本文主要是介绍顶会最强的前20%!电影情感效应预测论文拿下ACMMM Oral收录!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文内容出自阿里文娱AI大脑北斗星团队,研究成果已发表在ACMMM 2022
论文名:Enlarging the Long-time Dependencies via RL-based Memory Network in Movie Affective Analysis
作者:张杰、赵寅、钱凯
背景
三流的导演拍故事,一流的导演拍情绪。纵观古往今外,经典的高分电影之所以经久不衰,无一不是因为引发了观众心理上的共情。尤其是在快节奏、高压力的现代生活中,观众观看影视剧的主要目的就是为了寻求情感上的满足与释放。因此,综合视听语言等因素,搭建一条合适的“情感线”是电影成功的关键。那么,如果我们可以在电影上线之前,提前预测电影对于观众的情感效应,刻画出这条“情感线”,对于电影的评估定级、剪辑优化等方面无疑有着巨大的帮助。为此,我们展开了电影情感效应预测方面的研究工作。
简介
电影情感效应分析旨在预测观众在观看电影时所产生的情感,其在电影内容理解、高潮检测、质量评估、情感多媒体检索等方面有着重要的应用。在情感计算领域,情感的标签可以分为两种:1是离散的情感标签,如开心、伤心等等;2是连续的情感模型,如使用最多的二维VA情感模型(如图1所示),其中Valence代表的是情感的正负,Arousal代表的是情感的强度,两者的取值均在-1到1之间。相比于离散的标签,连续的情感模型可以更细致全面地描述情感的各个维度,在学术界和工业界有着更加广泛的应用。因此,我们采用了VA情感模型,主要目标就是根据影视剧的内容,预测观众的VA情感。
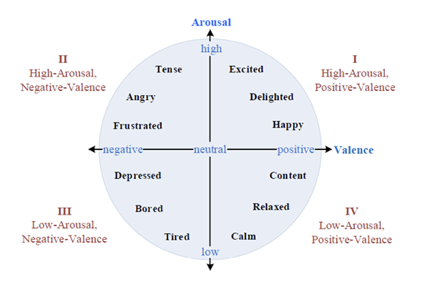
图1 VA情感模型
要正确地预测观众的情感,上下文信息十分关键,同样的一段场景在不同的情景下可能会产生不同的情感效应,比如同样一段打斗的画面,在犯罪剧中是令人紧张的,在喜剧中则可能是幽默风趣的。因此,有效地建模上下文信息对于电影的情感效应预测至关重要。
为了建模上下文信息,最常用的经典模型可以分为两种:循环神经网络(如LSTM[1]等)和Transformer[2]。然而,在面对电影这种动辄几千秒的长序列时,这些时序模型存在着一定的缺陷:
a. 循环神经网络的记忆能力有限,难以建模长时依赖
b. 循环神经网络采用的BPTT的更新方式存在梯度消失和爆炸的问题,此外其需要存储大量的中间变量,不适用于特别长的序列
c. Transformer的计算量随着时序的增加呈平方级增加,同样不适用于特别长的序列
受限于常用时序模型的这些缺陷,目前大部分的方案都是将电影切分成小片段,然后独立地去预测每个片段的情感。然而这种方式忽略了片段之间的联系,无法建模长时序的上下文信息,对于正确理解电影内容、判断电影情感的整体走势有着一定的阻碍。
为了解决这些问题,我们提出了基于强化学习的记忆网络,其核心在于利用记忆模块存储历史信息,并利用强化学习得到记忆模块的更新策略。如图2所示,我们方法存在以下优势:
a. 通过记忆模块提升了模型的记忆能力
b. 利用强化学习的时序差分法,减小了计算量和存储量,避免了梯度消失和爆炸的问题
c. 利用强化学习中的价值网络和策略网络,有效捕捉长时序依赖
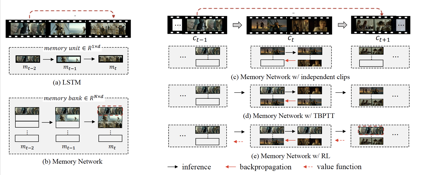
图2 基于强化学习的记忆网络优势示意图
为了验证我们方法的有效性,我们在多种任务的多个数据集上进行了实验,结果均达到了SOTA。
下面我们将对所提方案展开详细的介绍。
方案
模型的整体框架如图3所示:给定一个电影,我们将其划分成连续的片段 C = c 1 , c t , ⋯ , c T C={c_1,c_t,⋯,c_T} C=c1,ct,⋯,cT,对于一个电影片段 c t c_t ct,我们提取多模态特征,并将这些特征编码成向量表征 e t e_t et。然后向量表征 e t e_t et和历史记忆信息 m t − 1 m_{t-1} mt−1组成状态输入到策略网络μ中去,产生一系列的动作 a t a_t at,这些动作会用来选择性的更新记忆模块中的内容。然后基于更新后的记忆模块mt和向量表征 e t e_t et,作出最终的预测 y t y_t yt。预测结果的误差会作为奖励 r t r_t rt,指导价值网络Q学习未来的期望奖励,价值网络则会用来指导策略网络学习长时序依赖。
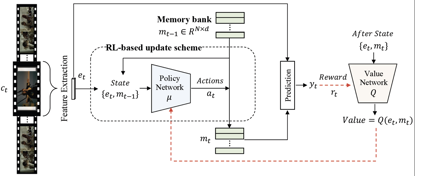
图3 模型整体框架
下面我们将对模型中的特征提取模块、基于强化学习的记忆网络部分、以及模型训练相关的内容进行详细的介绍
特征提取
为了得到富含情感信息的表征,我们提取了5种模态的特征:利用VGGish[3]提取音频特征;利用背景音乐情感模型提取bgm情感特征;利用在Places365[4]上预训练的VGG16[5]提取场景特征;利用OpenPose[6]的主干部分提取人物姿态特征;利用在RAF[7]上预训练的Xception[8]提取人物表情特征。我们将这些模态的特征在时间维度上对齐并做concat操作,然后利用LSTM来融合时序信息,并取最后一个时间步的隐藏状态作为电影片段的向量表征。
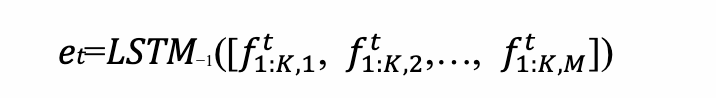
K代表的是每个电影片段的帧数,M代表的是模态的总数, f 1 : k : m t f_{1:k:m}^t f1:k:mt ∈ $R^{K×d_m} 代表的是提取的第 m 个模态的特征, [ ⋯ ] 代表的是 c o n c a t 操作, 代表的是提取的第m个模态的特征,[⋯]代表的是concat操作, 代表的是提取的第m个模态的特征,[⋯]代表的是concat操作,LSTM_{−1}$代表的是取LSTM最后一个时间步的
这篇关于顶会最强的前20%!电影情感效应预测论文拿下ACMMM Oral收录!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)