本文主要是介绍Redis中HyperLogLog的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
HyperLogLog
前言
在学习HyperLogLog之前,我们需要先学习两个概念
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
如果UV在服务端做会很麻烦,因为每次都需要判断该用户是否已经统计过了,因此需要保存统计过的用户信息,如果都保存在Redis中,大型网站的数据量会非常大这种实现方案并不现实。因此,我们需要使用HyperLogLog算法。
HyperLogLog
该算法又可以叫做HLL算法,是从LogLog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值,Redis中的HLL是基于String结构实现的,单个HLL的内存占用永远不会超过16k,相应的代价是测量结果是概率性的,存在一定误差,但是可以忽略不计。
对应的命令如下
# 添加用户ip
PFADD key element [element ...]
# 统计访问量,在存在多个key的情况下,会对多个key的访问用户进行去重后再统计
PFCOUNT key [key ...]
# 合并统计量
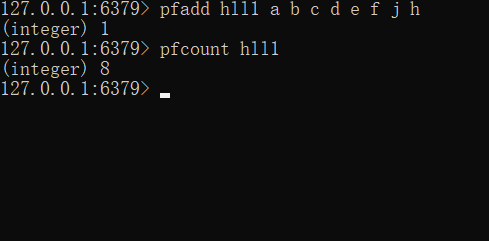
PFMERGE destkey sourcekey [sourcekey ...]接下来我们对该方法进行测试,首先我们对 hll1 这个key进行插入,插入结果如下
那么接下来插入key为 hll2 的数据,执行结果结果如下
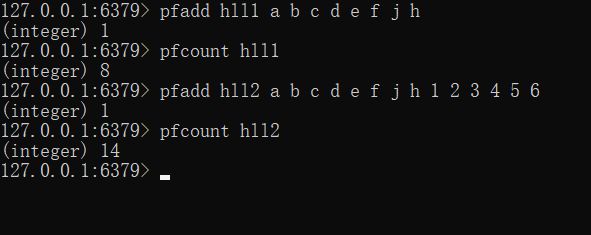
在 key 为 hll2 的数据完全包含了key为 hll1 的值时,我们对两个 key 进行联合统计,观察输出结果

可以看到,我们的统计结果是进行了去重后再进行统计的。那么接下来测试合并方法

hll2 的数据会合并到 hll1 中,该方法的存在,我们可以设置ip访问时设置 key 为年月日,这样我们可以通过合并每天的key来统计每月的活跃人数。接下来我们测试HLL的内存占用情况
首先是我们先获取没有存储100w数据情况时的内存使用情况,需要注意的时,该值为字节值,需要我们自己转化为kb

测试代码如下,我们需要创建100w的对象来模拟访问量通过HLL存储,我们测试Redis的占用情况
@Test
public void test01() throws Exception {String[] str = new String[1000];int j =0;for (int i = 0; i < 1000000; i++) {j = i%1000;str[j] = "user"+i;if (j == 999){stringRedisTemplate.opsForHyperLogLog().add("hll1",str);}}Long count = stringRedisTemplate.opsForHyperLogLog().size("hll1");System.out.println(count);
}执行完测试代码后的内存占用情况以及统计结果如下,内存占用变为 900992,统计次数为 1001788,可以看到存在一定误差,但是对于100w数据来说基本可以忽略不计。
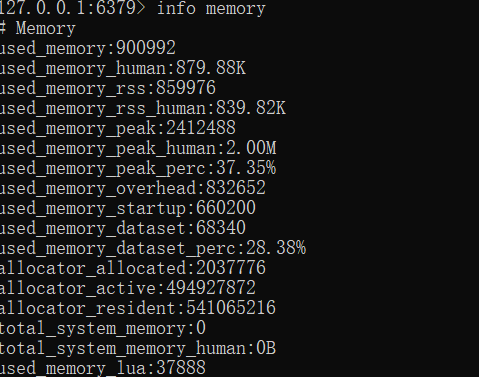
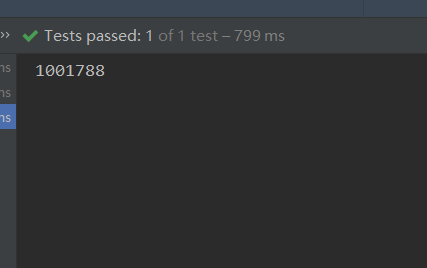
计算添加完数据后的内存占用(900992-886608)/1024 ≈ 14k。并且无论执行多少次添加数据操作,只要对象不发生改变,永远统计到的数量为1001788。
这篇关于Redis中HyperLogLog的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




