本文主要是介绍并行编程OpenMP基础及简单示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenMP基本概念
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。
OpenMP缺点:
1:作为高层抽象,OpenMp并不适合需要复杂的线程间同步和互斥的场合;
2:另一个缺点是不能在非共享内存系统(如计算机集群)上使用。在这样的系统上,MPI使用较多。
OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
- parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for:parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
相应的OpenMP子句为:
private:指定一个或多个变量在每个线程中都有它自己的私有副本;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
copyin:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
default:用来指定并行域内的变量的使用方式,缺省是shared。
API函数
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP API函数以及说明:
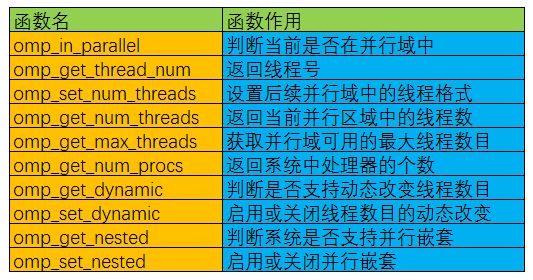
环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量:
- OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
简单示例之parallel使用
parallel制导指令用来创建并行域,后边要跟一个大括号将要并行执行的代码放在一起:
注意对于C/C++,你通常需要包含头文件<omp.h>,并且是大小写敏感的。
[cpp] view plain copy
- #include<iostream>
- #include <omp.h>
- using namespace std;
- void main()
- {
- #pragma omp parallel
- {
- cout << "Test" << endl;
- }
- system("pause");
- }
执行以上程序有如下输出:
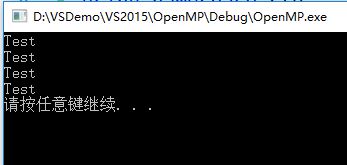
程序打印出了4个“Test”,说明parallel后的语句被4个线程分别执行了一次,4个是程序默认的线程数,还可以通过子句num_threads显式控制创建的线程数:
[cpp] view plain copy
- #include<iostream>
- #include"omp.h"
- using namespace std;
- void main()
- {
- #pragma omp parallel num_threads(6)
- {
- cout << "Test" << endl;
- }
- system("pause");
- }
编译运行有如下输出:
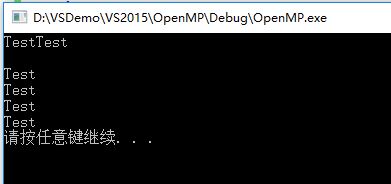
程序中显式定义了6个线程,所以parallel后的语句块分别被执行了6次。第二行的空行是由于每个线程都是独立运行的,在其中一个线程输出字符“Test”之后还没有来得及换行时,另一个线程直接输出了字符“Test”。
简单示例之parallel for使用
使用parallel制导指令只是产生了并行域,让多个线程分别执行相同的任务,并没有实际的使用价值。parallel for用于生成一个并行域,并将计算任务在多个线程之间分配,从而加快计算运行的速度。可以让系统默认分配线程个数,也可以使用num_threads子句指定线程个数。
[cpp] view plain copy
- #include<iostream>
- #include"omp.h"
- using namespace std;
- void main()
- {
- #pragma omp parallel for num_threads(6)
- for (int i = 0; i < 12; i++)
- {
- printf("OpenMP Test, 线程编号为: %d\n", omp_get_thread_num());
- }
- system("pause");
- }
运行输出:
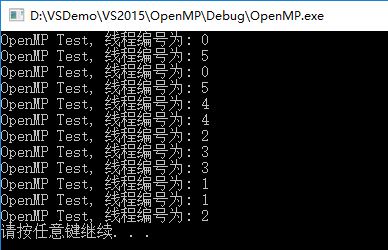
上边程序指定了6个线程,迭代量为12,从输出可以看到每个线程都分到了12/6=2次的迭代量。
备注:如果for里面比较简单(执行时间短) ,不建议使用多线程并发, 因为 线程间的调度 也会比较耗时,是一个不小的开销。
OpenMP效率提升以及不同线程数效率对比
[cpp] view plain copy
- #include<iostream>
- #include"omp.h"
- using namespace std;
- void test()
- {
- for (int i = 0; i < 80000; i++)
- {
- }
- }
- void main()
- {
- float startTime = omp_get_wtime();
- //指定2个线程
- #pragma omp parallel for num_threads(2)
- for (int i = 0; i < 80000; i++)
- {
- test();
- }
- float endTime = omp_get_wtime();
- printf("指定 2 个线程,执行时间: %f\n", endTime - startTime);
- startTime = endTime;
- //指定4个线程
- #pragma omp parallel for num_threads(4)
- for (int i = 0; i < 80000; i++)
- {
- test();
- }
- endTime = omp_get_wtime();
- printf("指定 4 个线程,执行时间: %f\n", endTime - startTime);
- startTime = endTime;
- //指定8个线程
- #pragma omp parallel for num_threads(8)
- for (int i = 0; i < 80000; i++)
- {
- test();
- }
- endTime = omp_get_wtime();
- printf("指定 8 个线程,执行时间: %f\n", endTime - startTime);
- startTime = endTime;
- //指定12个线程
- #pragma omp parallel for num_threads(12)
- for (int i = 0; i < 80000; i++)
- {
- test();
- }
- endTime = omp_get_wtime();
- printf("指定 12 个线程,执行时间: %f\n", endTime - startTime);
- startTime = endTime;
- //不使用OpenMP
- for (int i = 0; i < 80000; i++)
- {
- test();
- }
- endTime = omp_get_wtime();
- printf("不使用OpenMP多线程,执行时间: %f\n", endTime - startTime);
- startTime = endTime;
- system("pause");
- }
以上程序分别指定了2、4、8、12个线程和不使用OpenMP优化来执行一段垃圾程序,输出如下:
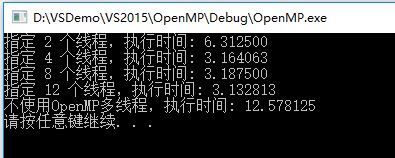
可见,使用OpenMP优化后的程序执行时间是原来的1/4左右,并且并不是线程数使用越多效率越高,一般线程数达到4~8个的时候,不能简单通过提高线程数来进一步提高效率。
for 循环语句中,书写是需要按照一定规范来写才可以的,即for循环小括号内的语句要按照一定的规范进行书写,for语句小括号里共有三条语句
for( i=start; i < end; i++)
i=start; 是for循环里的第一条语句,必须写成 “变量=初值” 的方式。如 i=0
i < end;是for循环里的第二条语句,这个语句里可以写成以下4种形式之一:
变量 < 边界值
变量 <= 边界值
变量 > 边界值
变量 >= 边界值
如 i>10 i< 10 i>=10 i>10 等等
最后一条语句i++可以有以下9种写法之一
i++
++i
i--
--i
i += inc
i -= inc
i = i + inc
i = inc + i
i = i –inc
例如i += 2; i -= 2;i = i + 2;i = i - 2;都是符合规范的写法。
sections和section指令的用法
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行。用法如下:
#pragma omp [parallel] sections [子句]
{
#pragma omp section
{
代码块
}
}
先看一下以下的例子代码:
void main(int argc, char *argv)
{
#pragma omp parallel sections {
#pragma omp section
printf(“section 1 ThreadId = %d/n”, omp_get_thread_num());
#pragma omp section
printf(“section 2 ThreadId = %d/n”, omp_get_thread_num());
#pragma omp section
printf(“section 3 ThreadId = %d/n”, omp_get_thread_num());
#pragma omp section
printf(“section 4 ThreadId = %d/n”, omp_get_thread_num());
}
执行后将打印出以下结果:
section 1 ThreadId = 0
section 2 ThreadId = 2
section 4 ThreadId = 3
section 3 ThreadId = 1
从结果中可以发现第4段代码执行比第3段代码早,说明各个section里的代码都是并行执行的,并且各个section被分配到不同的线程执行。
使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section过长就达不到并行执行的效果了。
上面的代码也可以改写成以下形式:
void main(int argc, char *argv)
{
#pragma omp parallel {
#pragma omp sections
{
#pragma omp section
printf(“section 1 ThreadId = %d/n”, omp_get_thread_num());
#pragma omp section
printf(“section 2 ThreadId = %d/n”, omp_get_thread_num());
}
#pragma omp sections
{
#pragma omp section
printf(“section 3 ThreadId = %d/n”, omp_get_thread_num());
#pragma omp section
printf(“section 4 ThreadId = %d/n”, omp_get_thread_num());
}
}
执行后将打印出以下结果:
section 1 ThreadId = 0
section 2 ThreadId = 3
section 3 ThreadId = 3
section 4 ThreadId = 1
这种方式和前面那种方式的区别是,两个sections语句是串行执行的,即第二个sections语句里的代码要等第一个sections语句里的代码执行完后才能执行。
用for语句来分摊是由系统自动进行,只要每次循环间没有时间上的差距,那么分摊是很均匀的,使用section来划分线程是一种手工划分线程的方式,最终并行性的好坏得依赖于程序员。
本篇文章中讲的几个OpenMP指令parallel, for, sections, section实际上都是用来如何创建线程的,这种创建线程的方式比起传统调用创建线程函数创建线程要更方便,并且更高效。
当然,创建线程后,线程里的变量是共享的还是其他方式,主线程中定义的变量到了并行块内后还是和传统创建线程那种方式一样的吗?创建的线程是如何调度的?等等诸如此类的问题到下一篇文章中进行讲解。
CRITICAL指令
目标:
- CRITICAL指令指定该区块一次只能由一个线程执行。
格式:
#pragma omp critical [ name ] newlinestructured_block- 1
- 2
- 3
注意事项:
- 如果一个线程当前正在CRITICAL区域内执行,如果另一个线程到达CRITICAL区域并尝试执行它,那么后到的线程将被阻塞,直到第一个线程退出该CRITICAL区域。
- 可选名称允许多个CRITICAL区块同时存在:1)名称将被作为全局标识符。具有相同名字的不同CRITICAL区块将会被认为是同一区块;2)所有匿名的CRITICAL区块将会被认为是同一个区块。
限制:
- 分支进出(goto)CRITICAL区块是非法的。
示例: 组内所有的线程都试图去并行执行。但是由于CRITICAL区块的存在,任何时刻最多只能有一个线程去执行自增操作。
#include <omp.h>main(int argc, char *argv[]) {int x = 0;#pragma omp parallel shared(x) {#pragma omp critical x = x + 1;} /* end of parallel region */
}BARRIER指令
目标:
- BARRIER指令同步组内的所哟线程;
- 当到达一个BARRIER指令处时,一个线程将在该处等待直到所有线程到达该处。然后所有线程开始并发执行barrier之后的代码。
格式:
#pragma omp barrier newline- 1
限制:
- 所有组内的线程必须执行BARRIER区域内的代码;
- 对于组内的线程,遇到工作共享区域和屏障区域的顺序必须相同。
ATOMIC指令
目标:
- ATOMIC指令指定特定的内存位置必须为原子更新,而不是让多个线程尝试写入它。事实上,该指令提供了一个最小单位的CRITICAL区域。
格式:
#pragma omp atomic newlinestatement_expression- #pragma omp atomic //可以看到atomic的操作仅能用于两种情况, 否则报错: 1. 自加减操作 2.移位操作
sum <<= 1; // sum++;
限制:
- 该指令仅仅适用于紧随于其后的一行执行语句;
- 该指令必须遵从特定的语法格式。请参考最新OpenMP标准对其定义。
REDUCTION实例:向量点乘 (并行线程 求和)
- 并行循环迭代将相同大小的块分给团队中的每个线程(SHEDULE STATIC);
- 在并行循环结构的末尾,所有线程都将添加“result”的值来更新主线程的全局副本。
#include <omp.h>main(int argc, char *argv[]) {int i, n, chunk;float a[100], b[100], result;/* Some initializations */n = 100;chunk = 10;result = 0.0;for (i=0; i < n; i++) {a[i] = i * 1.0;b[i] = i * 2.0;}#pragma omp parallel for default(shared) private(i) \ schedule(static,chunk) reduction(+:result) for (i=0; i < n; i++) {result = result + (a[i] * b[i]);}printf("Final result= %f\n",result);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
限制条件:
- 列表项的类型必须对缩减运算符有效;
- 列表项/变量不能被声明为共享或者私有;
- 规约操作可能不满足实数的结合律;
- 有关其它限制,请参阅OpenMP API标准。
附录A:运行时库函数
OMP_SET_NUM_THREADS
目标:
- 设置将在下一个并行区域中使用的线程数,其值必须是一个正整数。
格式:
#include <omp.h>
void omp_set_num_threads(int num_threads)- 1
- 2
注意事项:
- 动态线程机制将会修改此例程的效果:
- 启用:指定动态线程机制可以用于并行区域的最大线程数;
- 禁用:指定在下次调用此例程之前正确使用的线程数。
- 该例程只能从代码的串行部分调用。
- 此调用优先于OMP_NUM_THREADS环境变量。
OMP_GET_NUM_THREADS
目标:
- 返回当前组在执行并行区域时所调用的线程数。
格式:
#include <omp.h>
int omp_get_num_threads(void)- 1
- 2
注意事项及限制条件:
- 如果这个调用是从程序的串行部分或者被序列化的嵌套并行区域进行的,它将返回1。
- 默认的线程数是依赖于具体实现的。
OMP_GET_MAX_THREADS
目标:
- 返回调用OMP_GET_NUM_THREADS函数可以返回的最大值。
#include <omp.h>
int omp_get_max_threads(void)- 1
- 2
注意事项及限制条件:
- 通常反映由OMP_NUM_THREADS环境变量或者OMP_SET_NUM_THREADS()库函数例程设置的线程数。
- 可以从串行和并行的代码区域调用。
OMP_GET_THREAD_NUM
目标:
- 返回队列中的线程的线程号。改数字将在0和OMP_GET_NUM_THREADS-1之间。组内的主线程的线程号是0。
格式:
#include <omp.h>
int omp_get_thread_num(void)- 1
- 2
注意事项及限制条件:
- 如果从嵌套的并行区域或者串行区域调用,则此函数将返回0。
OMP_GET_THREAD_LIMIT
目标:
- 返回可用于程序的最大OpenMP线程数。
格式:
#include <omp.h>
int omp_get_thread_limit (void)- 1
- 2
注意事项:
- 可同时参考OMP_THREAD_LIMIT环境变量。
OMP_GET_NUM_PROCS
目标:
- 返回程序可用的处理器个数。
格式:
#include <omp.h>
int omp_get_num_procs(void)- 1
- 2
OMP_IN_PARALLEL
目标:
- 可以调用以确定正在执行的代码段是否是并行的。
格式:
#include <omp.h>
int omp_in_parallel(void)- 1
- 2
注意事项及限制条件:
- 对于C/C++,如果并行,它将返回非零整数,否则将返回0。
OMP_SET_DYNAMIC
目标:
- 启用或者禁用可执行并行区域的线程数(由运行时系统)的动态调整。
格式:
#include <omp.h>
void omp_set_dynamic(int dynamic_threads)- 1
- 2
注意事项及限制条件:
- 对C/C++,如果dynamic_threads计算为非零值,则启用机制,否则禁用。
- OMP_SET_DYNAMIC子例程优先于OMP_DYNAMIC环境变量。
- 默认设置取决于具体实现。
- 必须从程序的串行部分开始调用。
OMP_GET_DYNAMIC
目标:
- 用于确定是否启用了动态线程调整。
格式:
#include <omp.h>
int omp_get_dynamic(void)- 1
- 2
注意事项及限制条件:
- 对于C/C++,如果启用了动态线程调整,则返回非零值,否则返回0。
OMP_SET_NESTED
目标:
- 用于启用或者禁用嵌套并行。
格式:
#include <omp.h>
void omp_set_nested(int nested)- 1
- 2
注意事项及限制条件:
- 对于C/C++,如果嵌套求值为非0,嵌套并行将启用,否则禁用。
- 默认值为禁用嵌套并行。
- 此调用优先于OMP_NESTED环境变量。
OMP_GET_NESTED
目标:
- 用于确定嵌套并行是否启用。
格式:
#include <omp.h>
int omp_get_nested (void)- 1
- 2
注意事项及限制条件:
- 对于C/C++,如果启用嵌套并行性,则返回非零值,否则返回0。
OMP_SET_SCHEDULE
目标:
- 此例程设置用于循环指令运行时的时间调度策略。
格式:
#include <omp.h>
void omp_set_schedule(omp_sched_t kind, int modifier)- 1
- 2
OMP_GET_SCHEDULE
目标:
- 此例程返回在循环指令指定运行时调度时应用的调度策略。
格式:
#include <omp.h>
void omp_get_schedule(omp_sched_t * kind, int * modifier )- 1
- 2
OMP_SET_MAX_ACTIVE_LEVELS
目标:
- 此例程限制嵌套活动并行区域的数量。
格式:
#include <omp.h>
void omp_set_max_active_levels (int max_levels) - 1
- 2
注意事项及限制条件:
- 如果所请求的并行级别的数量超过实现所支持的并行级数,则该值将被设置为实现所支持的并行级别数。
- 该程序仅在从程序的顺序部分调用时才具有效果。当在显式并行区域内调用时,此例程的作用就是具体实现相关的。
OMP_GET_MAX_ACTIVE_LEVELS
目标:
- 此例程返回嵌套活动并行区域的最大数量。
格式:
#include <omp.h>
int omp_get_max_active_levels(void) - 1
- 2
OMP_GET_LEVEL
目标:
- 此例程返回包含该调用任务的嵌套并行区域的数量。
格式:
#include <omp.h>
int omp_get_level(void) - 1
- 2
注意事项及限制条件:
- omp_get_level例程返回包含调用任务的嵌套并行区域(无论是活动的还是非活动的)中除去隐式并行区域的数量。该例程总是返回非负整数。如果从程序的串行部分调用,则返回0。
OMP_GET_ANCESTOR_THREAD_NUM
目标:
- 给定当前线程的嵌套级别,该例程返回祖先或者当前线程的线程号。
格式:
#include <omp.h>
int omp_get_ancestor_thread_num(int level) - 1
- 2
注意事项和限制条件:
- 如果所请求的嵌套级别超出范围0和由omp_get_level子程序返回的当前线程的嵌套级别,则该例程反悔-1。
OMP_GET_TEAM_SIZE
目标:
- 给定当前线程的给定嵌套级别,此例程返回祖先或者当前线程所属组的大小。
格式:
#include <omp.h>
int omp_get_team_size(int level); - 1
- 2
注意事项和限制条件:
- 如果所请求的嵌套级别在0和由omp_get_level例程返回的当前线程的嵌套级别之外,则该例程返回-1。非活动并行区域被认为像单线程执行的活动并行区域一样。
OMP_GET_ACTIVE_LEVEL
目标:
- omp_get_active_level例程返回包含该调用任务的活动嵌套并行区域的数量。
格式:
#include <omp.h>
int omp_get_active_level(void);- 1
- 2
注意事项和限制条件:
- 该例程总是返回一个非负整数。如果从程序的串行部分调用,则返回0。
OMP_IN_FINAL
目标:
- 如果程序在最终任务区域中执行,则此例程反悔true;否则返回false。
格式:
#include <omp.h>
int omp_in_final(void) - 1
- 2
OMP_INIT_LOCK
OMP_INIT_NEST_LOCK
目标:
- 该子例程初始化与锁变量相关联的锁。
格式:
#include <omp.h>
void omp_init_lock(omp_lock_t *lock)
void omp_init_nest_lock(omp_nest_lock_t *lock)- 1
- 2
- 3
注意事项及限制条件:
- 初始状态是解锁状态。
OMP_DESTROY_LOCK
OMP_DESTROY_NEST_LOCK
目标:
- 该子程序将给定的锁变量与所有锁解除关联。
格式:
#include <omp.h>
void omp_destroy_lock(omp_lock_t *lock)
void omp_destroy_nest_lock(omp_nest_lock_t *lock)- 1
- 2
- 3
注意事项及限制条件:
- 使用未初始化的锁变量调用此例程是非法的。
OMP_SET_LOCK
OMP_SET_NEST_LOCK
目标:
- 该子程序强制执行线程等待,直到指定的锁可用。一个线程在可用时被授予锁的使用权。
格式:
#include <omp.h>
void omp_set_lock(omp_lock_t *lock)
void omp_set_nest__lock(omp_nest_lock_t *lock)- 1
- 2
- 3
注意事项和限制条件:
- 使用未初始化的锁变量调用此例程是非法的。
OMP_UNSET_LOCK
OMP_UNSET_NEST_LOCK
目标:
- 该子程序从执行子程序中释放锁。
格式:
#include <omp.h>
void omp_unset_lock(omp_lock_t *lock)
void omp_unset_nest__lock(omp_nest_lock_t *lock)- 1
- 2
- 3
注意事项和限制条件:
- 使用未初始化的锁变量调用此例程是非法的。
OMP_TEST_LOCK
OMP_TEST_NEST_LOCK
目标:
- 此子程序尝试设置锁,但如果锁定不成功,则不会阻塞。
格式:
#include <omp.h>
int omp_test_lock(omp_lock_t *lock)
int omp_test_nest__lock(omp_nest_lock_t *lock)- 1
- 2
- 3
注意事项和限制条件:
- 对于C/C++,如果锁设置成功,则返回非零值,否则返回0。
- 使用未初始化的锁变量调用此例程是非法的。
OMP_GET_WTIME
目标:
- 提供可移植的挂钟计时程序。
- 返回一个从过去某个时间点经过的秒数的双精度浮点值。通常以“pair”的形式使用,在第二次调用的值中减去第一次调用的值,就可以获得代码块的经过时间。
- 设计为“每个线程”一次。因此在一个组内的所有线程中可能不是全局一致的——取决于线程与其他线程相比的行为。
格式:
#include <omp.h>
double omp_get_wtime(void) - 1
- 2
OMP_GET_WTICK
目标:
- 提供可移植的挂钟计时程序。
- 返回一个表示连续时钟秒数的双精度浮点值。
格式:
#include <omp.h>
double omp_get_wtick(void)
O
ot
ot
O
U
a
au
au
a
at
ato
ato
atom
atom
atomi
atomi
atomic
atomic
ATOMIC
这篇关于并行编程OpenMP基础及简单示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







