本文主要是介绍【CVPR19 超分辨率】(Oral)Second-order Attention Network for Single Image Super-Resolution,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天介绍一篇CPVR19的Oral文章,用二阶注意力网络来进行单图像超分辨率。作者来自清华深研院,鹏城实验室,香港理工大学以及阿里巴巴达摩院。
文章地址
github code
文章的出发点:现存的基于CNN的模型仍然面临一些限制:
- 大多数基于CNN的SR方法没有充分利用原始LR图像的信息,导致相当低的性能
- 大多数CNN-based models主要专注于设计更深或是更宽的网络,以学习更有判别力的高层特征,却很少发掘层间特征的内在相关性,从而妨碍了CNN的表达能力。
**文章的大体思路:**提出了一个深的二阶注意力网络SAN,以获得更好的特征表达和特征相关性学习。特别地,提出了一个二阶通道注意力机制SOCA来进行相关性学习。同时,提出了一个non-locally增强残差组NLRG来捕获长距离空间内容信息。
话不多说,直接看方法
方法
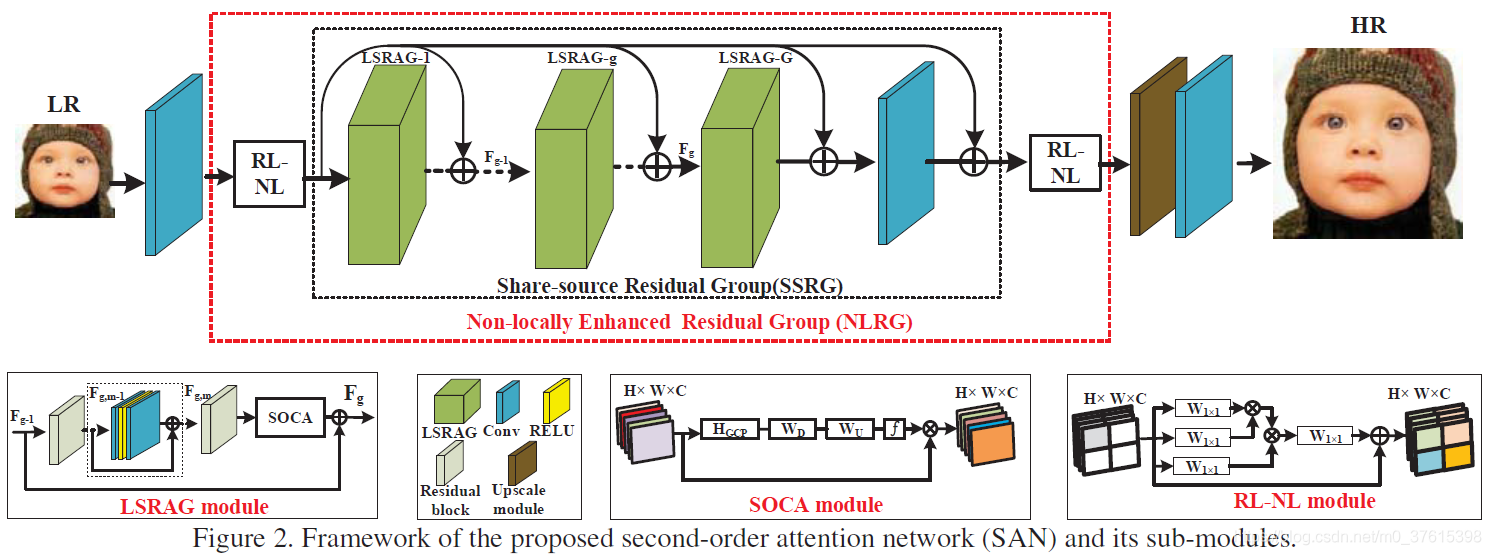
总体网络框架
首先,SAN主要分为四个部分,浅层特征提取,基于非局部增强残差组的深度特征提取,上采样模块以及重建模块。采用一层卷积层来提取浅层特征:
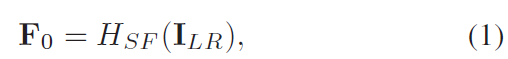
然后深度特征:
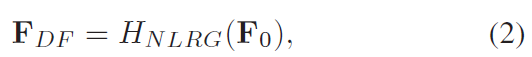
上采样特征:
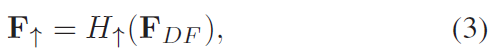
最后重建:
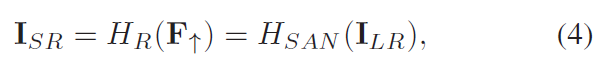
非局部增强残差组NLRG

NLRG包括数个区域级非局部模块RL-NL和一个同源残差组结构SSRG。
SSRG包括相当于就是G个局部模块LSRAG加上一个同源残差连接结构SSC,所谓同源残差连接,就是把LR的特征加到每个group的输入x中,这种连接不仅可以帮助深度CNN的训练,同时还可以传递LR图像中丰富的低频信息给high-level的层。
Wssc是一个可学习参数,一开始被设置为0。对于每个group来说,都会收到SSC传递过来的F0
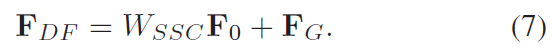
RL-NL模块
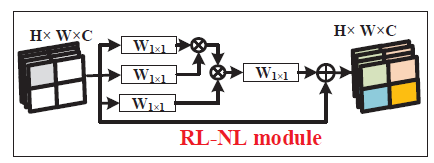
通常来说,non-local模块是用来在high-level任务中捕获整幅图像的长范围依赖的。但是,全局non-local操作可能会受限于:
- 全局non-local操作需要大量的计算量,如果特征size很大。
- 对于low-level的任务来说,在一定的区域范围中进行non-local操作被证明是有效的
因此,在SAN中,我们将图像划分为kxk大小,在每个region中进行non-local操作。
LSRAG模块
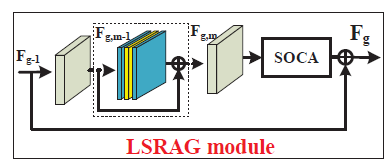
像其他的CNN模型一样,SAN也将网络模块化,每个LSRAG模块都用了local 的residual 连接
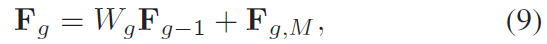
在LSRAG的末端,有一个SOCA模块,即二阶通道注意力机制。
SOCA
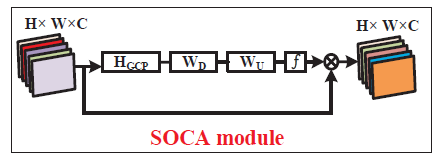
相比于SENet里面的通道attention使用的是一阶统计信息(通过全局平均池化),本SOCA探索了二阶特征统计的attention。方法:
- 协方差归一化:
协方差可以用来描述变量之间的相关性,所以对于HxWxC的特征,reshape为WH(C个维度),可以用协方差矩阵描述C个通道之间的相关性。采样协方差矩阵可以被计算得到:

其中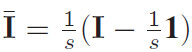 ,I和1分别是sxs的单位矩阵(对角线是1)和全1矩阵。
,I和1分别是sxs的单位矩阵(对角线是1)和全1矩阵。
对得到的协方差矩阵用半正定矩阵进行奇异值分解得到

U是一个正交矩阵,对角线元素都是奇异值(非递增)。
然后协方差归一化被转化为奇异值的秩:
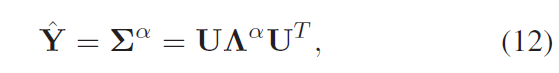
α是一个正数,论文中被设置为二分之一(如果是1则没有归一化)
channel attention
类似于SE Block,一层卷积用来降维(通常是十六分之一),一层恢复通道数。

这里的z是通过上面协方差归一化后得到的
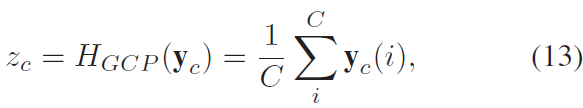
用牛顿迭代法求协方差归一化
因为原始的EIG在GPU上没办法快速运行,所以作者使用了牛顿迭代法逼近近似值。
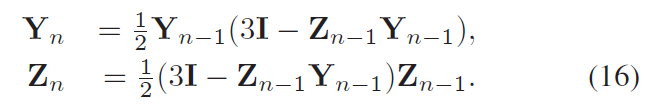
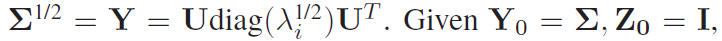
这篇关于【CVPR19 超分辨率】(Oral)Second-order Attention Network for Single Image Super-Resolution的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







