openmp专题

MPI与OpenMP 基本使用
MPI 注意,MPI是多进程的。 1.在程序中加入MPI支持: 加入头文件mpi.h,并在程序开头做初始化,退出时,关闭MPI。 2.编译: c文件用mpicc编译,c++文件用mpicxx编译。如: $ mpicxx how_to_use_mpi.cpp -o how_to_use_mpi 3.运行: mpirun使用mpi运行程序,-n参数指定进程数: $ m

OpenMP多线程基础使用
OpenMP 是一套 C++ 并行编程框架, 也支持 Forthan,是一个跨平台的多线程实现, 能够使串行代码经过最小的改动自动转化成并行的。具有广泛的适应性。这个最小的改动,有时候只是一行编译原语!具体实现是通过分析编译原语#pragma,将用原语定义的代码块,自动转化成并行的线程去执行。每个线程都将分配一个独立的id. 最后再合并线程结果。 可以并行的条件: 可拆分,代码和变量的前后不能相
NEON + OpenMP测试
在嵌入式的开发中,一直有在使用OpenMP和NEON加速,这次对二者的加速效果做了一个对比,包括二者的组合效果,因为只测试了加法的情况,其他的运行逻辑需要再实际使用中评估。 具体的测试代码如下: #include <QCoreApplication>#include <omp.h>#include <arm_neon.h>#include <QTime>#include <QDebug
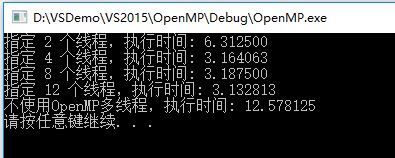
并行编程OpenMP基础及简单示例
OpenMP基本概念 OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的
OpenMP并行加速
OpenMP并行加速 1. 简介 OpenMP是一个编译器指令和库函数集合,主要是为共享式存储计算机并行程序设计使用的。 OpenMP的一个Parallelfor指令,就是标准的并行模式fork/join式并行模式,基本思想是,程序开始时只有一个主线程,程序中的串行部分都由主线程执行,并行的部分是通过派生其他线程来执行,但是如果并行部分没有结束时是不会执行串行部分的。也即OpenMP并行

GCC使用OpenMP
OpenMP是由OpenMP Architecture Review Board(ARB, 结构审议委员会)牵头提出的,是一种用于共享存储并行系统的编程标准。OpenMP并不是一种新语言,是对基本编成语言进行编译指导(compile directive)扩展,支持C/C++,由于OPENMP支持不同语言,所以具体语言不同回有所区别。 OpenMP标准中定义了指导指令,运行库和环境变量,使得用户可

OpenMP在ARM-Linux以及NDK中的编译和使用
以前对OpenCV在ARM-Linux, ARM-Android上的优化做了很多编译方面的努力,例如添加TBB支持,添加CUDA支持(Nvidia K1平台上)。这次突然听同事说增加了OpenMP选项后,在Windows+X86上有极大的优势,adaboost速度提高3倍。所以赶快在ARM-Android-NDK上测试一下。 0. OpenMP基础: OpenMP(Ope

openmp中的任务(task)
一、Task概念 Tasks are composed of: – code to execute – data environment – internal control variables (ICV) 并行程序会用一个线程按照程序代码的顺序生成任务; 在不附加何限制的情况下, 这些任务将放入到任务池中, 由空闲的线程取出执行, 如上图所示。换言之, 任务的默认执行顺序是未
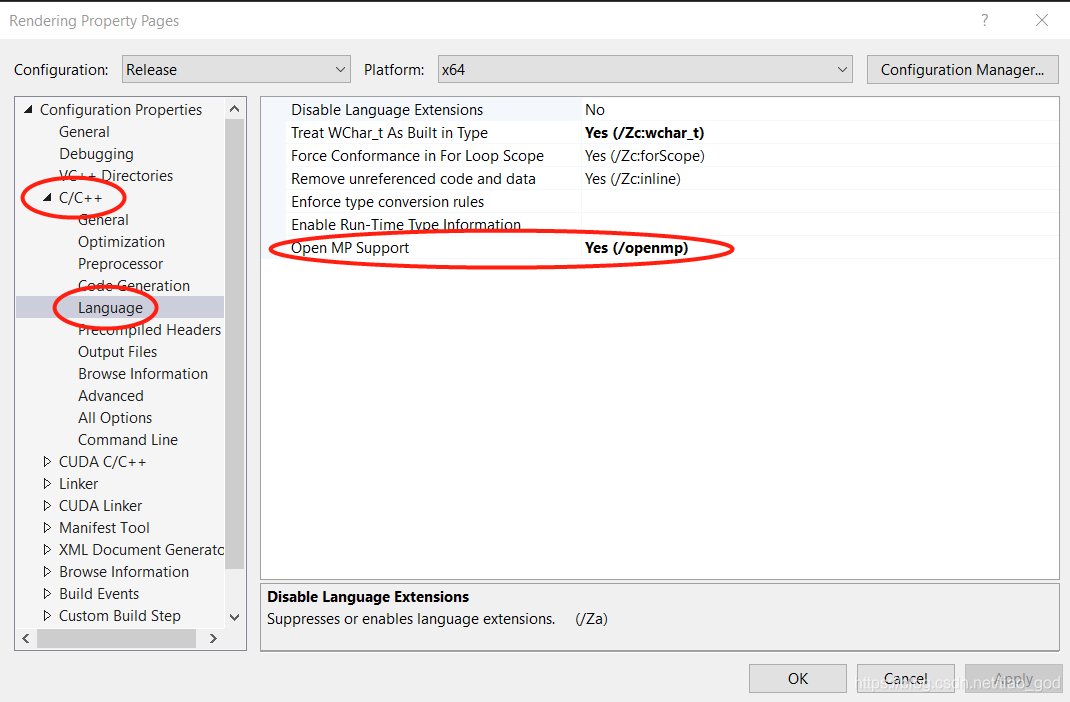
使用OpenMP进行多线程加速for循环
OpenMP是多线程优化库,可以对for循环有很好的加速作用。该库在VS里面是自带的,不需要自己配置。 开发环境: 首先在项目属性里设置支持OpenMP: 然后程序中加入头文件: #include <omp.h> 并在需要使用的地方写入: float renderFrame() {omp_set_num_threads(20); //设置线程的个数double start = om
OpenMP并行程序设计——for循环并行化详解
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/40018735 在C/C++中使用OpenMP优化代码方便又简单,代码中需要并行处理的往往是一些比较耗时的for循环,所以重点介绍一下OpenMP中for循环的应用。个人感觉只要掌握了文中讲的这些就足够了,如果想要学习OpenMP可以到网上查查资料。工欲善其事,必先利其器。如
并行计算 | OpenMP初识 hello world小实验
文章目录 📚并发与并行📚关于OpenMP🐇概述🐇加速原理🐇基本使用 📚hello world 小实验🐇代码🐇运行实现🐇PuTTy和FileZilla补充介绍 📚并发与并行 并发(Concurrency):系统的一种状态,其中多个任务同时在逻辑上处于活动状态。并行(Parallelism):系统的一种状态,其中多个任务实际上同时处于活动状态。 并行编程过程
OpenMP、MPI 和 MapReduce 对比
OpenMP和MPI是并行编程的两个手段,对比如下: OpenMP:线程级(并行粒度);共享存储;隐式(数据分配方式);可扩展性差;MPI:进程级;分布式存储;显式;可扩展性好。 OpenMP采用共享存储,意味着它只适应于SMP,DSM机器,不适合于集群。 MPI虽适合于各种机器,但它的编程模型复杂: 需要分析及划分应用程序问题,并将问题映射到分布式进程集合;需要解决

C++中OpenMP的使用方法
适用场景 OpenMP是一种用于共享内存并行系统的多线程程序设计方案;简单地说,OpenMP通过一种较为简单的使用方式,实现代码的CPU并行化处理,从而最大化利用硬件的多核性能,成倍地提升处理效率; OpenMP适用场景通常满足以下条件: 一个代码块被重复调用,且每次耗时较长,或者耗时较短但重复调用次数非常多;被重复调用的代码块中,每次处理的数据之间,独立性较强,不存在线程安全问题,或者只有少

OpenCV编程-OpenMP优化入门
找了个去雾源码,做了简单的优化: IplImage *quw1(IplImage *src,int block,double w){//图像分别有三个颜色通道IplImage *dst1=NULL;IplImage *dst2=NULL;IplImage *dst3=NULL;IplImage *imgroi1;//dst1的ROIIplImage *imgroi2;//dst2的ROI

OpenMP编程-调度优化
void test20(){#pragma omp parallel for schedule(static, 2) //static调度策略,for循环每两次迭代分成一个任务 for (int i = 0; i < 10; ++i) //被分成了5个任务,其中循环0~1,4~5,8~9分配给了第一个线程,其余的分配给了第二个线程 { std::cout << "Thread
OpenMP编程-同步机制
/* nowait用来取消栅障 */void test12(){#pragma omp parallel { #pragma omp for nowait for (int i = 0; i < 100; ++i) { std::cout << i << "+" << std::endl; } #pragma omp for for (int j = 0; j
OpenMP编程-互斥锁函数
//互斥锁同步 #pragma opm atomic x< + or * or - or * or / or & or | or << or >> >=exprvoid test9(){int sum = 0; std::cout << "Before: " << sum << std::endl; omp_set_num_threads(3); #pragma
OpenMP编程-数据约束
/*多个线程的执行结果通过reduction中声明的操作符进行计算,以加法操作符为例:假设sum的初始值为10,reduction(+: sum)声明的并行区域中每个线程的sum初始值为0(规定),并行处理结束之后,会将sum的初始化值10以及每个线程所计算的sum值相加。 */void test8(){int sum = 0; std::cout << "Befo
OpenMP编程-数据传递
//分配四个线程,做多线程for循环void test2(){const int NUMBER = 100; int* dataA = new int[NUMBER]; int* dataB = new int[NUMBER]; for (int i= 0; i < NUMBER; i++) { dataA[i] = i+1; dataB[i] = 2*(i+1); }

OpenMP编程-并行循环
两种形式如下: //for循环并行化声明形式1#pragma omp parallel forfor (int i=0;i<10;i++){cout<<i<<" "<< omp_get_thread_num()<<endl;} //for循环并行化声明形式2#pragma omp parallel { #pragma omp for for (int i = 0; i <
OpenMP编程-库函数
VS2008 MP库函数,调出mpi.h库,找到相关的源码如下: // 设置并行线程数 _OMPIMP void _OMPAPIomp_set_num_threads(int _Num_threads);// 获取当前并行线程数 _OMPIMP int _OMPAPIomp_get_num_threads(void);// 获取当前系统最大可并行运行的线程数 _OMPIMP

OpenMP task construct 实现原理以及源码分析
OpenMP task construct 实现原理以及源码分析 前言 在本篇文章当中主要给大家介绍在 OpenMP 当中 task 的实现原理,以及他调用的相关的库函数的具体实现。在本篇文章当中最重要的就是理解整个 OpenMP 的运行机制。 从编译器角度看 task construct 在本小节当中主要给大家分析一下编译器将 openmp 的 task construct 编译成什么样

并行计算(MPI + OpenMP)
文章目录 并行计算MPI(进程级并行)基本结构数据类型点对点通信阻塞非阻塞非连续数据打包 聚合通信Communicator & Cartisen Grid OpenMP(线程级并行)简介基本制导语句worksharing constructSectionsSingleFor 临界区 & 原子操作Task 并行计算 并行类型: 进程级并行:网络连接,内存不共享线程级并行:共享内

Opencv(C++)学习 TBB与OPENMP的加速效果实验与ARM上的实践(二)
在上一篇文章中,我们成功验证了Intel Threading Building Blocks (TBB) 与 OpenMP 在多线程并行处理方面的加速潜力。为了更深入地理解这些技术在实际应用场景中的效能提升,接下来我们将目光转向目标开发板环境,进一步探究这两种框架在嵌入式系统上的实际加速效果。 一、OPENMP加速效果测试 在探讨OPENMP对性能提升的影响时,我们首先遇到了一个有趣的插曲。通常情
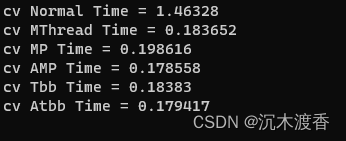
Opencv(C++)学习 TBB与OPENMP的加速效果实验与ARM上的实践
背景:在某个嵌入式上的图像处理项目功能开发告一段落,进入性能优化阶段。尝试从多线程上对图像处理过程进行加速。经过初步调研后,可以从OPENMP,TBB这两块进行加速,当前项目中有些算法已采用多线程加速,这次主要是对比以上两个加速模块与多线程加速效果的对比。现在PC上实验,然后再移植相关库。 环境准备:WIN11 ,VS2022 ,Debug 64 1、编译OPENCV。 经测试,编译过程是否选择
OpenMP环境配置222
目录 OpenMP环境配置 MPI环境配置欧拉黎曼函数的K阶近似OpenMPuuuu欧拉黎曼函数的K阶近似MPI生命游戏(Game of life)参考资料 OpenMP环境配置 MPI环境配置 欧拉黎曼函数的K阶近似OpenMP #include <stdio.h>#include <stdlib.h>#include <math.h>#include <om