numba专题
Numba 的 CUDA 示例(4/4):原子和互斥
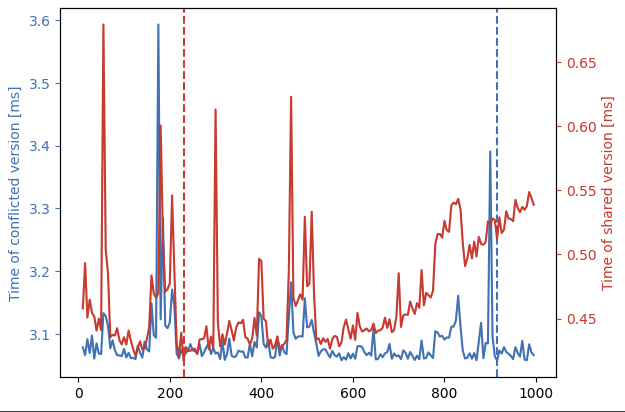
本教程为 Numba CUDA 示例 第 4 部分。 本系列第 4 部分总结了使用 Python 从头开始学习 CUDA 编程的旅程 介绍 在本系列的前三部分(第 1 部分,第 2 部分,第 3 部分)中,我们介绍了 CUDA 开发的大部分基础知识,例如启动内核来执行高度并行的任务、利用共享内存执行快速缩减、将可重用逻辑封装为设备功能,以及如何使用事件和流来组织和控制内核执行。 在
Numba 的 CUDA 示例 (2/4):穿针引线
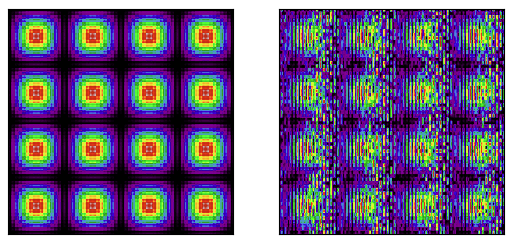
本教程为 Numba CUDA 示例 第 2 部分。 按照本系列从头开始使用 Python 学习 CUDA 编程 介绍 在本系列的第一部分中,我们讨论了如何使用 GPU 运行高度并行算法。高度并行任务是指任务完全相互独立的任务,例如对两个数组求和或应用任何元素函数。 在本教程中 许多任务虽然不是高度并行的,但仍可从并行化中获益。在本期的CUDA by Numba Examples

Numba 的 CUDA 示例(1/4):踏上并行之旅
按照本系列从头开始使用 Python 学习 CUDA 编程 介绍 GPU(图形处理单元),顾名思义,最初是为计算机图形学开发的。从那时起,它们几乎在每个需要高计算吞吐量的领域都无处不在。这一进步得益于 GPGPU(通用 GPU)接口的发展,这些接口使我们能够对 GPU 进行编程以进行通用计算。这些接口中最常见的是CUDA,其次是OpenCL,最近的是 HIP。 Python 中的

python3.5安装numba加速模块llvmlite版本不一致问题
报错: Building wheel for llvmlite (setup.py) ... error 解决方案: C:\Users\mazhe>pip install llvmlite==0.31.0 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com --proxy="http://proxy3.bj

numba用户手册-11 实例
numba用户手册 1.numba基础 2.@jit 3.使用自动并行化@jit 4.性能提升 5.创建ufunc 6.@jitclass 7.@cfunc 8.提前编译代码AOT 9.numba线程 10.调试 1.19。例子 1.19.1。曼德尔布罗 #! /usr/bin/env python# -*- coding: utf-8 -*-from __f
numba用户手册 10调试
numba用户手册 1.numba基础 2.@jit 3.使用自动并行化@jit 4.性能提升 5.创建ufunc 6.@jitclass 7.@cfunc 8.提前编译代码AOT 9.numba线程 10.调试 ------------------------------------------------------------------------------
numba,让python速度提升百倍!
python由于它动态解释性语言的特性,跑起代码来相比java、c++要慢很多,尤其在做科学计算的时候,十亿百亿级别的运算,让python的这种劣势更加凸显。 办法永远比困难多,numba就是解决python慢的一大利器,可以让python的运行速度提升上百倍! 什么是numba? numba是一款可以将python函数编译为机器代码的JIT编译器,经过numba编译的python代

ubuntu 安装numba
numba可以基于llvm动态生成优化代码,提高python的执行效率,只需要给python代码加上修饰器就好了。 由于numba依赖llvm,需要在ubuntu上事先安装好llvm。 sudo apt-get install llvm 在ubuntu上安装numba,需要执行命令: sudo -H pip install numba 若用清华的源下载, sudo -H pip

Python如何加速for循环?除了Numba @jit之外还有什么方法?
今天聊聊Python 3.0的Numba库的即时编译@jit(Just in Time)。 故事背景:知乎某小透明提出的一个问题 Python的多重for循环可以用什么办法克服其速度慢的缺陷(numba@jit除外)? 最近在回看自己之前打的代码,发觉一份项目里的Python代码里面,有一个三重循环十分耗时间,使用numba的话提升效果并不明显,想问问大家如何去解决。大家一起来讨论下吧~
Ubuntu 18.04 LTS安装numba python性能优化的比较:numba,pypy, cython
安装很简单, 我就不多废话了, 直接上指令: sudo apt-get install llvmsudo -H pip install numba python 程序性能优化的套路一般有两种:1)jit, 即just in time compiler, 即时编译器,在运行时将某些函数编译成二进程代码,使用这种方式的有:numba 和pypy;2)将python代码转换成c+
强化学习技巧五:numba提速python程序
numba是一款可以将python函数编译为机器代码的JIT编译器,经过numba编译的python代码(仅限数组运算),其运行速度可以接近C或FORTRAN语言。 numba使用情况 使用numpy数组做大量科学计算时使用for循环时 1.numba使用 导入numpy、numba及其编译器 import numpy as npimport numbafrom numba imp
【已解决】No module named numba.decorators
问题描述 ModuleNotFoundError: No module named 'numba.decorators' 解决办法 这个就是版本的问题,和之前提到的是一样的,就是版本更新之后有些函数弃用了,所以只需要使用比较旧的版本就可以了,比如 pip install numba==0.48 当然在这里面还有一个解决办法是把tensorflow降低

Python优化利器:Numba库深度探究
更多资料获取 📚 个人网站:ipengtao.com Numba 是一个用于优化 Python 代码的开源即时编译器,能够将 Python 代码转换为本机机器码,提高其执行速度。其主要特点包括: 能够加速整数、浮点数等数值计算。支持直接在 CPU 和 GPU 上执行代码。使用简单的修饰器和函数调用,可用于加速循环、数学计算等任务。 安装 Numba 安装 Numba 非常简单,
使用numba cuda 加速Python运算
使用numba cuda 加速Python运算 1.随机数生成参考文献 习惯了cuda c,可能会认为cuda和c才是黄金档搭。 Python作为一种开发效率比较高的脚本语言,有助于我们快速实现某种功能。 但是Python执行效率极其之慢。 这种情况下,用cuda的高并发特性,来提升Python执行速度,是一种很好的选择。 1.随机数生成 随机数生成是一项很重要的功能。

numba ImportError: Numba needs NumPy 1.21 or less
问题描述 升级numba就遇到了这个问题。然后尝试卸载numba后重装也不行。据朋友说问题出在llvmlite上。numba依赖于llvmlite,但是在(用conda、pip)升级numba的过程中旧版本的llvmlite不会被删掉,导致新版本的llvmlite没装上就会出现这个问题。 解决 先用pip删除llvmlite(别用conda删,很啰嗦),再用pip升级numba,就解决了!
问题解决:ImportError:Numba needs NumPy 1.22 or less
跑一个以前的代码,总是报错:ImportError:Numba needs NumPy 1.22 or less 查了下,网上都说是numpy的版本不能匹配上Numba,需要安装低版本的numpy,用pip list查看确实是版本没能够达到要求,即1.22版本以下: 网上给的意见大多数是,重新安装低版本的numpy,于是进行了尝试,但是一直报错呢: ERROR: Could not fin
【实用小功能10】python运行加速神器——numba(详细教学版)
目录 1. 为什么python这么慢?1.1 动态变量1.2. 解释性语言 2. Numba的介绍和使用2.1 numba加速python小实例2.2 个人经验2.3 其他 1. 为什么python这么慢? python比c++慢,尤其是存在循环的情况下,python和c+的区别主要有: 1.1 动态变量 c++中需要对变量类型有严格的定义,比如int或者float类型
使用numba加速python科学计算
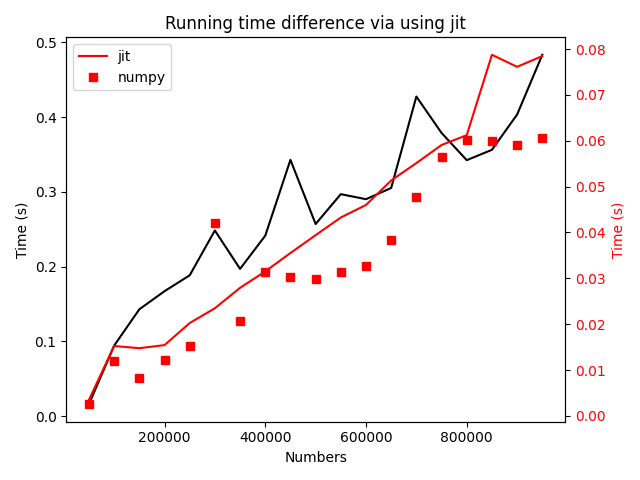
技术背景 python作为一门编程语言,有非常大的生态优势,但是其执行效率一直被人诟病。纯粹的python代码跑起来速度会非常的缓慢,因此很多对性能要求比较高的python库,需要用C++或者Fortran来构造底层算法模块,再用python进行上层封装的方案。在前面写过的这篇博客中,介绍了使用f2py将fortran代码编译成动态链接库的方案,这可以认为是一种“事前编译”的手段。但是本文将要介