learners专题

速通GPT-3:Language Models are Few-Shot Learners全文解读
文章目录 论文实验总览1. 任务设置与测试策略2. 任务类别3. 关键实验结果4. 数据污染与实验局限性5. 总结与贡献 Abstract1. 概括2. 具体分析3. 摘要全文翻译4. 为什么不需要梯度更新或微调⭐ Introduction1. 概括2. 具体分析3. 进一步分析 Approach1. 概括2. 具体分析3. 进一步分析 Results1. 概括2. 具体分析2.1 语言模型
![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)
[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners
1、目的 借助无监督预训练来提升半监督学习的效果 2、方法 1)unsupervised/self-supervised pretrain -> task-agnostic -> big (deep and wide) neural network可以有效提升准确性

Language Models are Unsupervised Multitask Learners
摘要 自然语言处理任务,如问答、机器翻译、阅读理解和摘要,通常在任务特定的数据集上使用监督学习来处理。当在一个名为WebText的数百万网页的新数据集上训练时,我们证明了语言模型在没有任何明确监督的情况下开始学习这些任务。在不使用127,000多个训练示例的情况下,当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55的F1值 -匹配或超过4个基线系统中的3个的性能。语言模型的能力

Radiance Field Learners As UAVFirst-Person Viewers 翻译
作为无人机第一人称视角的辐射场学习者 引言。第一人称视角(FPV)在无人机飞行轨迹的革新方面具有巨大的潜力,为复杂建筑结构的导航提供了一条令人振奋的途径。然而,传统的神经辐射场(NeRF)方法面临着诸如每次迭代采样单个点以及需要大量视图进行监控等挑战。UAV视频由于视点有限和空间尺度变化大而加剧了这些问题,导致不同尺度下的细节渲染不足。作为回应,我们引入了FPV-NeRF,通过三个关键方面来解决

【深度学习】GPT-3,Language Models are Few-Shot Learners(一)
论文: https://arxiv.org/abs/2005.14165 摘要 最近的研究表明,通过在大规模文本语料库上进行预训练,然后在特定任务上进行微调,可以在许多NLP任务和基准上取得显著的进展。虽然这种方法在结构上通常是任务无关的,但仍然需要数千或数万个示例的任务特定微调数据集。相比之下,人类通常可以通过少量示例或简单指令来执行新的语言任务,而当前的NLP系统在这方面仍然存在很大困难。

人工智能论文GPT-3(2):2020.5 Language Models are Few-Shot Learners;微调;少样本Few-Shot (FS)
2 方法Approach 我们的基本预训练方法,包括模型、数据和训练,与GPT-2中描述的过程相似,只是模型规模、数据集规模和多样性,以及训练时长有所扩大,相对简单直接。 我们使用的上下文学习也与GPT-2相似,但在这项工作中,我们系统地探索了不同上下文学习设置。 因此,我们首先明确定义并对比我们将评估GPT-3的不同设置,或者原则上可以评估GPT-3的设置。 这些设置可以被看作是一个谱系
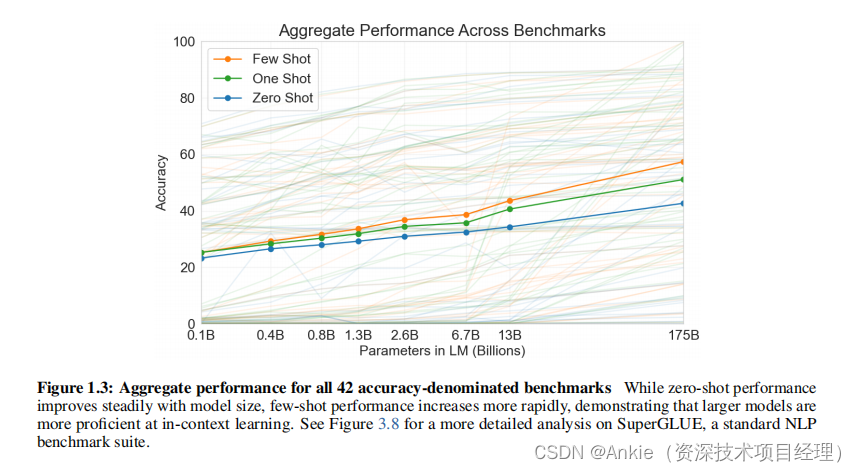
人工智能论文GPT-3(1):2020.5 Language Models are Few-Shot Learners;摘要;引言;scaling-law
摘要 近期的工作表明,在大量文本语料库上进行预训练,然后针对特定任务进行微调,可以在许多NLP任务和基准测试中取得实质性进展。虽然这种方法在架构上通常是与任务无关的,但仍然需要包含数千或数万示例的针对特定任务的微调数据集。相比之下,人类通常只需要几个示例或简单的说明就能执行新的语言任务——这是当前NLP系统仍难以做到的。在这里,我们展示了扩大语言模型规模可以极大地提高与任务无关、少量样本的性能,
![[论文精读]Masked Autoencoders are scalable Vision Learners](https://img-blog.csdnimg.cn/direct/339a52553e2447ffa8b06a7d8d7d0fef.png)
[论文精读]Masked Autoencoders are scalable Vision Learners
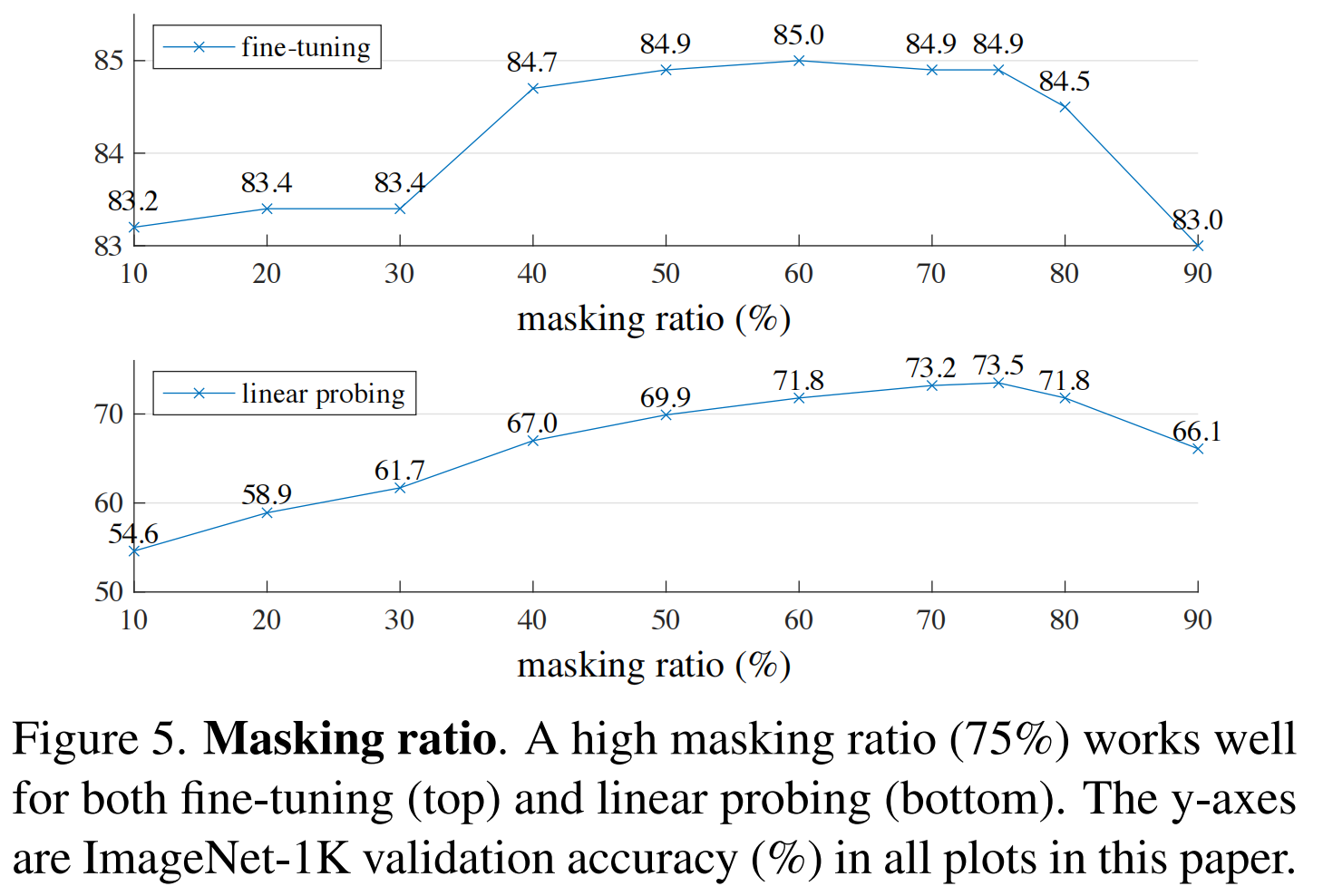
摘要本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的 MAE方法很简单:我们盖住输入图像的随机块并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对块的可见子集(没有掩码标记)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码标记重建原始图像。其次,我们发现如果用比较高的掩盖比例掩盖输入图像,例如75%,这会产生

Re65:读论文 GPT-3 Language Models are Few-Shot Learners
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文全名:Language Models are Few-Shot Learners ArXiv网址:https://arxiv.org/abs/2005.14165 2020 NeurIPS:https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142
![[阅读笔记1][GPT-3]Language Models are Few-Shot Learners](https://img-blog.csdnimg.cn/direct/fc2a2977c968468aab18f3dc61e8847c.png)
[阅读笔记1][GPT-3]Language Models are Few-Shot Learners
首先讲一下GPT3这篇论文,文章标题是语言模型是小样本学习者,openai于2020年发表的。 这篇是在GPT2的基础上写的,由于GPT2还存在一些局限,这篇对之前的GPT2进行了一些完善。GPT2提出了多任务学习,也就是可以零样本地用在各个下游任务,不需要再进行微调了,这与Bert的思路差别很大。但是GPT2的结果没有特别出色,只是比部分有监督的模型高了一点,大概处在一个平均水平。 G

Finetuned Language Models Are Zero-Shot Learners
Abstract 本文探索了一种简单的方法来提升语言模型的零样本(zero-shot)学习能力。我们发现 指令微调(instruction tuning) 显著提高了未见任务的零样本性能。 指令微调:即在一组通过指令描述的数据集上对模型进行微调 我们对一个 137B 参数的预训练模型在 60 个 NLP 任务上进行指令微调。这些任务通过自然语言指令模板进行表述。我们将指令微调后的模型称为

【论文精读】MAE:Masked Autoencoders Are Scalable Vision Learners 带掩码的自动编码器是可扩展的视觉学习器
系列文章目录 【论文精读】Transformer:Attention Is All You Need 【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 【论文精读】VIT:vision transformer论文 文章目录 系列文章目录一、前言二、文章概览(一)研究背

MAE——「Masked Autoencoders Are Scalable Vision Learners」
这次,何凯明证明让BERT式预训练在CV上也能训的很好。 论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。 这项工作的意义何在? 讨论区 Reference MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili //

Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文全名:Language Models are Unsupervised Multitask Learners 论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pd

文献阅读:Large Language Models are Null-Shot Learners
文献阅读:Large Language Models are Null-Shot Learners 1. 文章简介2. 方法介绍3. 实验考察 & 结论 1. 基础实验 1. 实验设计2. 实验结果 2. 消融实验 1. 小模型上的有效性2. ∅CoT Prompting3. 位置影响4. 组成内容 4. 总结 & 思考 文献链接:https://arxiv.org/abs/2401.0827
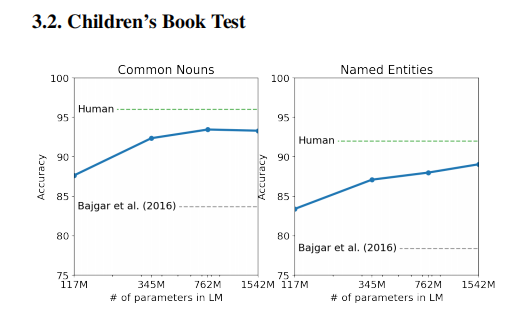
【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners
文章目录 介绍zero-shot learning 零样本学习 方法数据Input Representation 结果 论文:Language Models are Unsupervised Multitask Learners 作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, I. Sutskever

NLP之GPT-3:《 Language Models are Few-Shot Learners》的翻译与解读
NLP之GPT-3:《 Language Models are Few-Shot Learners》的翻译与解读 目录 相关文章 NLP之GPT-3:NLP领域没有最强,只有更强的模型—GPT-3的简介(本质、核心思想、意义、特点、优缺点、数据集、实际价值,模型强弱体现,开源探讨)、安装、使用方法之详细攻略 NLP之GPT-3:《 Language Models are Few-S
A learning tutorial of Python for intro level learners
This is a learning tutorial of Python for intro level learners. 转载自https://qingdoulearning.gitbook.io/project/ 0.前期准备 1.Variables and Types - - String and Number变量和数据类型——字符串和数字 2.Operators操作符 3.List列表
【ICCV 2022】(MAE)Masked Autoencoders Are Scalable Vision Learners
何凯明一作文章:https://arxiv.org/abs/2111.06377 感觉本文是一种新型的自监督学习方式 ,从而增强表征能力 本文的出发点:是BERT的掩码自编码机制:移除一部分数据并对移除的内容进行学习。mask自编码源于CV但盛于NLP,恺明对此提出了疑问:是什么导致了掩码自编码在视觉与语言之间的差异?尝试从不同角度进行解释并由此引申出了本文的MAE。 恺明提出一种用于计
论文阅读: Masked Autoencoders Are Scalable Vision Learners掩膜自编码器是可扩展的视觉学习器
Masked Autoencoders Are Scalable Vision Learners 掩膜自编码器是可扩展的视觉学习器 作者:FaceBook大神何恺明 一作 摘要: This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision.
Pre-trained Language Models Can be Fully Zero-Shot Learners
本文是LLM系列文章,针对《Pre-trained Language Models Can be Fully Zero-Shot Learners》的翻译。 预训练语言模型可以是完全零样本的学习者 摘要1 引言2 相关工作3 背景:PLMs基于提示的调整4 提出的方法:NPPrompt5 实验6 讨论7 结论局限性 摘要 在没有标记或额外的未标记数据的情况下,我们如何将预先训练的
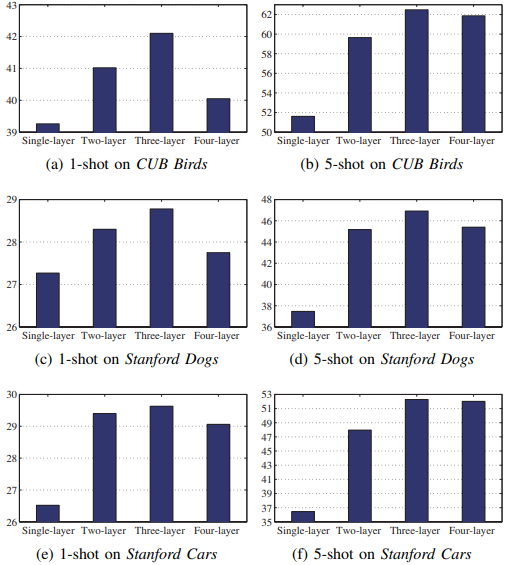
论文笔记:Piecewise classifier mappings: Learning FG learners for novel categories with few examples
Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples 文章目录 Piecewise classifier mappings: Learning fine-grained learners for novel categories with fe

Staple: Complementary Learners for Real-Time Tracking——笔记
Stalpe = DSST + 颜色直方图 初始化 求出patch的前景颜色直方图和背景颜色直方图 建立高斯标签 尺度滤波器 第一帧 求位移滤波器 求尺度滤波器 第二帧 根据上一帧的位移滤波求位移响应(空间特征),根据颜色直方图求位移响应(全局特征),取一定系数相加,得到这一帧的位置 根据位置和尺度滤波器求尺度大小 更新位移滤波器和尺度滤波器 循环 Stapl

Staple: Complementary Learners For Real-time Tracking Tracking
转载注明出处: http://www.cnblogs.com/sysuzyq/p/6169414.html By 少侠阿朱 讨论班上的PPT 1.同学大家好。今天给大家讲一篇单目标跟踪的论文,方法比较传统,但是我觉得比较实用。不过,公式非常多,有一定难度。不过,大家别害怕,因为我看了作者代码,可以说说怎么做的,大家别太关注公式。 但是我们先大体浏览一遍公式,再讲一下代码实现。有兴趣可以课后