本文主要是介绍【ICCV Oral】SAN:利用软对比学习和全能分类器提升新类发现,FaceChain团队联合出品,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文提出了一个领域适应框架Soft-contrastive All-in-one Network(SAN),旨在高效、准确、原生地控制领域间新类别的发现和适应。具体来说,SAN采用了一种新颖的基于数据增强的软对比学习(SCL)损失来微调深度神经网络,并引入了全能(All-in-One, AIO)分类器,这种策略不仅有效地解决了数据增强中的视图噪声问题,还显著提高了新类别发现的能力,同时避免了分类器的过度自信问题。相比传统的无监督领域适应(UDA)方法,SAN展现了更强的特征转移能力和更高的新类别发现准确率,其中在ODA和UNDA任务上都取得了最先进的效果。同时,我们探讨了开放集领域适应(ODA)和通用领域适应(UNDA)的核心困难和评价指标,为后续研究提供了理论基础。

论文链接:
https://arxiv.org/abs/2211.11262
代码链接:
https://github.com/zangzelin/code_SAN
一、思考的起点
在当今的机器学习领域,领域适应已经成为了一个热门的研究方向,尤其是新类别的发现,这被视为迁移学习的一个重要应用。传统的无监督领域适应(UDA)方法在许多场景中已经证明了其有效性,但在实际应用中,我们发现它在标签稀缺的新领域中存在一些局限性。特别是在面对源领域和目标领域类别不完全重叠的情况时,传统方法往往显得力不从心。在此,源领域指的是我们已经拥有大量标签数据的领域,而目标领域则是我们希望模型能够适应但标签数据较少或完全没有的领域。这种观察促使我们重新思考:如何更有效地进行领域间的新类别发现和适应?我们需要一种方法,既能够充分利用源领域的知识,又能够灵活地适应目标领域的新类别。
二、工作亮点
新类别的发现在领域适应中面临两大核心难点:首先是如何学习一个统一的特征表征,使其能够跨领域有效;其次是如何设计一个新类别分类器,确保其在未知类别上的鲁棒性和准确性。为了解决上述问题,我们提出了一个全新的领域适应框架——Soft-contrastive All-in-one Network(SAN)。
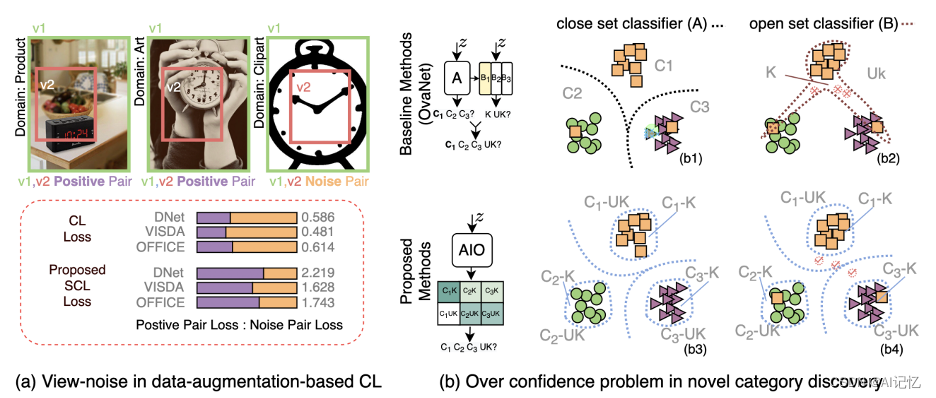
SAN的设计初衷是为了解决领域适应中的新类别发现问题。为此,我们首先引入了基于数据增强的软对比学习(SCL)损失。正如图1(a)所示,传统的对比学习方法在处理由于数据增强产生的视图噪声时存在问题。这种噪声会引入错误的梯度,从而损害网络的训练。此外,为所有领域找到合适的数据增强策略在面对具有巨大领域差异的UNDA数据时尤为困难。为了解决这个问题,我们提出了软对比学习(SCL)。SCL的目的是减弱视图噪声的影响,使模型能够更好地从正面对比对中学习。
然后,我们引入了全能(All-in-One, AIO)分类器。如图1(b)所示,传统的独立分类器在面对新类别时存在过度自信的问题,这导致了过于尖锐的分类边界。这种过度自信的分类边界在某些新类别上容易出错。为了解决这个问题,我们设计了AIO分类器。与传统的分类器不同,AIO分类器的决策过程更接近人类的判断方式。它假设要确定一个样本属于新类别,首先需要确定它不属于任何已知的类别。基于这个假设,我们定义了一个新的损失函数来训练AIO分类器。结果表明,与传统的分类器相比,AIO分类器具有更加平滑的分类边界,并且能够减少标签噪声的不良影响。
SCL损失的设计旨在高效、准确地控制领域间新类别的发现,通过这种策略,我们有效地解决了数据增强中的视图噪声问题。而AIO分类器则旨在解决传统分类器在新类别发现上的过度自信问题,使得模型在面对新类别时更为稳健和准确。
三、实验结果
在本研究中,我们采用了四个在领域适应领域中广受欢迎的数据集进行训练和测试,分别是:Office、OfficeHome、VisDA和DomainNet。这些数据集涵盖了多种真实世界的场景,为模型提供了丰富的训练和验证环境。为确保实验的公正性和可靠性,我们遵循了现有的协议来将数据集进行分类,具体地,数据被分为源私有、目标私有和共享类别三部分。这种细致的数据划分策略使我们能够更为准确地评估模型在新类别发现上的性能。通过在这些数据集上的广泛测试,我们的方法在新类别发现上展现了出色的性能,证明了其在面对未知类别时的鲁棒性和准确性。
我们对SAN进行了广泛的实验评估,特别是在ODA和UNDA任务上。
实验结果显示,SAN在特征转移能力和新类别发现准确率上都取得了最先进的效果,明显超越了现有的方法。这些实验不仅验证了SAN在领域适应任务上的优越性能,还为未来的研究提供了新的方向和基准。我们采用了多种评估指标,确保了实验结果的公正性和可靠性,从而为后续研究者提供了一个坚实的基础。
我们进一步进行了可视化分析来展示SAN的效果。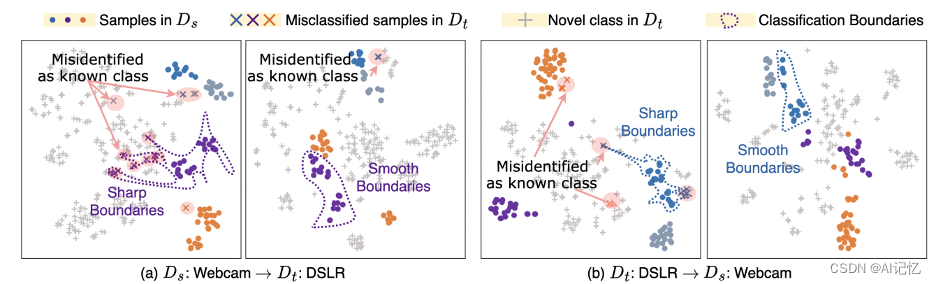
图中展示了特征的t-SNE嵌入可视化,其中颜色代表不同的类别。对于图(a)中的W域到D域设置和图(b)中的D域到W域设置,我们观察到基线方法在目标域的某些新类别上犯了错误(例如,由交叉标记的散点)。这可以归因于过度自信的分类器导致的过于尖锐的分类边界,从而输出了错误的测试结果。我们认为这是过度自信的结果。与此相反,SAN很好地处理了同一类别。从这些可视化中,我们可以清楚地看到SAN在特征空间中为不同的类别创建了更加分散和清晰的聚类,这证明了其在新类别发现上的优越性能。这种可视化展示进一步证明了SAN方法在克服过度自信问题上的有效性,为新类别提供了更为鲁棒和准确的分类。
这篇关于【ICCV Oral】SAN:利用软对比学习和全能分类器提升新类发现,FaceChain团队联合出品的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





