本文主要是介绍基于Redis的Hyperloglog实现日活量和总活跃量统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景介绍
产品提出想要统计目前系统中某个页面日活量与总活跃用户数量,由于这个页面登录与未登录用户均可访问,因此不能通过用户id来统计,要通过ip地址来做统计和去重处理。
二、技术选型
- 首先想到的方案是使用redis的set数据结构,因为它是一个无序集合,我们得到ip地址,然后存入set中即可实现统计与去重的效果,但是set有一个很大的问题是,每一条数据占用的空间会比较大,如果数据量很大的话可能会导致内存问题。
- 因此想到用一些比较节约空间的数据结构,想到了之前了解过的bitmap,空间占用比较低,不过bitmap比较适合预先知道用户数量的场景,我们知道总的用户数就知道到底需要定义一个多少容量的bitmap。而当前场景统计的ip总数是不确定的,因此bitmap不适用。
- 最终发现Redis的Hyperloglog数据结构非常的符合,Hyperloglog可以实现海量数据的统计与去重。与bitmap不同,它只是输入元素来计算基数,而不会存储元素本身。而这次需求不需要存储具体ip的值,只需要统计整体数量,并去重即可。
三、具体实现
- 首先要使用一个IPUtil工具类,用来获取访问网站用户的ip。
/*** @Author: qubingquan* @Date: 2020/9/14 1:51 下午*/
public class IPUtil {/*** 获取用户真实IP地址,不使用request.getRemoteAddr();的原因是有可能用户使用了代理软件方式避免真实IP地址。* 可是,如果通过了多级反向代理的话,X-Forwarded-For的值并不止一个,而是一串IP值,究竟哪个才是真正的用户端的真实IP呢?* 答案是取X-Forwarded-For中第一个非unknown的有效IP字符串* @param request* @return*/public static String getIpAddress(HttpServletRequest request) {String ip = request.getHeader("x-forwarded-for");if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {ip = request.getHeader("Proxy-Client-IP");}if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {ip = request.getHeader("WL-Proxy-Client-IP");}if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {ip = request.getHeader("HTTP_CLIENT_IP");}if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {ip = request.getHeader("HTTP_X_FORWARDED_FOR");}if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {ip = request.getRemoteAddr();if("127.0.0.1".equals(ip) || "0:0:0:0:0:0:0:1".equals(ip)){//根据网卡取本机配置的IPInetAddress inet=null;try {inet = InetAddress.getLocalHost();} catch (UnknownHostException e) {e.printStackTrace();}ip= inet.getHostAddress();}}return ip;}
}
- 之后我们使用redisTemplate,用来执行Hyperloglog有关命令。
//获取访问者的ipString ipAdress = IPUtil.getIpAddress(httpServletRequest);log.debug("访问列表页的ip地址为:[{}]",ipAdress);//将ip存入redisHyperLogLogOperations<String,String> hyperlog = redisTemplate.opsForHyperLogLog();hyperlog.add("cpp_bank_list_total_size_today",ipAdress);
这里执行的是 PFADD 命令,用来将数据存入一个Hyperloglog数据结构。我们将这次访问的ip存入 cpp_bank_list_total_size_today 这个变量中。
- 最后我们看每日0点执行的定时任务
private static String COUNT = "cpp_bank_list_total_size_today";private static String TOTAL_COUNT = "cpp_bank_list_total_size";private static String TOTAL_ID = "0";@Scheduled(cron = "0 0 0 * * ?")//@Scheduled(cron = "*/5 * * * * ?")public void saveUserAccessLog(){HyperLogLogOperations<String,String> hyperlog = redisTemplate.opsForHyperLogLog();int count = hyperlog.size(COUNT).intValue();Calendar calendar = Calendar.getInstance();calendar.add(Calendar.DAY_OF_MONTH,-1);CppBankAccessLog cppBankAccessLog = CppBankAccessLog.builder().id(Sequence.getInstance().getSequenceNumber()).time(new SimpleDateFormat("yyyy-MM-dd").format(calendar.getTime())).count(count).build();cppBankAccessLogMapper.insertSelective(cppBankAccessLog);//合并每天的访问量到总计中hyperlog.union(TOTAL_COUNT,COUNT);int totalCount = hyperlog.size(TOTAL_COUNT).intValue();cppBankAccessLogMapper.updateCountById(TOTAL_ID,totalCount);log.info("日活量信息入库,昨日数据:[{}],总数据:[{}]",count,totalCount);//删除today中的数据hyperlog.delete(COUNT);}
这里主要做的事情是把当天统计数据入库,之后使用union命令把当天的日活量与总活跃量取并集,再之后入库总活跃量,删除当日日活数据。
四、Hyperloglog原理介绍
首先要说明,HyperLogLog实际上不会存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量。这样做存在误差,不适合绝对准确计数的场景。
redis中实现的HyperLogLog,只需要12K内存,在标准误差0.81%的前提下,能够统计2的64次方个数据。
- 伯努利实验
想要了解Hyperloglog原理,首先要了解伯努利实验。
伯努利实验就是抛硬币,抛几次硬币,之后看最长是抛几次才可以得到正面,如下图所示。
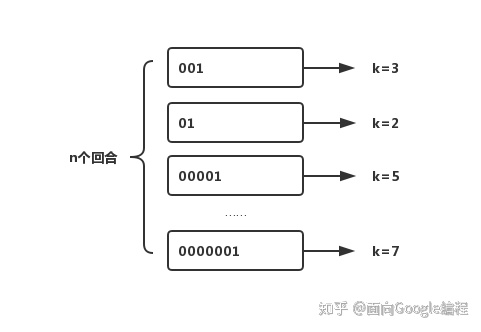
k是每回合抛到1所用的次数,我们已知的是最大的k值,可以用kmax表示,由于每次抛硬币的结果只有0和1两种情况,因此,kmax在任意回合出现的概率即为
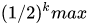
因此可以推导出
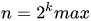
但这样做误差率是很大的,如k为3,我们会得到抛出的次数为8,但很可能我抛出第一次就是001,即k为3。
为了降低误差率,引入了桶的概念,计算m个桶的加权平均值。
下面是LogLog的估算公式:
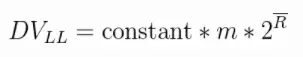
上面公式的DVLL对应的就是n,constant是修正因子,它的具体值是不定的,可以根据实际情况而分支设置。m代表的是试验的轮数。头上有一横的R就是平均数:(k_max_1 + … + k_max_m)/m。
这种通过增加试验轮次,再取k_max平均数的算法优化就是LogLog的做法。而 HyperLogLog和LogLog的区别就是,它采用的不是平均数,而是调和平均数。调和平均数比平均数的好处就是不容易受到大的数值的影响。
例:
求平均工资:
A的是1000/月,B的30000/月。采用平均数的方式就是: (1000 + 30000) / 2 = 15500
采用调和平均数的方式就是: 2/(1/1000 + 1/30000) ≈ 1935.484
调和平均数公式:
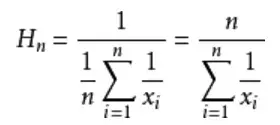
- Hyperloglog
对于一个输入的字符串,首先得到64位的hash值,用前14位来定位桶的位置(共有 2的14次方 ,即16384个桶)。后面50位即为伯努利过程,每个桶有6bit,记录第一次出现1的位置count,如果count>oldcount,就用count替换oldcount。
模仿上面的流程,多个不同的用户 id,就被分散到不同的桶中去了,且每个桶有其 k_max。然后当要统计出页面有多少用户点击量的时候,就是一次估算。最终结合所有桶中的 k_max,代入估算公式,便能得出估算值。
每个桶有6bit,即[000 000],最大为[111 111],表示63。
五、写在最后
实际redis会有稀疏存储结构和密集存储结构两种实现,想要了解更多请查阅下方参考资料,有全面的介绍。
六、参考资料
Hyperloglog原理
这篇关于基于Redis的Hyperloglog实现日活量和总活跃量统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




