本文主要是介绍redis数据结构详解(基本数据结构,位图,HyperLogLog,GeoHash,布隆过滤器),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
redis数据结构详解
文章目录
- redis数据结构详解
- 1. 五种基本数据结构
- 1.1 String
- 1.2 list
- 1.3 hash
- 1.4 set
- 1.5 zset
- 2. 高级特性
- 2.1 位图
- 2.2 HyperLogLog
- 2.3 Geo Hash
- 2.4 布隆过滤器
参考书籍: 老钱的redis深度历险
1. 五种基本数据结构
1.1 String
String是Redis最简单得数据结构,它的内部表示就是一个字符数组。
字符串结构使用比较广泛,一个常见得用途就是用来缓存用户信息,我们将用户信息使用序列化技术转换成字符串,然后将序列后得字符串放进redis来缓存。
Redis得字符串是动态字符串,是可以修改得字符串,内部结构的是西安类似于Java的ArrayList,采用预分配冗余空间的频繁。如下图所示:
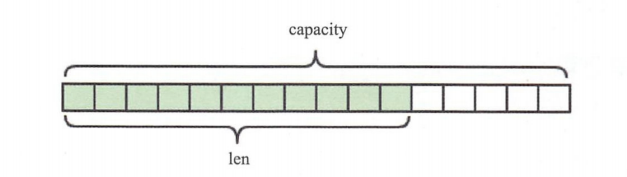
内部为当前字符串分配的实际空间capacity一般要高于实际字符串长度len.当字符串长度小于1mb时,扩容都是加倍现有的空间,如果字符串长度超过1MB,扩容时只会多扩1MB的空间。
字符串的最大长度为512MB。
当value是一个整数时还可以进行递增递减等操作。
常用命令
#简单命令 赋值操作
set key value
#简单命令 取值操作
get key
#简单命令 删除操作
del key
# 当value是整数时 ,可以使用incr或 incrby
incr/decr key
incrby/decrby key 5 #批量写
mset k1 v1 k2 v2 k3 v3
#批量读
mget k1 k2 k3#过期时间
expire key second
#setex的使用
setex key second value#setnx 操作 如果key不存在则赋值成功,如果key存在则赋值失败返回0 (可以借助setnx实现分布式锁)
setnx key value
1.2 list
Redis中的list是一个双向链表。
所以说可以通过list构建两种数据结构:
- FIFO队列 先进先出
- FILO栈 先进后出
实现FIFO队列:
如果是左边推,那么就右边出
如果是右边推,那么就左边出
实现FILO栈:
如果左边推,那么左边出
如果右边推,那么就右边出
常用命令
#FIFO 队列
rpush queue 1 2 3 4 5
lpop queue 5(该数字表示弹出几个元素)#FILO 栈
rpush queue 1 2 3 4 5
rpop queue 5#根据索引获取值(获取之后并不删除,pop操作获取之后会从原先链表中删除)
# index可以为负数,为负数则表示倒数第几个
lindex key index#分页操作
# 0 ~-1 表示获取所有元素
lrange key 0 -1
再深入一些,会发现redis底层存储的不是一个简单的linkedList,而是称之为快速链表(quicklist)的一个结构。
首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,既压缩列表。他将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会浪费空间,还会加重内存碎片化。比如普通链表里存得知识Int类型的数据,结构上还需要两个额外的指针prev和next。 所以Redis将链表和ziplist结合起来组成quicklist,也就是将多个ziplist使用双向指针串起来使用,quicklist既满足了快速的插入删除性能,也不会出现太大的空间冗余。如下图所示:

1.3 hash
hash 字典其实就相当于java中的HashMap 平时开发中也可以使用hash存储java对象。
常用命令
hset key field value
hget key field
1.4 set
set 集合相当于Java语言中的HashSet, 内部的键值对是无序的,并且具有去重功能
常用命令
# 增加
sadd key member(member代表存储的元素,可以批量操作跟多个member)#获取集合所有元素
smembers key #集合长度
scard key#判断某一个元素(value)是否存在 存在返回1 否则返回0 相当于containsKey()
sismember users value #弹出一个
spop users1.5 zset
zset可能是Redis提供的最有特色的数据结构。
它类似于Java的SoredSet和HashMap的结合体,一方面它是一个set,保证了内部value的唯一性,另一方面它给每一个value赋予一个score,代表了这个value的排序权重。内部实现是 跳跃列表的数据结构,在Java中有skipList这种的跳表实现。跳表结构: 其实就是一种分层的数据结构,将底层的数据采用硬币算法(随机0 或 1)当为0时向上衍生一层,依次类推整个数据结构,当然该数据结构具有不稳定性,只有当数据足够大的时候,才会趋近于一种平衡状态。
常用命令:
#添加元素
zadd key score value
#获取全部元素 按照score 降序排列
zrange key 0 -1
#获取全部元素 按照score 升序排列
zrevrange key 0 -1
# 获取长度
zcard key #获取指定value的score
zscore key value
2. 高级特性
2.1 位图
位图并不是什么特殊的数据结构,它的内容其实就是普通的字符串,也就是byte数组。
我们可以使用普通的get/set直接获取和设置整个位图的内容,也可以使用位图操作getbit/setbit等将byte数组看成位数组来处理。
应用场景:
平时的开发过程中,会有一些布尔类型数据需要存取,比如签到,签了就是1,没签就是0,要记录365天,如果使用普通的key/value,每个用户要记录365个,当用户体量过大时,需要的存储空间是惊人的。
为了解决这个问题,Redis提供了位图数据结构,这样每天的签到纪录只占据一个位,365天就是365位,大约46个字节。这样就大大节约了存储空间。位图的最小单位是比特(bit)。
下面演示bitmap位图的一个零存整取的一个案例:
字符A 的ASCII码值为:65 ,转成二进制就是 0100 0001
位数组的顺序与字符数组顺序相反,也就是我们只需要在 索引1 位置和7位置设置 1 即可得到字符A

统计和查找
Redis提供了位图统计指令bitcount和位图查找指令bitpos。
bitcount用来统计指定范围内1的个数,bitpos用来查找指定范围内出现的第一个0或1
比如我们可以通过bitcount统计用户一共签到了多少天,通过bitpos指令查找用户从那一天开始第一次签到,如果指定了范围参数[start,end] ,就可以统计在某个时间范围内用户签到了多少天,用户自某天以后的那天开始签到。
实战

2.2 HyperLogLog
HyperLogLog提供不精确的去重计数方案,虽然不准确,但是也不是非常离谱,标准误差是0.81%
应用场景:
首先解释下 uv和pv
pv: 页面浏览量或点击量既页面刷新的次数,每一次页面刷新,就算做一次PV流量。
uv: 独立访客数,指访问某个站点或点击某个网页不同IP地址的人数,UV值记录第一次进入网站的具有独立IP的访问者,在同一天内多次访问则只记录一次
你有一个网站,需要统计每个网页每天的UV数据,你会如何实现呢?
如果统计PV,非常好办,每个网页配一个redis计数器就可以了,把这个计数器的key后缀加上当天的日期。这样来一个请求就incr 一下。
但是UV不同,需要去重,当然我们可以使用set集合来存储当天访问过页面的用户IP。
但是,当页面访问量非常大时,比如一个爆款页面可能有上千万的UV,那么就需要一个很大的set集合来统计,这就非常浪费空间。如果这样的页面很多,那么需要的存储空间是惊人的。
HyperLogLog就是解决这样的问题的。
实战: 统计uv value是用户id
public static void main(String[] args) {Jedis jedis = new Jedis("127.0.0.1", 6379);for (int i = 0; i < 1000; i++) {jedis.pfadd("uv", "userid" + i);}}

可以看到误差是0.004
多了几个,那么它到底具备不具备去重呢?
改造代码如下
public static void main(String[] args) {Jedis jedis = new Jedis("127.0.0.1", 6379);for (int i = 0; i < 1000; i++) {jedis.pfadd("uv", "userid" + i);}for (int i = 0; i < 10; i++) {jedis.pfadd("uv", "userid999");}}

可以看到pfcount还是1004,是具备去重功能的,只不过有误差.
2.3 Geo Hash
2.4 布隆过滤器
这篇关于redis数据结构详解(基本数据结构,位图,HyperLogLog,GeoHash,布隆过滤器)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





