本文主要是介绍【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 介绍
- zero-shot learning 零样本学习
- 方法
- 数据
- Input Representation
- 结果
论文:Language Models are Unsupervised Multitask Learners
作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, I. Sutskever
时间:2019
介绍
GPT-2 是一个有15亿参数的模型,GPT-2的想法是转向一个通用的系统,不需要进行数据集的标注就可以执行许多的任务;
因为数据集的创建是很难的,我们很难继续将数据集的创建和目标的设计扩大到可能需要用现有的技术推动我们前进的程度。这促使我们去探索执行多任务学习的额外设置。
当前性能最好的语言模型系统是通过预训练模型和微调完成的,预训练主要是自注意力模块去识别字符串的语意,而微调主要是通过语意去得出不同的结果;这样一来,我们在执行不同的任务时,只需要替换掉微调的那部分结构就可以;
而GPT-2证实了语言模型能够在不进行任何参数和结构修改的情况下,拥有执行下游任务的能力,这种能力获取的主要方式是强化语言模型的 zero-shot
zero-shot learning 零样本学习

零样本学习也叫ZSL,通俗来讲就是说在训练集中并没有出现的y能够在测试集中识别出来;当然,如果不做任何处理我们是无法识别的,我们需要没有出现的y的信息来帮助我们识别y;通过上面的图我们可以知道,horse和donkey可以得出horselike,tiger和hyena可以得出stripe,penguin和panda 可以得出 black and white,这里我们可以通过zebra的描述信息可以得出horselike,stripe,black and white 的动物是斑马来训练模型,这样我们可以在测试集的时候识别出斑马;
这里有两篇比较详细的介绍:
零次学习(Zero-Shot Learning)入门 (zhihu.com)
零次学习(Zero-Shot Learning) - 知乎 (zhihu.com)
方法
首先介绍一下语言模型:
p ( x ) = p ( s 1 , s 2 , … , s n ) = ∏ i = 1 n p ( s n ∣ s 1 , … , s n − 1 ) p(x)=p(s_1,s_2,\dots,s_n)=\prod_{i=1}^{n}p(s_n|s_1,\dots,s_{n-1}) p(x)=p(s1,s2,…,sn)=i=1∏np(sn∣s1,…,sn−1)
其中 x x x是句子, s 1 , s 2 , … , s n s_1,s_2,\dots,s_n s1,s2,…,sn 组成句子可能出现的词;
在经过预训练之后,我们在执行特定的任务时,我们需要对特定的输入有特定的输出,这时模型就变成了 p ( o u t p u t ∣ i n p u t ) p(output|input) p(output∣input) ;为了让模型更一般化,能执行不同的任务,我们需要对模型继续进行处理,变成了 p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input, task) p(output∣input,task) ;
这样一来,我们需要对数据框架的形式进行一定的修改,如翻译任务我们可以写为
translate to french, english text , french text
阅读理解任务可以写为
answer the question, document, question, answer
语言模型在原则上来说是可以利用上面的框架进行无监督学习训练的;在训练过程中,由于最终的评价方式是一致的,所以监督学习和无监督学习的目标函数是一样的;唯一不同的是监督学习是在子集上进行评估损失,而无监督学习是在全局上评估损失,综合来说对全局不产生影响,因此无监督学习损失的全局最小值和有监督学习损失的全局最小值是一致的;
论文进行初步实验证实,足够多参数的模型能够在这种无监督训练方式中学习,但是学习要比有监督学习收敛要慢得多;
作者认为,对于有足够能力的语言模型来说,模型能够以某种方式识别出语言序列中的任务并且能够很好的执行它,如果语言模型能够做到这一点,那么就是在高效的执行无监督多任务学习;
数据
由于是多任务模型,需要构建尽可能大的和多样化的数据集,这里作者采用的是网络爬虫的方式进行解决;为了避免文档质量不高,这里只采集了经过人类策划/过滤后的网页,手动过滤是困难的,所以作者只采集了Reddit社交平台上信息;最后生成的数据集包含了4500万个链接的文本子集;文本是通过Dragnet 和 newspaper进行提取的,经过重复数据删除和一些启发式的清理,该链接包含近800万文档,共计40GB文本,并且删除了所有的维基百科文档,因为它是其他数据集的通用数据源,并且可能会由于过度-而使分析复杂化;
Input Representation
这里采用的是BPE编码方式,具体在[BPE]论文实现:Neural Machine Translation of Rare Words with Subword Units-CSDN博客可以详细了解;
结果
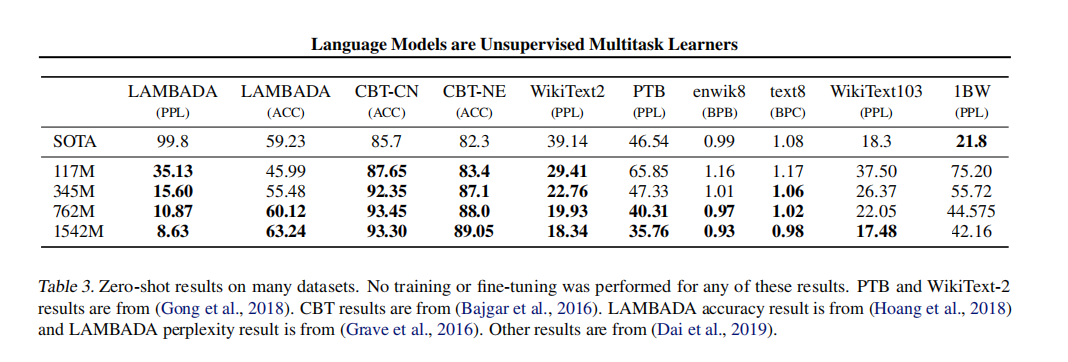
这里有ACC,PPL,BPC,BPB 四个指标:
详细可以看这篇文章:困惑度(perplexity)的基本概念及多种模型下的计算(N-gram, 主题模型, 神经网络) - 知乎 (zhihu.com)
ACC 指的是准确度: A C C = T P + T N T P + T N + F P + F N ACC=\frac{TP+TN}{TP+TN+FP+FN} ACC=TP+TN+FP+FNTP+TN
介绍后面的指标之前需要先介绍一下Cross entropy也就是交叉熵: H ( P , Q , s ) = − ∑ i = 1 n P ( x i ) l n Q ( x i ) H(P,Q,s)=-\sum_{i=1}^n P(x_i)lnQ(x_i) H(P,Q,s)=−i=1∑nP(xi)lnQ(xi)
这里P指的是真实概率,Q指的是预测概率, x i x_i xi指的是每一个unit,而s由n个unit的 x i x_i xi组成,这里表示s这一句话的交叉熵;
PPL 指的是困惑度,也就是一句话出现的概率,句子出现的概率越大,困惑度越小: P P L = P ( x 1 , x 2 , … , x n ) − 1 N PPL=P(x_1,x_2,\dots,x_n)^{-\frac{1}{N}} PPL=P(x1,x2,…,xn)−N1
BPC,BPW和BPB 分别指的是bits-per-character, bits-per-word,bits-per-byte: B P C / B P W / B P B = 1 T ∑ t = 1 T H ( P , Q , s t ) BPC/BPW/BPB=\frac{1}{T}\sum_{t=1}^{T}H(P,Q,s_t) BPC/BPW/BPB=T1t=1∑TH(P,Q,st)
其不同就是在计算H的时候计算的分别是character,word,byte;主要在于分词;
由于PPL中P的特殊性,只有一个1,其余都是0,有公式如下:
B P C = − 1 T ∑ t = 1 T ∑ i = 1 n P ( c t i ) l n Q ( c t i ) = − 1 T ∑ t = 1 T l n Q ( s t ) = − 1 T l n P ( d o c u m e n t ) = l n P P L \begin{align} BPC & = -\frac{1}{T}\sum_{t=1}^T\sum_{i=1}^{n}P(c_{ti})lnQ(c_{ti}) \\ & = -\frac{1}{T}\sum_{t=1}^TlnQ(s_t) \\ & = -\frac{1}{T}lnP(document) \\ & = lnPPL \end{align} BPC=−T1t=1∑Ti=1∑nP(cti)lnQ(cti)=−T1t=1∑TlnQ(st)=−T1lnP(document)=lnPPL
即有: P P L = e B P C PPL=e^{BPC} PPL=eBPC
从上图中可以看出GPT-2都表现出了不错的性能;
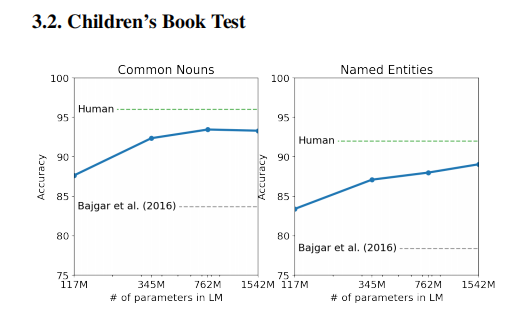
同时在儿童读物测试中 随着参数量的增加,性能都出现了一定的增强;
还有一些结果证实了无标注训练模型的能力,这里就不展示了,这篇文章证明了当一个大型语言模型在一个足够大和多样化的数据集上进行训练时,它能够在许多领域和数据集上表现良好。
这篇关于【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






