hyperloglog专题

Redis中HyperLogLog的使用小结
《Redis中HyperLogLog的使用小结》Redis的HyperLogLog是一种概率性数据结构,用于统计唯一元素的数量(基数),本文主要介绍了Redis中HyperLogLog的使用小结,感兴... 目录 一、HyperlogLog 是什么?️ 二、使用方法1. 添加数据2. 查询基数China编程3.

黑马点评11——UV统计-HyperLogLog
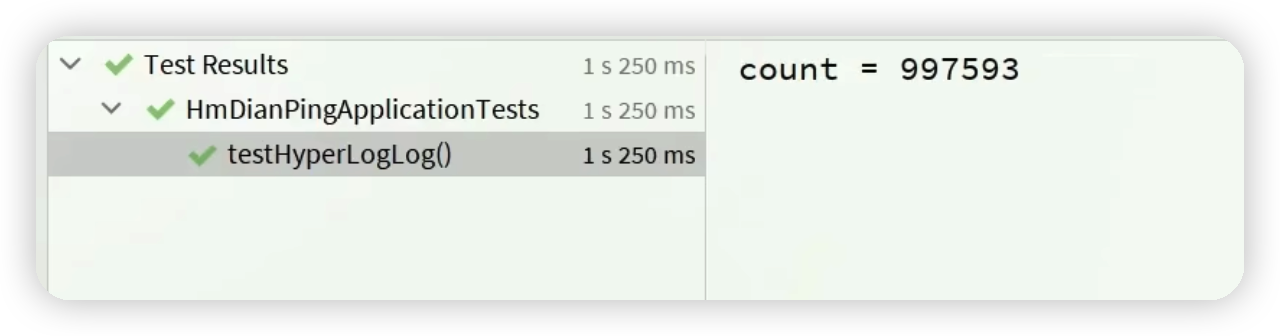
文章目录 HyperLogLog的用法测试百万数据的统计 HyperLogLog的用法 简直就是天生用于UV统计的,太爽了! 测试百万数据的统计 /*** info memory* 2107168* 插入1000000条数据后,内存的变化* 2121552*/@Testvoid testHyperLogLog(){String[] values = new Stri

基于 Redis 的 HyperLogLog 实现了 UV 的统计
文章目录 前言HyperLogLog 简介HyperLogLog 的工作原理例子总结 前言 在现代网站开发中,用户行为分析是一个非常重要的环节。其中,UV(Unique Visitor,独立访客)和PV(Page View,页面浏览量)是衡量网站流量和用户活跃度的关键指标。UV 指的是通过互联网访问网站的自然人数量,通常一个用户在一定时间内的多次访问只计作一次;而 PV 则指的

HyperLogLog的使用做UV统计
使用Jedis连接Redis并操作HyperLogLog import redis.clients.jedis.Jedis;public class RedisHyperLogLogExample {public static void main(String[] args) {// 连接到本地的Redis服务Jedis jedis = new Jedis("localhost", 6
使用Redis HyperLogLog统计UV浏览用户数
在开发中,经常遇到要统计某个页面的访问用户数UV。我们很容易想到使用Redis Set来统计,当用户数不多的时候确实可以,本人开发的项目中要统计一个月面一个月用户的访问数量,月活跃用户数量在千万级别以上,如果用Set即使使用Hash打散存储key也需要700-800MB的redis内存,这明显很浪费.这种场景中使用HyperLogLog进行去重统计是非常合适的. HyperLogLog算法是一种
Redis进阶——BitMap用户签到HyperLogLog实现UV统计
目录 用户签到实现签到功能 签到统计HyperLogLog实现UV统计UV和PV的概述测试百万数据的统计 用户签到 BitMap功能演示 我们针对签到功能完全可以通过MySQL来完成,例如下面这张表 用户签到一次,就是一条记录,假如有1000W用户,平均每人每年签到10次,那这张表一年的数据量就有1亿条 那有没有方法能简化一点呢?我们可以使用二进制位来记录每个月的签到情况

redis特殊数据类型-Hyperloglog(基数统计)用法
一,Hyperloglog介绍 Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLo
redis---HyperLogLog
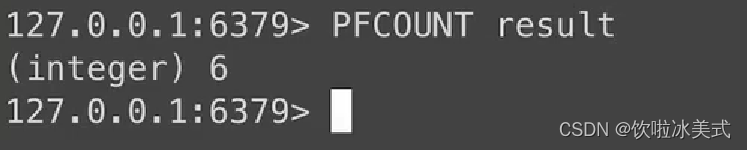
HyperLogLog是一个基数统计的算法,如果集合中的每个元素都是唯一且不重复的,那么这个集合的基数就是集合中元素的个数 它的原理是使用随机算法来计算,通过牺牲一定的精确度,来换取更小的内存消耗,优点就是占用内存小。那相应的缺点也就是会有一定的误差,所以它适合用来做一些对精确度要求不高,而且数据量非常大的统计工作。比如统计某个网络的UV,统计某个词的搜索次数等。 用PFMERGE
BitMap 和 HyperLogLog
目录 BitMap 常用命令 应用场景 日活统计 用户签到 HyperLogLog 什么是基数? 常用命令 应用场景 BitMap 问: "有10亿个不重复的无序的正数,如果快速排序?" 这看上去很简单,就是一个排序而已,但是大部分排序算法都需要把数据放到内存里面操作,这10亿个数字得占用多少内存? 在大部分编程语言里面,int类型一般的都是占4个byte,

hyperloglog实战 - 你的过滤器选对了吗?
一、业务背景 最近接到一个统计需求,为了监控视频效果,我们每次浏览视频都要记录uv。当量小的时候,没有问题,随着用户量的的增长,占用空间大的问题开始暴露。假如有1000万用户,采用set结构记录UV,我们只存储int类型的用户id,1000万*4byte/1024kb/1024mb=38.14G,这是一个视频一天的数据,很明显存储成本太高,必须找到一种既能满足需求,又很少占用空间的方案。 二、
Redis的HyperLogLog原理介绍
Redis 的 HyperLogLog 数据结构实现了一种基于概率的基数估算算法,用于在占用极小内存的情况下估算一个集合中不重复元素(唯一值)的数量。以下是 HyperLogLog 算法的基本原理: 哈希函数: HyperLogLog 使用一个强散列函数将输入的元素映射为固定长度的二进制串。 位前导零统计: 对每个元素经过哈希后的二进制串,统计从最高位开始连续零的个数(即前导零个数)。这个值
Redis(十五)Bitmap、Hyperloglog、GEO案例、布隆过滤器
文章目录 面试题常见统计类型聚合统计排序统计二值统计基数统计 Hyperloglog专有名词UV(Unique Visitor)独立访客PV(Page View)页面浏览量DAU(Daily Active User)日活跃用户量MAU(Monthly Active User) 需求原理亿级UV的Redis统计方案 GEO面试题命令GEOADD获取某位置的经纬度GEOPOS返回坐标的Geoha

Redis 数据类型及其常用命令二(bitmap、geo、hyperloglog、bitfield、stream)
上文中我们介绍了Redis常使用的5中数据类型,对于一些特殊的场景,我们需要使用特殊的数据类型,本文将详细介绍5种特殊的数据类型。 1、bitmap 类型 用String类型作为底层数据结构实现的一种统计二值状态的数据类型。位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量( 我们称之为一个索引)。B

Redis中的BitMap、HyperLogLog、一致性Hash算法
目录 BitMap数据结构 HyperLogLog数据结构 Redis中的HyperLogLog HyperLogLog的核心思想 Redis集群一致性Hash算法 使用Hash取模的问题 一致性Hash算法 一致性Hash算法的容错性和可扩展性 Hash环的数据倾斜问题 BitMap数据结构 操作的最小单元是比特位(bit) 位图,由比特位(bit)组成的数
使用HyperLogLog统计网站uv
网站的UV定义 网站的UV(Unique Visitor)是指独立访客的数量,用于衡量网站的访问量和流量。在网站统计中,通常使用UV来度量网站的独立访客数量。 UV的定义有两种常见方式: Cookie方式:通过浏览器的Cookie来标识和追踪访客。当一个访问者首次访问网站时,服务器会在其浏览器中生成一个唯一的标识符(通常是一个Cookie),用于标识该访客。随后,如果同一访客再次访问网站,服

redis数据结构详解(基本数据结构,位图,HyperLogLog,GeoHash,布隆过滤器)
redis数据结构详解 文章目录 redis数据结构详解1. 五种基本数据结构1.1 String1.2 list1.3 hash1.4 set1.5 zset 2. 高级特性2.1 位图2.2 HyperLogLog2.3 Geo Hash2.4 布隆过滤器 参考书籍: 老钱的redis深度历险 1. 五种基本数据结构 1.1 String String是Redis最简

2024.1.2 Redis 数据类型 Stream、Geospatial、HyperLogLog、Bitmaps、Bitfields 简介
目录 引言 Stream 类型 Geospatial 类型 HyperLogLog 类型 Bitmaps 类型 Bitfields 类型 引言 Redis 最关键(应用广泛、频繁使用)的五个数据类型 StringListHashSetZSet 下文介绍的数据类型一般适合在特定的场景中使用! Stream 类型 Stream 类型可理解为一个阻塞队列,可用记录和模拟

探秘HyperLogLog:Redis中的基数统计黑科技
欢迎来到我的博客,代码的世界里,每一行都是一个故事 探秘HyperLogLog:Redis中的基数统计黑科技 前言HyperLogLog简介基数和基数统计的重要性HyperLogLog的历史和革命性 HyperLogLog的工作原理哈希函数线性计数与对数计数HyperLogLog的核心算法概率和统计原理 在redis中的实现创建和添加元素:PFADD计算基数:PF
108. Python语言 的 项目前导(上) 之 Redis 第九章 :Redis 的 基数统计算法 —— HyperLogLog
Redis 的 基数统计算法 —— HyperLogLog 本章主题关键词为什么要使用 HyperLogLog?HyperLogLog 介绍基础使用添加元素总结小便条 本章主题 关键词 为什么要使用 HyperLogLog? 在我们实际开发的过程中,可能会遇到这样一个问题,当我们需要统计一个大型网站的独立访问次数时,该用什么的类型来统计? 如
Redis中HyperLogLog的使用
目录 前言 HyperLogLog 前言 在学习HyperLogLog之前,我们需要先学习两个概念 UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量

【Redis核心原理和应用实践】应用 4:四两拨千斤 —— HyperLogLog
在开始这一节之前,我们先思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现? 如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。 但是 UV 不一样,它
![⑧【HyperLoglog】Redis数据类型:HyperLoglog [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)
⑧【HyperLoglog】Redis数据类型:HyperLoglog [使用手册]
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Redis HyperLoglog ⑧Redis HyperLoglog基本操作命令1. pfadd 添加指定基数到HyperLoglog中2. pfcount 给定HyperLoglog基数估算值(获
Redis HBase Es HyperLogLog与BloomFilter笔记
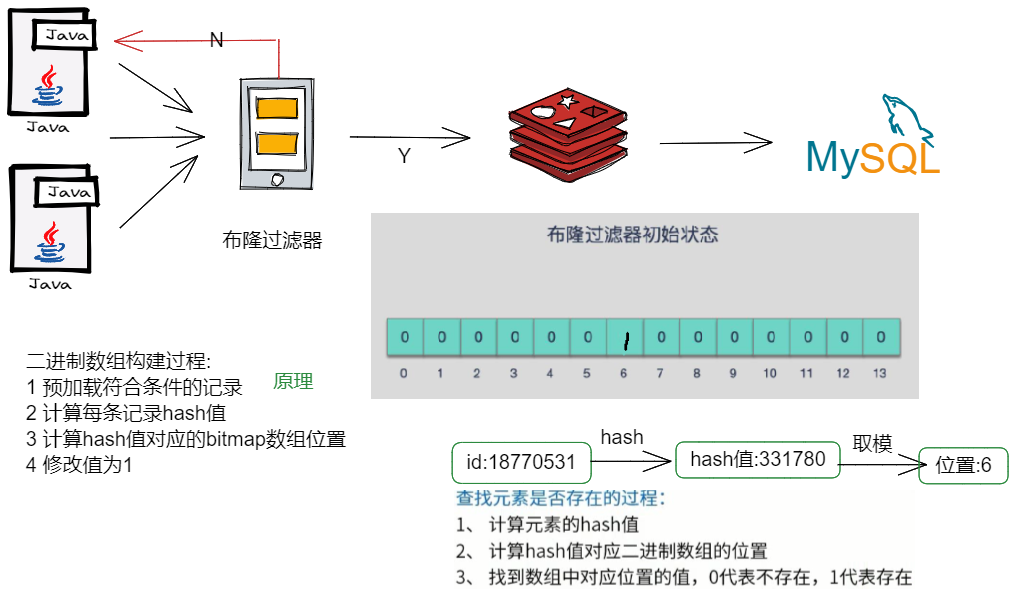
什么是布隆过滤器? 它实际上是一个很长的二进制向量和一系列随机映射函数。把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到二进制向量的位中,依次来间接标记一个元素是否存在于一个集合中。布隆过滤器可以做什么? 布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器特点 如果布隆过滤器显示一个
【Redis核心原理和应用实践】应用 4:四两拨千斤 —— HyperLogLog
在开始这一节之前,我们先思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现? 如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。 但是 UV 不一样,它
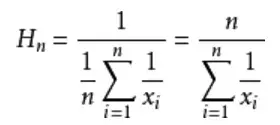
基于Redis的Hyperloglog实现日活量和总活跃量统计
一、背景介绍 产品提出想要统计目前系统中某个页面日活量与总活跃用户数量,由于这个页面登录与未登录用户均可访问,因此不能通过用户id来统计,要通过ip地址来做统计和去重处理。 二、技术选型 首先想到的方案是使用redis的set数据结构,因为它是一个无序集合,我们得到ip地址,然后存入set中即可实现统计与去重的效果,但是set有一个很大的问题是,每一条数据占用的空间会比较大,如果数据量很大的

【Redis】4、详解三种特殊数据类型 Geospatial、Hyperloglog、Bitmap
这三种特殊数据类型其实不是一个新的类型;底层还是五大类型中的一种;如:Zset、String 1、Geospatial 地理位置 geo:地理位置 spatial: [ˈspeɪʃl] 空间的 朋友的定位,附近的人,打车距离计算? Redis 的 Geo 在Redis3.2 版本就推出了! 这个功能可以推算地理位置的信息,两地之间的距离,方圆 几里的人! 可以查询一些测试数据: