本文主要是介绍【论文简述】Learning Depth Estimation for Transparent and Mirror Surfaces(ICCV 2023),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、论文简述
1. 第一作者:Alex Costanzino
2. 发表年份:2023
3. 发表期刊:ICCV
4. 关键词:深度感知、立体匹配、深度学习、分割、透明物体、镜子
5. 探索动机:透明或镜面(ToM)制成的材料,从建筑物的玻璃窗到汽车和电器的反射表面。对于利用计算机视觉在未知环境中操作的自主代理来说,这可能是一个艰巨的挑战。在空间人工智能涉及的众多任务中,对于计算机视觉算法和深度网络来说,准确估计这些表面上的深度信息仍然是一个具有挑战性的问题。基于深度学习的深度传感技术,例如单目或立体网络,在提供足够的训练数据的情况下,有可能解决这一挑战。但具有透明对象的数据集很少提供真实深度注释,这些注释是通过非常密集的人为干预、图形引擎或基于ToM对象的CAD模型的可用性获得的。
- This difficulty arises because ToM surfaces introduce misleading visual information about scene geometry, which makes depth estimation challenging not only for computer vision systems but even for humans – e.g., we might not distinguish the presence of a glass door in front of us due to its transparency.
- On the one hand, the definition of depth itself might appear ambiguous in such cases: is depth the distance to the scene behind the glass door or to the door itself?
- On the other hand, as humans can deal with this through experience, depth sensing techniques based on deep learning, e.g., monocular or stereo networks, hold the potential to address this challenge given sufficient training data.
- As evidence of this, very few datasets featuring transparent objects provide ground-truth depth annotations, which have been obtained through very intensive human intervention, graphical engines, or based on the availability of CAD models for ToM objects.
6. 工作目标:准确感知ToM对象的存在(和深度)对传感技术和深度学习框架来说都是一个公开的挑战。
7. 核心思想:本文提出了一种简单而有效的获取训练数据的策略,从而极大地提高了处理ToM曲面的基于学习的深度估计框架的准确性。
- We propose a simple yet very effective strategy to deal with ToM objects. We trick a monocular depth estimation network by replacing ToM objects with virtually textured ones, inducing it to hallucinate their depths.
- We introduce a processing pipeline for fine-tuning a monocular depth estimation network to deal with ToM objects. Our pipeline exploits the network itself to generate virtual depth annotations and requires only segmentation masks delineating ToM objects – either human-made or predicted by other networks – thus getting rid of the need for any depth annotations.
- We show how our strategy can be extended to other depth estimation settings, such as stereo matching.
8. 实验结果:
Our experiments on the Booster dataset prove how monocular and stereo networks dramatically improve their prediction on ToM objects after being fine-tuned according to our methodology.
9.论文及代码下载:
https://openaccess.thecvf.com/content/ICCV2023/papers/Costanzino_Learning_Depth_Estimation_for_Transparent_and_Mirror_Surfaces_ICCV_2023_paper.pdf
https://openaccess.thecvf.com/content/ICCV2023/papers/Costanzino_Learning_Depth_Estimation_for_Transparent_and_Mirror_Surfaces_ICCV_2023_paper.pdf
二、实现过程
1. 实现思路
通过将ToM对象替换为形状相似的有纹理的人工制品,单目模型可能会被欺骗和诱导,以估计不透明物体的深度,理想情况下放置在场景中的同一位置。该方法可以通过描绘ToM对象,通过手动注释或分割网络,将其从图像中屏蔽,然后在被屏蔽区域内绘制虚拟纹理来实现。一方面,既然检测合适的ToM对象对我们的方法至关重要,手动标记无疑会产生最准确的选择,尽管它需要大量的注释成本。另一方面,依赖于分割网络将减轻这种成本:人们需要一些初始的人工注释来进行训练,但这将允许免费分割大量图像。不幸的是,我们的方法的整体有效性将不可避免地受到训练分割模型的准确性的影响。然而,我们认为,与深度标注相比,用分割掩码标注图像需要的工作量肯定要小得多。因此,我们决定探索上述两种方法。
读者可能会认为,根据我们的直觉,训练深度网络来处理ToM对象可能是不必要的——实际上,在估计深度之前,在部署时分割和绘制这些对象就足够了。然而,我们反驳说,这种方法将严重依赖于训练来分割ToM对象的模型的实际准确性,这并不适用于泛化。此外,它还会增加不可忽略的计算成本——即第二个网络的推理。相反,离线培训或微调过程允许利用人工注释——如果可用的话
-并且,潜在地,使训练的网络能够学习如何正确地估计ToM表面上的深度,并摆脱第二个网络,以及为其他深度估计框架设计高级策略,例如深度立体网络。我们的实验将突出前一种策略的效果是无效的,而我们通过使用我们的方法微调深度模型实现了精度的大幅提高。
在其余部分中,我们将描述处理ToM对象的方法。给定图像数据集I,在下图中描述了管道构建:I)表面标记,ii)修复(图像)和蒸馏,以及iii)虚拟标签上深度网络的微调。此外,我们还展示了如何修改它来微调深度立体匹配网络。

表面标记。对于任意图像Ik∈I,我们产生一个分割掩码Mk,将每个像素p分类为

通过将像素分别标记为1或0来判断它们是否属于ToM表面。这种分割掩码既可以通过人工标注获得,也可以通过分割网络Θ获得,如Mk = Θ(Ik)。
修复(图像)和蒸馏。给定一个图像Ik和它对应的分割掩码Mk,生成了一个增强图像I ~ k,应用修复操作将属于ToM对象的像素替换为颜色c:

然后,将I~k输入到单目深度网络Ψ,得到图像Ik的虚拟深度D~k。每一帧Ik的颜色都是随机采样的
。然而,根据图像内容的不同,某些颜色可能会产生无效效果,并增加场景的模糊性——例如,将白色像素嵌入位于白墙前面的透明物体中。为了防止这种情况的发生,对一组N个自定义颜色ci, i∈[0,N−1]进行采样,使用这些自定义颜色修复Ik,以便生成一组N个增强图像i~ki。然后,通过计算N个深度图之间的每像素中位数来获得最终的虚拟深度D~k


如图所示,在某些情况下,绘制的颜色可能与背景相似——例如,当使用单个灰色蒙版时,透明对象会消失——而通过聚合多色绘制,它是可见的。

虚拟标签的微调。到目前为止概述的步骤允许使用虚拟深度标签标记数据集I,这些标签不受ToM对象的模糊性的影响。然后,我们新标注的数据集可以用于训练或微调深度估计网络,从而使其能够鲁棒地处理上述困难的对象。具体来说,在训练过程中,原始图像Ik被输入到网络,并且预测深度D~k相对于从修复图像中获得的虚拟真实图D∗k进行优化。当处理ToM对象时,这个简单的管道可以显著提高单目深度估计网络的准确性。
扩展到深度立体匹配。管道可以适应微调深度立体模型,如图所示。

再一次,我们认为最先进的立体结构在处理ToM对象时已经展现了出色的泛化能力,因为匹配属于非朗伯曲面的像素的任务本质上是模糊的。因此,用单目深度估计网络来获得仅针对这些对象的虚拟深度注释。给定一个由立体对(Lk, Rk)组成的数据集S,从Lk中提取虚拟深度标签D∗k,并根据立体匹配的外参将它们三角化成视差D∗k。然后,通过将(Lk, Rk)输入到要微调的立体网络来预测基本视差图dk。最后,根据Mk将ToM对象的视差值替换为dk的视差值,Mk这次是在Lk上产生的。这个操作,即合并,定义为:

αk,βk为尺度因子和移位因子,作为单目预测是一个未知的尺度因子。αk, βk通过在dk上对不属于任何ToM对象的像素进行最小二乘估计估计(LSE)回归,也就是说,在Mk(p)=0:
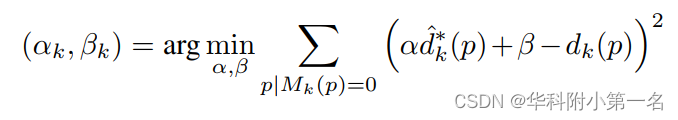
这篇关于【论文简述】Learning Depth Estimation for Transparent and Mirror Surfaces(ICCV 2023)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
