本文主要是介绍数字视频编码概述(熵编码/Huffman编码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 数字视频压缩的必要性和可能性
| 按ITU-R BT. 601建议,数字化后的输入图像格式为720*576像素,帧频为25帧/s,采样格式为4:2:2,量化精度为8bit, 则数码率:(720 * 576 + 360 * 576 + 360 * 576) * 25帧/s * 8bit = 165.888Mbit/s。 如果视频信号数字化后直接存放在650MB的光盘中,在不考虑音频信号的情况下,每张光盘只能存储31s的视频信号。 |
数据压缩的理论基础是信息论。从信息论的角度来看,压缩就是去掉数据中的冗余,即保留不确定的信息,去掉确定的信息(可推知的),也就是用一种更接近信息本质的描述来代替原有冗余的描述。数据图像和视频数据中存在着大量的数据冗余和主观视觉冗余,因此图像和视频数据压缩不仅是必要的,而且也是可能的。
1.1 空间冗余
空间冗余也称空域冗余,是一种与像素间相关性直接联系的数据冗余。例如:数字图像的亮度信号和色度信号在空间域(X,Y坐标系)虽然属于一个随机场分布,但是他们可以看成为一个平稳的马尔可夫场。通俗讲,图像像素点在空间域中的亮度值和色度信号值,除了边界轮毂外,都是缓慢变化。因此,图像的帧内编码,即以减少空间冗余进行数据压缩。
1.2 时间冗余
时间冗余也称为时域冗余,它是针对视频序列图像而言的。视频序列每秒有25 ~ 30帧图像,相邻帧之间的时间间隔很小(例如,帧频为25Hz的电视信号,期帧间间隔只有 0.04s),使得图像有很强的相关性。因此,对于视频压缩而言,通常采用运动估值和运动补偿预测技术来消除时间冗余。
1.3 统计冗余
统计冗余也称编码表示冗余或符合冗余。由信息论的有关原来可知,为了表示图像数据的一个像素点,只要按其信息熵的大小分配相应的比特数即可。若用相同码长表示不同出现概率的符号,则会造成比特数的浪费。如果采用可变长编码技术,对出现概率大的符号用短码字表示,对出现概率小的符号用长码字表示,则可去除符号冗余,从而节约码字,这就是熵编码的思想。
1.4 结构冗余
在有些图像的部分区域内有着很相似的纹理结构,或是图像的各个部分之间存在着某种关系,例如自相似性等,这些都是结构冗余的表现。分形图像编码的基本思想就是利用了结构冗余。
1.5 知识冗余
在某些特定的应用场合,编码对象中包含的信息与某些先验的基本知识有关。这时,可以利用这些先验知识为编码对象建立模型。通过提取模型参数,对参数进行编码,而不是对图像像素值直接进行编码,可以达到非常高的压缩比。这是模型基编码(或称知识基编码、语义基编码)的基本思想。
1.6 人眼的视觉冗余
视觉冗余度是相对于人眼的视觉特性而言。压缩视觉冗余的核心思想是去掉那些相对人眼而言是看不到的或可有可无的图像数据。对视觉冗余的压缩通常反映在各种具体的压缩编码中。如对于离散余弦变换(DCT)系数的直流与低频部分采用细量化,而对高频部分采用粗量化。在帧间预测编码中,高压缩比的预测帧及双向预测帧的采用,也是利用了人眼对运动图像细节不敏感的特性。
2. 无失真编码和限失真编码
. 从信息论的角度出发,根据解码后还原的数据是否与原始数据完全相同,可将数据压缩方法分为两大类:无失真编码和限失真编码。
1) 无失真编码:
无失真编码又称无损编码、信息保持编码、熵编码。
熵指的是具体数据所含的平均信息量,定义为在不丢失信息的前提下描述该信息内容所需的最小比特数。
熵编码事纯粹基于信号统计特性的一种编码方法,他利用信源概率分布的不均匀性,通过变长编码来减少信源数据冗余,解码后还原的数据与压缩编码前的原始数据完全相同而不引入任何失真。
但无失真编码的压缩比较低,可达到的最高压缩比受到信源熵的理论限制:一般是2:1到5:1。最常用的无失真编码方法有哈夫曼(Huffman)编码、算术编码和游程编码(Run-Length Encoding,RLE)等。
2)限失真编码:
限失真编码也称有损编码、非信息保持编码、熵压缩编码。也就是说,解码后还原的数据与压缩编码前的原始数据有差别的,编码会一定程度的失真。
限失真编码方法利用了人类视觉的感知特性,允许压缩过程中损失一部分信息,虽然在解码时不能完全恢复原始数据,但是如果把失真控制在视觉阈值一下或者控制在可容忍的限度你,则不影响人们对图像的理解,却换来了高压缩比。在限失真编码中,允许的是真愈大,则可达到的压缩比愈高。
常见的限失真编码方法:预测编码、变化编码、矢量量化、基于模型编码等。
3. 熵编码
3.1 熵(Entropy):信源的平均信息量,更精确的描述为表示信源所有符号包含信息的平均比特数。
- 信源编码要尽可能的减少信源的冗余,使之接近熵
- 用更少的比特传递更多的信源信息
3.2 熵编码:数据压缩中根据信源消息的概率模型使消息的熵最小化
- 无损压缩
- 变长压缩
设信源X可发出的消息符号集合为A= { ai | i = 1,2,…m }并设X发出符号ai的概率为p(ai),则定义符号ai出现的自信息量为:
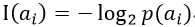
通常,式中的对数取2位底,这是定义的信息量单位为比特(bit)。
对信源X的各符号的自信息量去统计平均,可得每个符号的平均信息量:
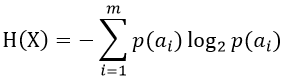
称H(X)为信源X的熵 (Entropy) ,单位为bit/符号,通常也称为X的一阶熵,它的含义是信源X发出任意一个符号的平均信息量。
例:二进制编码中,符号“1”发生的概率是p,符号“0”的发生概率是1 - p,计算二进制编码的熵。 |
3.4 定长编码:
 |
3.5 变长编码
3.5.1 变长编码:用不同的比特数表示每一个符号
- 为频繁发生的符号分配短码字
- 为很少发生的符号分配长码字
- 比定长编码有更高的效率
3.5.2 常用的变长编码:
- Huffman编码
- 算术编码
- 如果011为一个有效码字,则0,1,01,11必不是有效码字
- 不会引起解码歧义
- 二叉树
- 树节点:表示符号或符号组合
- 分支:两个分支一个表示“0”,另一个表示“1”
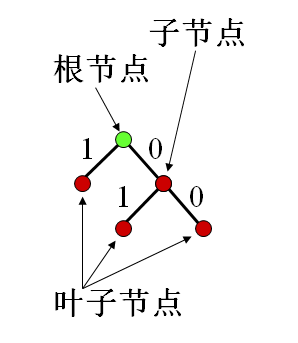
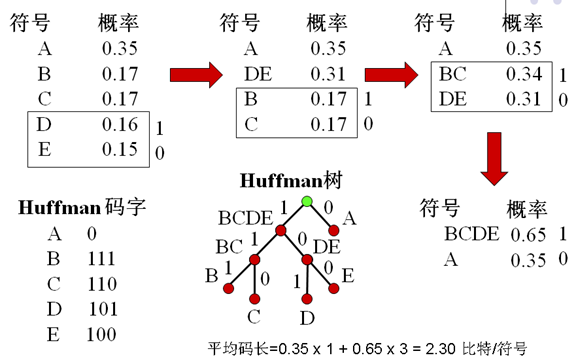
- 每次分支有两种选择:0,1
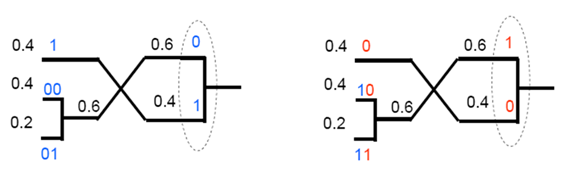
- 相同的概率产生不同的组合
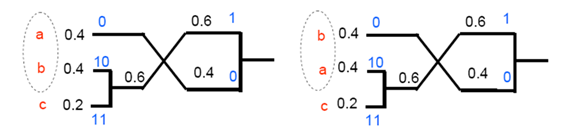
- 数据的概率变化难于实时统计
- Huffman树需要编码传输给解码器(对信源进行哈夫曼编码后,形成一个哈夫曼编码表,解码时,必须参照这一哈夫曼编码表才能正确解码)
- 只有在p(xi)=1/2ki时是最优编码(由于哈夫曼编码的依据是信源符号的概率分布,故其编码效率取决于信源的统计特性。当信源符号的概率相等时,其编码效率最低;只有在概率分布很不均匀时,哈夫曼编码才会收到显著效果;当符号出现概率分布为1/2ki 型时,哈夫曼编码能使平均码长降奥信源熵值H(x),编码效率为100%)
- 最小码字长度为1比特/符号
- 例如:p(1)=0.0625,p(0)=0.9375则H=0.3373比特/符号,Huffman编码平均码长=1比特/符号
- 两个符号联合编码有更高效率
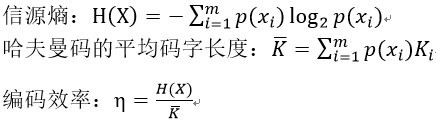
这篇关于数字视频编码概述(熵编码/Huffman编码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






