还有论文征稿
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 ICCV 2021 Anti-UAV Workshop & Challenge征稿啦,第二届“无人机跟踪”挑战赛等你来战! 作为计算机视觉领域的三大国际顶级会议之一,CCF A类国际会议ICCV 2021(IEEE International Conference on Computer Vision)将于2021年10月1
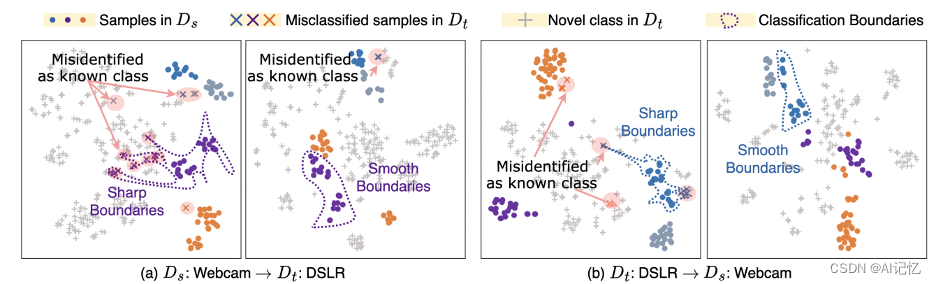
【ICCV Oral】SAN:利用软对比学习和全能分类器提升新类发现,FaceChain团队联合出品
本文提出了一个领域适应框架Soft-contrastive All-in-one Network(SAN),旨在高效、准确、原生地控制领域间新类别的发现和适应。具体来说,SAN采用了一种新颖的基于数据增强的软对比学习(SCL)损失来微调深度神经网络,并引入了全能(All-in-One, AIO)分类器,这种策略不仅有效地解决了数据增强中的视图噪声问题,还显著提高了新类别发现的能力,

ICCV 2023 | Ada3D: 利用动态推理挖掘3D感知任务中数据冗余性
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 以下内容来源于将门创投 作者:赵天辰 机构:清华大学电子工程系 研究方向:硬件友好的高效深度学习 论文标题:Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection 论文地址:https

【论文阅读】ICCV 2023 计算和数据高效后门攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言3.主要图表4.结论 一.论文信息 论文题目: Computation and Data Efficient Backdoor Attacks(计算和数据高效后门攻击) 论文来源: 2023-ICCV(CCF-A) 论文团队: 南洋理工大学&清华大学&中关村实验室 二.论文内容 1.摘要 针对深度神经网络(DNN)
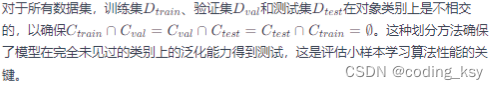
精读Relational Embedding for Few-Shot Classification (ICCV 2021)
Relational Embedding for Few-Shot Classification (ICCV 2021) 一、摘要 该研究提出了一种针对少样本分类问题的新方法,通过元学习策略来学习“观察什么”和“在哪里关注”。这种方法依赖于两个关键模块:自相关表示(SCR)和交叉相关注意力(CCA),来分别处理图像内部和图像之间的关系模式。 自相关表示(SCR)模块:用于捕捉单个图像内的结构

YOLOv5改进系列(28)——添加DSConv注意力卷积(ICCV 2023|用于管状结构分割的动态蛇形卷积)
【YOLOv5改进系列】前期回顾: YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析 YOLOv5改进系列(1)——添加SE注意力机制 YOLOv5改进系列(2)——添加CBAM注意力机制 YOLOv5改进系列(3)——添加CA注意力机制 YOLOv5改进系列(4)——添加ECA注意力机制 YOLOv5改进系列(5)——替换主干网络之 MobileNetV3 Y

一次性下载CVPR/ICCV/ECCV会议所有论文并提取论文标题重命名pdf文件
转自:https://blog.csdn.net/lcz200/article/details/80813988 动机 计算机视觉领域会议近年来论文接收数量暴增,论文多得看不过来。偶尔想起来,会兴致勃勃去下载个几篇看看。但每次看都要去官网下载,挺麻烦的。为何不直接把论文全部爬下来,有空时直接翻出来看?这篇博客要干的就是这个事情。 说明 以防万一有同学看到最后发现该博客解决不

【占用网络】SurroundOcc:基于环视相机实现3D语义占用预测 ICCV 2023
前言 本文分享“占用网络”方案中,来自ICCV 2023的SurroundOcc,它基于环视相机实现3D语义占用预测。 使用空间交叉注意力将多相机图像信息提升到3D体素特征,即3D体素Query到2D图像中查询融合特征的思想。 然后使用3D卷积逐步对体素特征进行上采样,并在多个层次特征图上进行损失监督。 论文地址:SurroundOcc: Multi-Camera 3D Occupancy

ICCV 2021 Workshop 盘点
自动驾驶视觉 2nd Autonomous Vehicle Vision (AVVision) Workshop Rui Fan, Nemanja Djuric, Rowan McAllister, Ioannis Pitas http://avvision.xyz/iccv21 条件改变的长程视觉定位 4th Workshop on Long-Term V
![UNIFYING DIFFUSION MODELS’ LATENT SPACE, WITHAPPLICATIONS TO CYCLEDIFFUSION AND GUIDANCE [ICCV 2023]](https://img-blog.csdnimg.cn/daf073d0da914379bb1fbe5f7ab0986f.png)
UNIFYING DIFFUSION MODELS’ LATENT SPACE, WITHAPPLICATIONS TO CYCLEDIFFUSION AND GUIDANCE [ICCV 2023]
论文链接https://arxiv.org/abs/2210.05559github链接https://github.com/ChenWu98/cycle-diffusion Abstract Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted

ICCV 2019 image-text相关论文总结
ICCV 2019 image-text相关论文总结 1. Local Relation Networks for Image Recognition issue: CNN用固定的filters来提取image feature,但image的空间分布是多变的,不能很好的满足image不同的空间分布。 method: 提出local relation layer,用于改进CNN。通过局部区域的关

ICCV 2019 图像描述(image caption)论文汇总
ICCV 2019 图像描述(image caption)论文汇总 1. Attention on Attention for Image Captioning issue: decoder不能很好的分辨attended vector和当前生成语义的关系 method: 再使用一个卷积attention机制,输入为attended vector和当前语义信息,生成attention gat
![超分重建—— ICCV, 2021 超分重建之 BSRGAN:测评 [ 上 ]](https://img-blog.csdnimg.cn/635b0714786f45889d6788d27284cce2.png#pic_center)
超分重建—— ICCV, 2021 超分重建之 BSRGAN:测评 [ 上 ]
🍊 各位读者小伙伴、春天快乐📆 最近更新:2022年3月15日🍊 专栏:超分重建-代码环境搭建-知识总结 ❤️【深度学习入门项目】❤️ 之 【超分重建】 初识 | 🚀学会【深度摸鱼】,就可以和学妹展示搬砖技巧了🚀 ❤️ 声明:这是一片大话超分重建的博文,非专业技术文章,请大佬轻踩 ❤️ 【带你了解】❤️ 💙 俘获芳心小技巧 ===》放大她的美❤️ 超分重建 =======
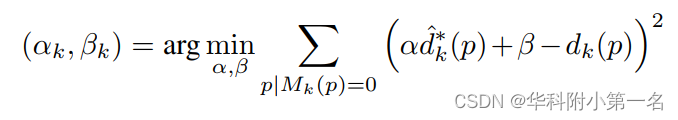
【论文简述】Learning Depth Estimation for Transparent and Mirror Surfaces(ICCV 2023)
一、论文简述 1. 第一作者:Alex Costanzino 2. 发表年份:2023 3. 发表期刊:ICCV 4. 关键词:深度感知、立体匹配、深度学习、分割、透明物体、镜子 5. 探索动机:透明或镜面(ToM)制成的材料,从建筑物的玻璃窗到汽车和电器的反射表面。对于利用计算机视觉在未知环境中操作的自主代理来说,这可能是一个艰巨的挑战。在空间人工智能涉及的众多任务中,对于计算机视觉算
【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
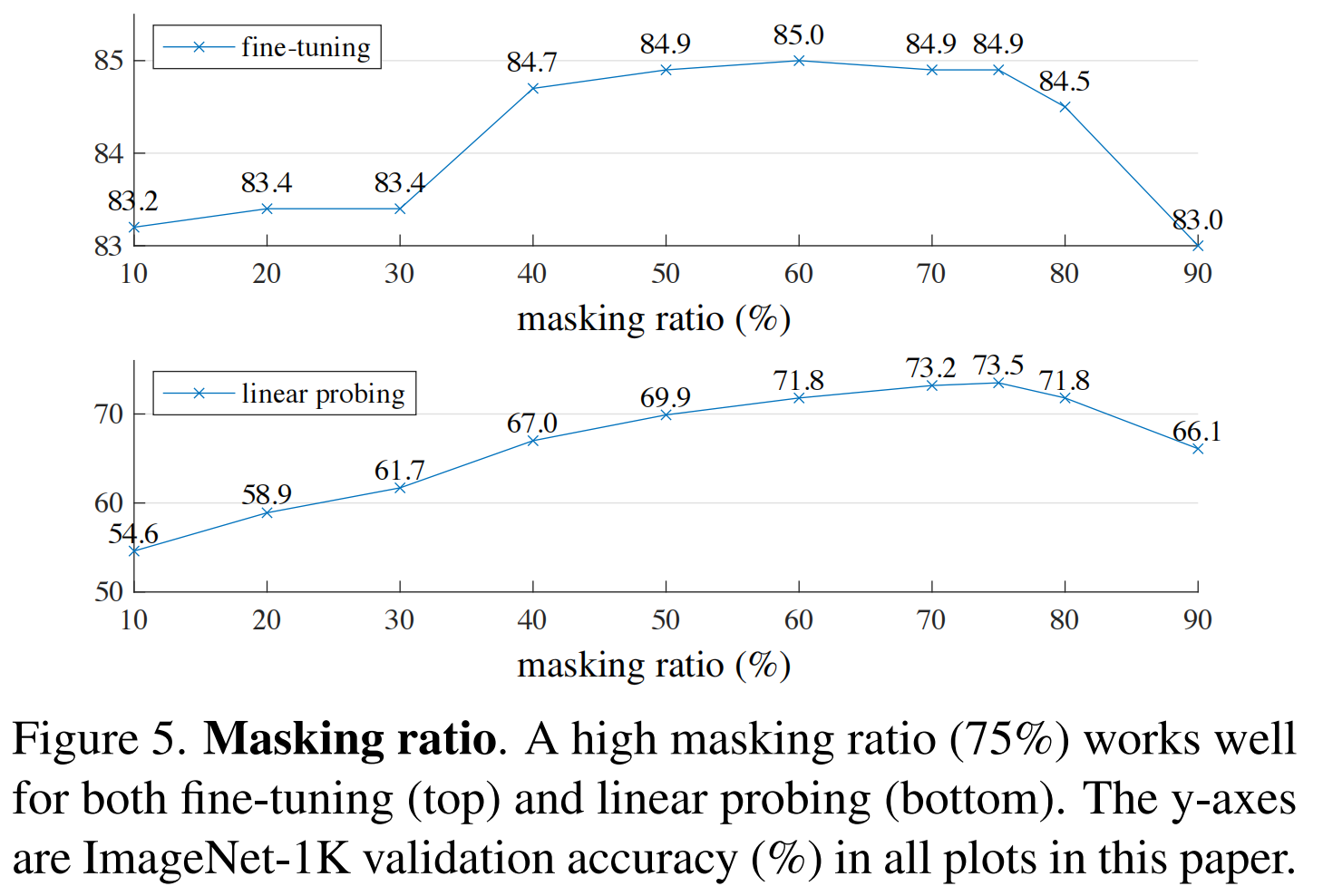
何凯明一作文章:https://arxiv.org/abs/2111.06377 感觉本文是一种新型的自监督学习方式 ,从而增强表征能力 本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。 恺明提出一种用于计
HEMlets Pose: Learning Part-Centric Heatmap Triplets for Accurate 3D Human Pose Estimation,ICCV 2019
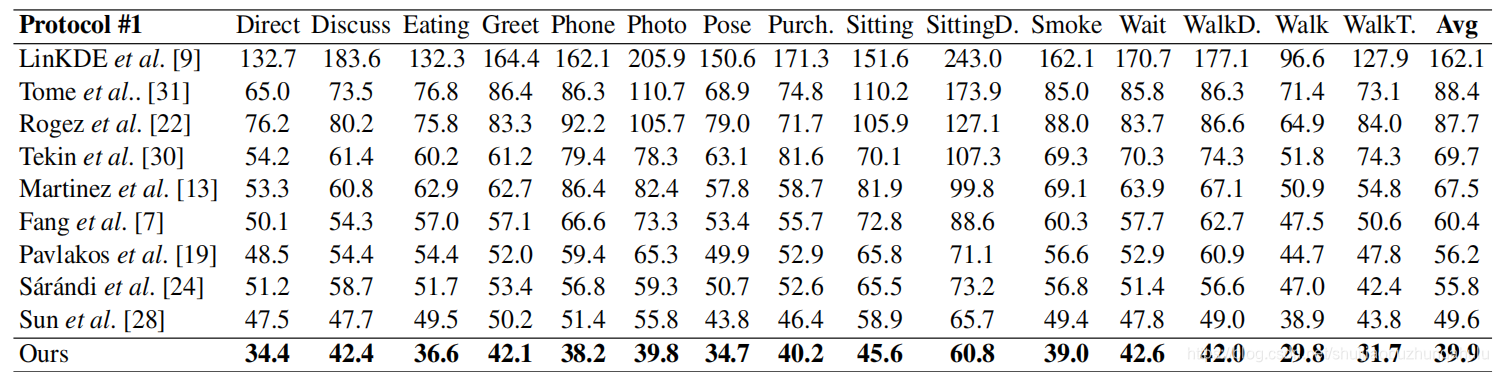
摘要:提出部件-中心-热图 三元组,构建空间体积,再用积分的方式实现端到端训练。 介绍:三个挑战(1)从图像推到3D pose的歧义性问题(2)针对回归问题,已有的方法,没有很好的平衡,人体表示与学习效率的关系(3)室外场景训练数据匮乏。 本文的提出的部件-中心热图三元组,将人体部件周围的体积空间极化,每个部件有两个关节点连接。其实,就是简单的一个2D heatmap的一张热图变成三张热图。

ICCV 2021 | 松弛Transformer:实现直接出框的时序动作检测
本文介绍我们组在2021年初公开在arxiv上的时序动作候选框生成工作RTD (Relaxed Transformer Decoders for Direct Action Proposal Generation)。 论文链接:https://arxiv.org/abs/2102.01894 代码地址:https://link.zhihu.com/?target=https%3A//githu
ICCV 2021 | MultiSports:面向体育运动场景的细粒度多人时空动作检测数据集
今天介绍一个我们新提出的时空动作检测数据集MultiSports,同时也是DeeperAction比赛的赛道二。首先介绍一下什么是时空动作检测任务 (Spatio-Temporal Action Detection): 输入一段未剪辑的视频 (untrimmed video),输出视频中人物的动作类别、动作发生的时序区间以及在此区间内的人物框。 现有数据集主要分为两大类: 以UCF101-2
ICCV 2021 | 低质图像化军师:让 IR测评摆脱高清依赖
图像质量评估是一个“古老”而重要的课题,有着广泛的应用和深远的影响。一些非常经典的图像质量评估方法,比如PSNR, SSIM,包括新兴的LPIPS,已经被广泛用来做图像复原任务的衡量指标。但是,这些指标通常需要高质量图像作参考,从而使得其在很多场景下无法适用。 本文针对图像复原任务的衡量问题,提出了一种更加具有可行性的图像质量评估方式:通过从低质量图像中提取有用信息,帮助衡量复原图像的质量。这一
![[ICCV论文阅读2019]Meta-Learning to Detect Rare Objects](https://img-blog.csdnimg.cn/2019123116342198.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTMyMDky,size_16,color_FFFFFF,t_70)
[ICCV论文阅读2019]Meta-Learning to Detect Rare Objects
摘要 小样本学习,即从很少的样本中学习新类的概念,对于实用的视觉识别系统来说是至关重要的。尽管大多数现有工作都集中在小样本的分类上,但我们朝着小样本目标检测迈出了一步,这是一个更具挑战性但尚未充分开发的任务。我们开发了一个概念上简单但功能强大的基于元学习的框架,该框架以统一,连贯的方式同时解决了小样本分类和小样本检测的问题。该框架利用具有丰富数据的基础类中有关“模型参数生成”的元级知识来促进新型