huffman专题
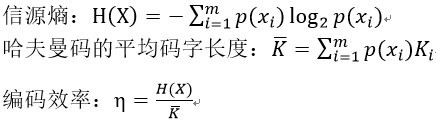
数字视频编码概述(熵编码/Huffman编码)
1. 数字视频压缩的必要性和可能性 按ITU-R BT. 601建议,数字化后的输入图像格式为720*576像素,帧频为25帧/s,采样格式为4:2:2,量化精度为8bit, 则数码率:(720 * 576 + 360 * 576 + 360 * 576) * 25帧/s * 8bit = 165.888Mbit/s。 如果视频信号数字化后直接存放在650MB的光盘中,在不考虑音频信号的

数据结构-非线性结构-树形结构:有序树 ->二叉树 ->哈夫曼树 / 霍夫曼树(Huffman Tree)【根据所有叶子节点的权值构造出的 -> 带权值路径长度最短的二叉树,权值较大的结点离根较近】
哈夫曼树概念:给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。 哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。 一、相关概念 二叉树:每个节点最多有2个子树的有序树,两个子树分别称为左子树、右子树。有序的意思是:树有左右之分,不能颠倒 叶子节点:一棵树当中没有子结点的结点称为叶子

Huffman算法简介
Huffman算法是一种基于统计的压缩方法。它的本质就是对文本文件中的字符进行重新编码,对于使用频率越高的字符,其编码也越短。但是任何2个字符的编码,是不能出现向前包含的。也就是说字符A的编码的前段,不可能为字符B的编码。经过编码后的文本文件,主要包含2个部分:Huffman码表部分和压缩内容部分。解压缩的时候,先把Huffman码表取出来,然后对压缩内容部分各个字符进行逐一解码,形成源文件。

huffman树概念、构造方法及huffman编码
概念 Huffman树概念 Huffman树(霍夫曼树),也称为最优二叉树,是一种特殊的二叉树,广泛应用于数据压缩领域。它基于字符出现的频率或概率构建,使得整体的平均编码长度最小,从而达到压缩数据的目的。在Huffman树中,频率或概率越高的字符距离根节点越近,这样可以确保常用字符使用较短的编码,不常用字符使用较长的编码。 Huffman树的构造方法 初始化:将待编码的字符及其频率作为叶子

Huffman算法压缩解压缩(C)
1 概述 Huffman压缩算法是一种基于字符出现频率的编码算法,通过构建Huffman树,将出现频率高的字符用短编码表示,出现频率低的字符用长编码表示,从而实现对数据的压缩。以下是Huffman压缩算法的详细流程: 统计字符频率:遍历待压缩的数据,统计每个字符出现的频率。 构建优先队列:将每个字符及其频率作为一个结点放入优先队列(或最小堆)中,根据字符频率构建一个按频率大小排序的优先队列。 构
Huffman树的建立、字符界面下的显示及序列化(一)
本文主要是Clifford A. Shaffer所著的《Data Structures and Algorithm Analysis in C++》一书中项目设计习题5.7的实现。 Huffman树是一种可以用来压缩文件的技术。为在计算机上存取文件,需要为文件中的每个字符分配一个编码,一般情况下,每个字符的编码长度相同。例如,每个ASCII字符的编码长度为8位。那么,保存一个有着1000个字符的
中文压缩和解码程序设计与实现(huffman)
本项目是利用huffman算法进行中文压缩和解码的设计与实现,huffman算法被证明是最优的结构,可以用于数据压缩 源码 /**************************************************************************************** this function is about to compress a file
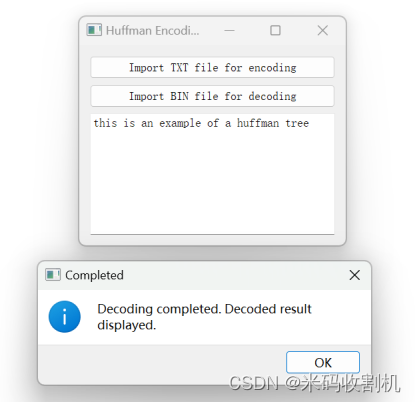
【C++】C++ QT实现Huffman编码器与解码器(源码+课程论文+文件)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C++/Python语言 👉公众号👈:测试开发自动化【获取源码+商业合作】 👉荣__誉👈:阿里云博客专家博主、51CTO技术博主 👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。 C++ QT实现Huffman编码器与解码器(源码+课程论文+文件)【独一无二】 目录 C++ QT实现Huffman
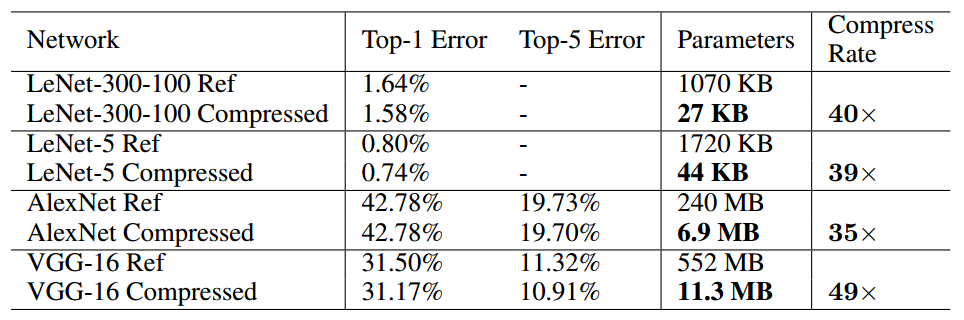
Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding
本次介绍的方法为“深度压缩”,文章来自2016ICLR最佳论文 《Deep Compression: Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding 转自:http://blog.csdn.net/shuzfan/article/details/51383809 (内含多
uvalive 2088 - Entropy(huffman编码)
题目连接:2088 - Entropy 题目大意:给出一个字符串, 包括A~Z和_, 现在要根据字符出现的频率为他们进行编码,要求编码后字节最小, 然后输出字符均为8字节表示时的总字节数, 以及最小的编码方式所需的总字节数,并输出两者的比率, 保留一位小数。 解题思路:huffman编码。 #include <stdio.h>#include <string.h>#
C程序实践 哈夫曼(Huffman)树代码
/*Slyar2009.10.29*/#include <stdio.h>#include <stdlib.h>#include <io.h>#define N 255#define M 2*N - 1/* 运行成功标记 */int ok = 0;/* 保存原文件名 */char file[20] = {};/* 哈夫曼树节点类型 */typedef struct{int da
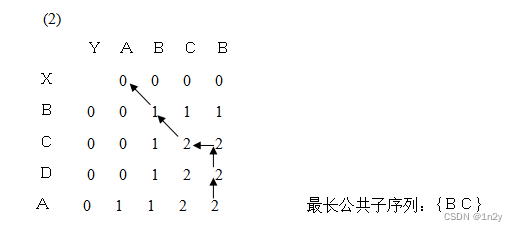
算法设计与分析 例题 绘制Huffman树、循环赛、分治、最短路与动态规划
1.考虑用哈夫曼算法来找字符a,b,c,d,e,f 的最优编码。这些字符出现在文件中 的频数之比为 20:10:6:4:44:16。要求: (1)(4 分)简述使用哈夫曼算法构造最优编码的基本步骤; (2)(5 分)构造对应的哈夫曼树,并据此给出a,b,c,d,e,f 的一种最优编码。 解:1)、哈夫曼算法是构造最优编码树的贪心算法。其基本思想是,首先所 有字符对应n 棵树构成的森林
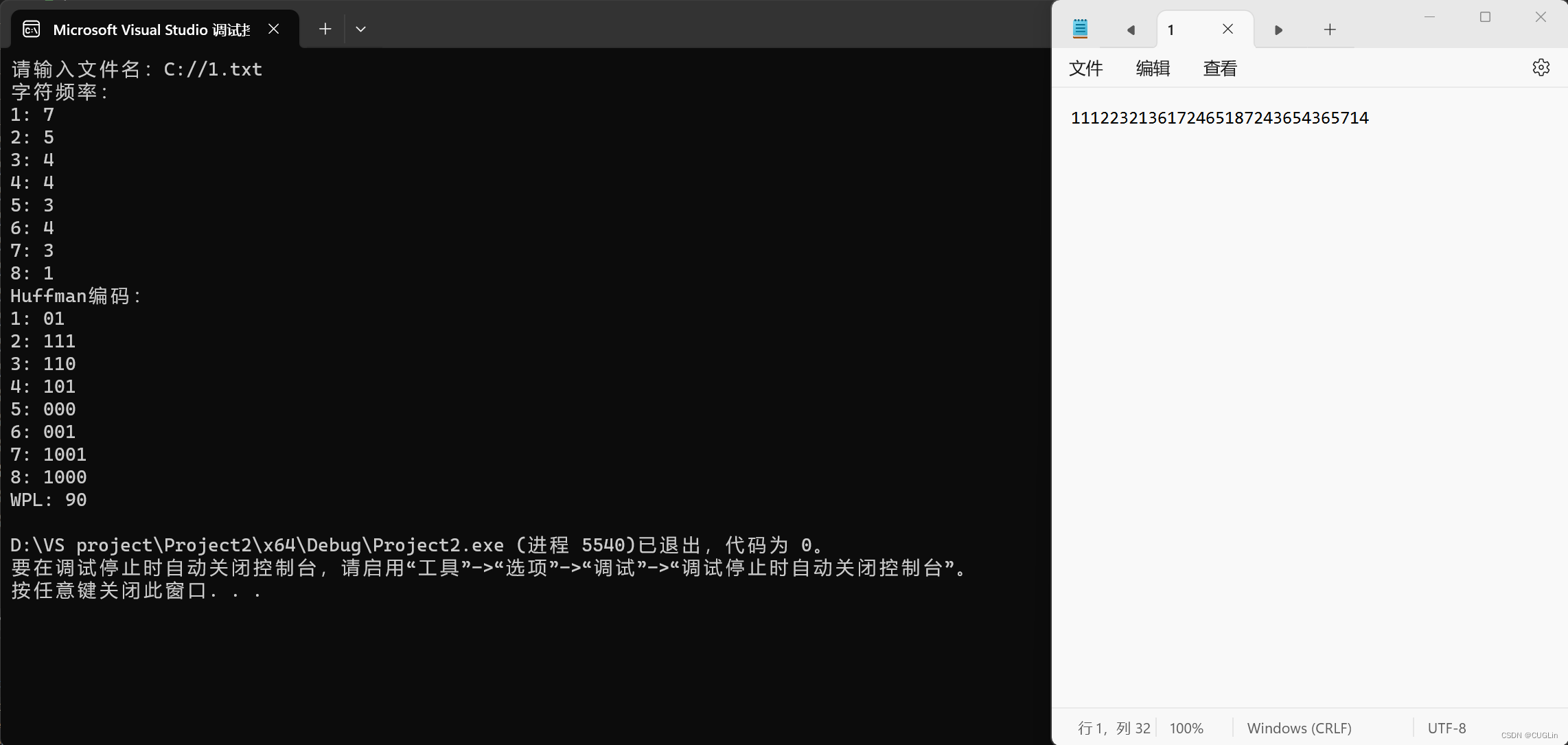
基于Huffman编码的字符串统计及WPL计算
一、问题描述 问题概括: 给定一个字符串或文件,基于Huffman编码方法,实现以下功能: 1.统计每个字符的频率。 2.输出每个字符的Huffman编码。 3.计算并输出WPL(加权路径长度)。 这个问题要求对Huffman编码算法进行实现和扩展,具体涉及以下步骤: 1.从键盘输入或文件中读取字符串/内容。 2.统计每个字符的出现频率。 3.根据频率构建Huffman树。
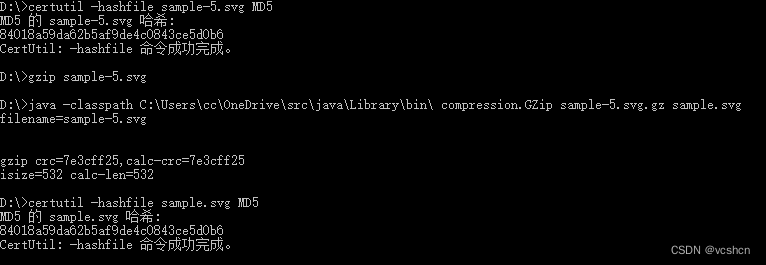
Inflate动态Huffman解压缩
上个已经实现GZIP压缩文件格式的Inflate静态Huffman解压,这个实现Inflate的无压缩输出和动态Huffman解压。 Java语言实现,Eclipse下编写。 范式Huffman解码实现,输入huffman编码,输出原始数据 // 范式huffman解码static class CanonicalCode {Vector<Node> table = new Vecto

GZIP文件格式解析和Inflate静态Huffman解压缩
GZIP是封装了Deflate压缩的格式文件;Deflate使用了无压缩、Huffman+LZ77进行压缩;解压是Inflate,Huffman包括静态Huffman压缩和动态Huffman压缩两种模式。 Java语言实现了GZIP格式解析、Inflate的静态Huffman解压缩、CRC32校验 算法。 gzip文件格式解析代码 BinaryInputStream bis = n
Huffman编译器和译码器设计(一)
1. 需求分析 设计一个哈夫曼算法的编码和译码系统,重复地显示并处理以下项目,知道选择退出为止。 将权值数据存放在数据文件中;分别采用动态和静态存储结构; 1. 读权重数据文件获得权重和字符的对应数组2. 手动输入字符与对应权重值3. 通过权重字符对应数组生成哈弗曼树4. 利用建立好的哈弗曼树生成哈弗曼编码5. 通过建立好的哈弗曼树解析哈弗曼编码生成译码
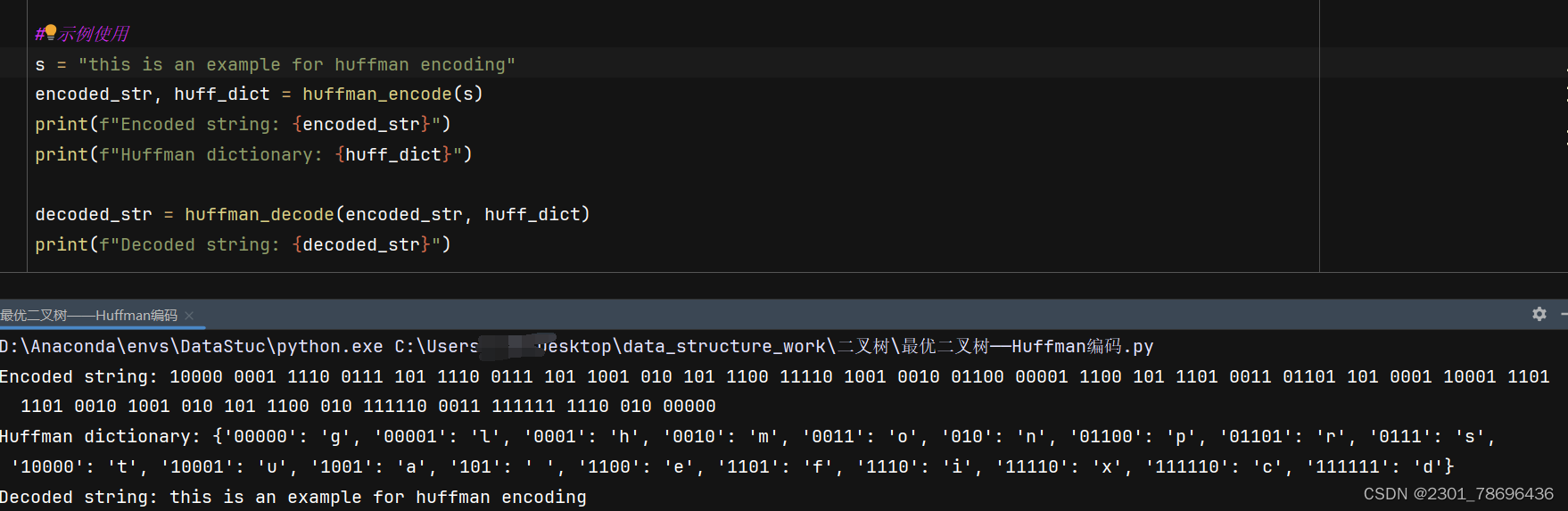
Huffman编码的Python的实现
Huffman编码的Python的实现 基本原理及步骤 Huffman编码是一种贪心算法,用于无损数据压缩。它基于字符在数据中出现的频率来构建编码,频率高的字符使用较短的编码,而频率低的字符使用较长的编码。这种方式的目的是减少数据的大小,因为最常见的字符使用最短的编码,从而在整体上减少了所需的位数。 实现Huffman编码的原理如下: 频率统计: 如果输入数据是一个字符串,代码会遍历这个字符
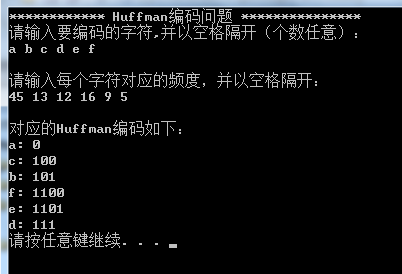
《算法导论》实验四:哈夫曼(Huffman)编码问题(C++实现)
一、题目描述 哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。其压缩率通常在20%~90%之间。哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。一个包含100,000个字符的文件,各字符出现频率不同,如下表所示: 有多种方式表示文件中的信息,若用0,1码表示字符的方法,即每个字符用唯一的一个0,1串表示。若采用定长编码表示,则需要3位表示一个字
二叉树应用——最优二叉树(Huffman树)、贪心算法—— Huffman编码
1、外部带权外部路径长度、Huffman树 从图中可以看出,深度越浅的叶子结点权重越大,深度越深的叶子结点权重越小的话,得出的带权外部路径长度越小。 Huffman树就是使得外部带权路径最小的二叉树 2、如何构造Huffman树 (1)步骤 (1)根据给定的n个权值{W1,W2,…,Wn},构造n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树中均只含有一个带权值为Wi的根结点
JPEG—范式哈夫曼编码(Canonical Huffman Code)
本文来自:https://www.cnblogs.com/k1988/archive/2010/05/18/2165646.html 在大部分介绍JPEG的中文书中都是将全部的JPEG的霍夫曼表给出,可是实际的JPEG文件头并不长,这个使得初看者很迷惑,这么短是如何存储那么长的霍夫曼表。其实,JPEG的霍夫曼表是由一定规则生成,只要给出少量的描述即可生成相应的JPEG的霍夫曼表。
贪心:huffman编码
题目:一位老木匠需要将一根长的木棒切成N段。每段的长度分别为L1,L2,......,LN(1 <= L1,L2,…,LN <= 1000,且均为整数)个长度单位。我们认为切割时仅在整数点处切且没有木材损失。 木匠发现,每一次切割花费的体力与该木棒的长度成正比,不妨设切割长度为1的木棒花费1单位体力。例如:若N=3,L1 = 3,L2 = 4,L3 = 5,则木棒原长为12,木匠可以有多种
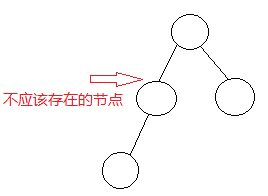
PTA Huffman Codes 思路分析及具体实现 v1.0
PTA 7-9 Huffman Codes 思路分析及具体实现 一、前导1. 写在前面2. 需要掌握的知识3. 题目信息 二、解题思路分析1. 题意理解2. 思路分析(重点) 三、具体实现1. 弯路和bug2. 代码框架(重点)2.1 采用的数据结构(重点)2.2 程序主体框架2.3 各分支函数(重点) 3. 完整编码 四、参考 一、前导 目前只做到了AC ( ╯□╰ ),代码质
【MOOC-浙大数据结构】第五周的编程作业——堆并查集Huffman编码
1.堆中的路径 #include <stdio.h>#include <algorithm>#include <stdlib.h>using namespace std;int h[1001]; int main(){h[0]=-10001;int n,m,i,j,x,size=0;scanf("%d%d",&n,&m);for(i=0;i<n;i++){scanf("%d",&x
贪心Huffman数(合并果子)
题目 在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。 达达决定把所有的果子合成一堆。 每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。 可以看出,所有的果子经过 n−1 次合并之后,就只剩下一堆了。 达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。 因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省
【算法概论】Huffman树
1、哈夫曼树,又叫最优二叉树:效率最高的判决数。 2、回忆树的相关知识 ① 路径长度:路径上的结点数 - 1。 ② 结点的权:在许多应用中,常常给树的结点赋予一个有意义的数,称为该结点的权。 ③ 结点的带权路径长度:该结点到树根的路径长度 × 该结点的权。 ④ 树的带权路径长度:树上所有叶子结点的带权路径长度之和,通常记作 WPL 。 3、哈夫曼树定义 在权为w1, w
05-树9 Huffman Codes (30分)
05-树9 Huffman Codes (30分) In 1953, David A. Huffman published his paper "A Method for the Construction of Minimum-Redundancy Codes", and hence printed his name in the history of computer science