本文主要是介绍CvT(ICCV 2021)论文与代码解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper:CvT: Introducing Convolutions to Vision Transformers
official implementation:https://github.com/microsoft/CvT
出发点
该论文的出发点是改进Vision Transformer (ViT) 的性能和效率。传统的ViT在处理图像分类任务时虽然表现出色,但在数据量较小的情况下,其表现不如同等规模的卷积神经网络(CNN)。研究人员认为这是因为ViT缺乏CNN固有的一些有利特性,如对局部空间信息的捕捉能力。本文提出通过在ViT结构中引入卷积操作来弥补这一不足,以获得更好的性能和鲁棒性。
创新点
本文解决了如何在保持ViT优点(如动态注意力机制、全局上下文建模和更好的泛化能力)的同时,引入卷积神经网络的优点(如局部感受野、权重共享和空间下采样)。具体来说,论文通过引入卷积的方式来增强ViT的局部信息捕捉能力和计算效率,从而在各种图像分类任务中取得更好的表现。具体如下
- 卷积token embedding层:在ViT的结构中引入卷积embedding层,通过卷积操作将图像转换为token,同时保留局部空间信息。这种方法使模型能够在多个阶段逐步减少令token序列长度,同时增加token特征维度,类似于CNN的设计。
- 卷积projection:标准Transformer模块中的线性投影替换为卷积投影。通过深度可分离卷积操作,进一步捕捉局部空间上下文,并减少注意力机制中的语义模糊性。此外,卷积投影的步幅可用于对key和value矩阵进行下采样,从而显著提高计算效率。
- 无需位置编码:实验表明,CvT模型可以在不使用位置编码的情况下取得良好的性能,这简化了模型设计,尤其适用于处理高分辨率图像任务。
方法介绍

CvT的整体pipeline如图2所示。作者将两种基于卷积的operation引入Vision Transformer中,即Convolutional Token Embedding和Convolutional Projection。如图2(a)所示,借鉴了CNN采用了一个多个stage的层级设计,本文一共包含三个stage。每个stage包括两部分,首先输入图片(或reshape后的二维token map)经过Convolutional Token Embedding层的处理,具体是通过一个重叠的卷积实现。这使得每个stage可以逐渐减少token的数量(即特征分辨率)并增加token的宽度(即特征的维度),从而实现空间降采样并增加特征表示的丰富性。和之前的各种视觉Transformer不同,本文在这里并没有加上一个位置编码。接下来是堆叠的多个本文提出的Convolutional Transformer Block如图2(b)所示, 其中一个深度可分离卷积作为卷积投影分别作用于query、key和value。class token只在最后一个stage添加,最后通过一个MLP head得到最终的输出预测类别。
Convolutional Token Embedding
给定一张图片或前一个stage输出并reshape成二维的token map \(x_{i-1}\in \mathbb{R}^{H_{i-1}\times W_{i-1}\times C_{i-1}}\) 作为当前stage \(i\) 的输入,我们学习一个卷积 \(f(\cdot)\) 将 \(x_{i-1}\) 映射到新的token \(f(x_{i-1})\),卷积核大小为 \(s\times s\),步长为 \(s-o\),padding为 \(p\)。新的token map \(f(x_{i-1})\in \mathbb{R}^{H_i\times W_i\times C_i}\) 的高和宽分别为
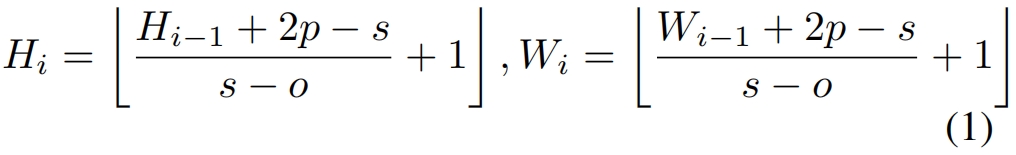
\(f(x_{i-1})\) 然后展平成 \(H_iW_i\times C_i\) 的shape并经过layer normalization处理,然后作为输入到stage \(i\) 的后续transformer block中。
Convolution Token Embedding层使得我们可以通过调整卷积的参数来调整每个stage的token特征维度和数量。通过这种方式,每个stage我们逐渐减少token序列的长度同时增加token特征的维度,使得token能够在越来越大的空间中表示越来越复杂的视觉模式,类似于CNN的特征层。
Convolutional Projection for Attention
本文提出的卷积映射层的目的是实现对局部context的额外建模,并通过对 \(K\) 和 \(V\) 矩阵降采样来提高效率。
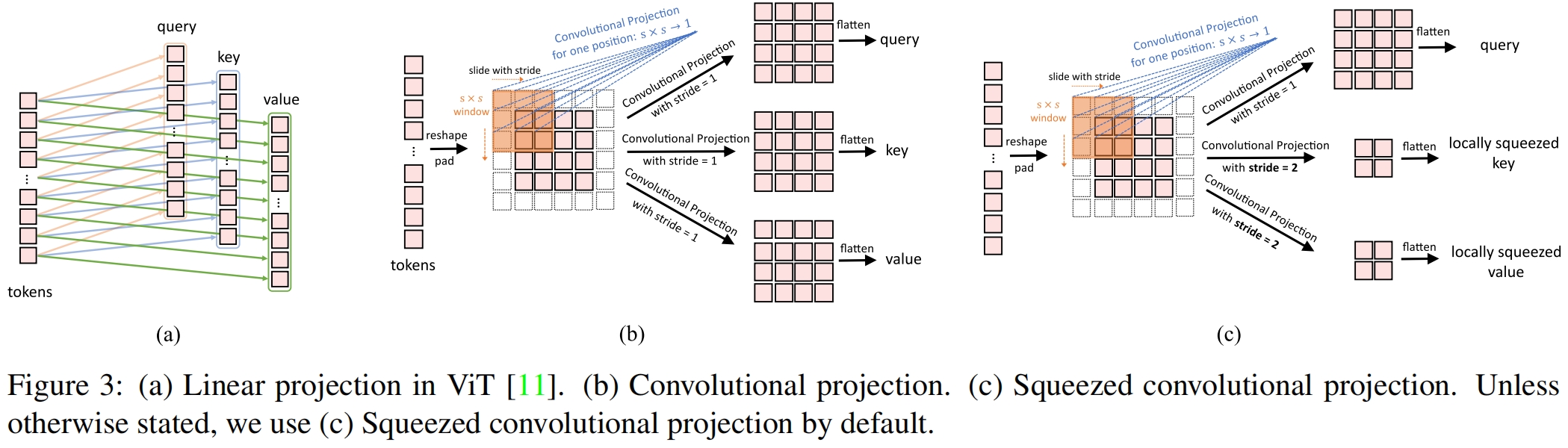
图3(a)展示了ViT中使用的position-wise线性投影,图3(b)展示了本文提出的 \(s\times s\) 卷积投影。如图3(b)所示,tokens首先reshape成一个2D token map,然后通过一个深度可分离卷积实现卷积投影。最后再将projected tokens展平成1D作为后续的输入,如下

其中 \(x_i^{q/k/v}\) 是 \(i\) 层 \(Q/K/V\) 矩阵的token输入,\(conv2d\) 是一个深度可分离卷积具体实现为:\(Depthwise\ Con2d\rightarrow BatchNorm2d\rightarrow Pointwise\ Conv2d\),\(s\) 表示卷积核大小。原始的position-wise线性投影可以通过1x1卷积实现,因此这里新的卷积投影可以看作是一种推广。
实验结果
作者设计三种不同size的模型如表2所示,其中CvT-X中的X表示模型总共的transformer block的数量。CvT-224中的W表示Wide。

表3是在ImageNet数据集上和其它SOTA模型的对比。

代码解析
这里的代码是官方实现,convolutional token embedding的代码如下,在每个stage的开始都会首先经过ConvEmbed,以cvt-13为例,一共3个stage,patch_size=[7, 3, 3],patch_stride=[4, 2, 2],patch_padding=[2, 1, 1]。
class ConvEmbed(nn.Module):""" Image to Conv Embedding"""def __init__(self,patch_size=7,in_chans=3,embed_dim=64,stride=4,padding=2,norm_layer=None):super().__init__()patch_size = to_2tuple(patch_size)self.patch_size = patch_sizeself.proj = nn.Conv2d(in_chans, embed_dim,kernel_size=patch_size,stride=stride,padding=padding)self.norm = norm_layer(embed_dim) if norm_layer else Nonedef forward(self, x):x = self.proj(x)B, C, H, W = x.shapex = rearrange(x, 'b c h w -> b (h w) c')if self.norm:x = self.norm(x)x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)return xAttention的代码如下,在forward函数中会首先调用forward_conv得到q、k、v,这里的forward_conv就是本文提出的conv projection,在函数_build_projection中method='dw_bn',因此三个投影都是通过深度可分离卷积实现的。在self.forward_conv后就是普通的计算attention的过程了。
class Attention(nn.Module):def __init__(self,dim_in,dim_out,num_heads,qkv_bias=False,attn_drop=0.,proj_drop=0.,method='dw_bn',kernel_size=3,stride_kv=1,stride_q=1,padding_kv=1,padding_q=1,with_cls_token=True,**kwargs):super().__init__()self.stride_kv = stride_kvself.stride_q = stride_qself.dim = dim_outself.num_heads = num_heads# head_dim = self.qkv_dim // num_headsself.scale = dim_out ** -0.5self.with_cls_token = with_cls_tokenself.conv_proj_q = self._build_projection(dim_in, dim_out, kernel_size, padding_q,stride_q, 'linear' if method == 'avg' else method)self.conv_proj_k = self._build_projection(dim_in, dim_out, kernel_size, padding_kv,stride_kv, method)self.conv_proj_v = self._build_projection(dim_in, dim_out, kernel_size, padding_kv,stride_kv, method)self.proj_q = nn.Linear(dim_in, dim_out, bias=qkv_bias)self.proj_k = nn.Linear(dim_in, dim_out, bias=qkv_bias)self.proj_v = nn.Linear(dim_in, dim_out, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim_out, dim_out)self.proj_drop = nn.Dropout(proj_drop)def _build_projection(self,dim_in,dim_out,kernel_size,padding,stride,method):if method == 'dw_bn':proj = nn.Sequential(OrderedDict([('conv', nn.Conv2d(dim_in,dim_in,kernel_size=kernel_size,padding=padding,stride=stride,bias=False,groups=dim_in)),('bn', nn.BatchNorm2d(dim_in)),('rearrage', Rearrange('b c h w -> b (h w) c')),]))elif method == 'avg':proj = nn.Sequential(OrderedDict([('avg', nn.AvgPool2d(kernel_size=kernel_size,padding=padding,stride=stride,ceil_mode=True)),('rearrage', Rearrange('b c h w -> b (h w) c')),]))elif method == 'linear':proj = Noneelse:raise ValueError('Unknown method ({})'.format(method))return projdef forward_conv(self, x, h, w):if self.with_cls_token:cls_token, x = torch.split(x, [1, h*w], 1)x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)if self.conv_proj_q is not None:q = self.conv_proj_q(x)else:q = rearrange(x, 'b c h w -> b (h w) c')if self.conv_proj_k is not None:k = self.conv_proj_k(x)else:k = rearrange(x, 'b c h w -> b (h w) c')if self.conv_proj_v is not None:v = self.conv_proj_v(x)else:v = rearrange(x, 'b c h w -> b (h w) c')if self.with_cls_token:q = torch.cat((cls_token, q), dim=1)k = torch.cat((cls_token, k), dim=1)v = torch.cat((cls_token, v), dim=1)return q, k, vdef forward(self, x, h, w):if (self.conv_proj_q is not Noneor self.conv_proj_k is not Noneor self.conv_proj_v is not None):q, k, v = self.forward_conv(x, h, w)q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads)k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads)v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads)attn_score = torch.einsum('bhlk,bhtk->bhlt', [q, k]) * self.scaleattn = F.softmax(attn_score, dim=-1)attn = self.attn_drop(attn)x = torch.einsum('bhlt,bhtv->bhlv', [attn, v])x = rearrange(x, 'b h t d -> b t (h d)')x = self.proj(x)x = self.proj_drop(x)return x
这篇关于CvT(ICCV 2021)论文与代码解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




