growth专题

理解机器学习实战 --- FP-Growth算法高效发现频繁项集
FP-growth算法介绍: 一种非常好的发现频繁项集的算法 基于Apriori算法构建,但是数据结构不同,使用叫做FP树的数据结构来存储集合。 FP-grouw算法原理: 基于数据集构造FP树 支持度:某一项类别出现的次数,可以理解为出现的频率。 非频繁项:某一项出现的次数小于一定次数,我们称之为非频繁项集。 步骤一: 1.遍历所有的数据集合,计算

电影数据集关联分析及FP-Growth实现
(1)数据预处理 我们先对数据集进行观察,其属性为’movieId’ ‘title’ ‘genres’,其中’movieId’为电影的序号,但并不完整,‘title’为电影名称及年份,‘genres’为电影的分类标签。因此电影的分类标签可以作为我们研究此数据集关联分析的文本数据。 我们可以看到电影的分类标签在同一个电影下不只有一个,且用’|’分开,因此我们对数据进行以下

weka实战004:fp-growth关联规则算法
apriori算法的计算量太大,如果数据集略大一些,会比较慢,非常容易内存溢出。 我们可以算一下复杂度:假设样本数有N个,样本属性为M个,每个样本属性平均有K个nominal值。 1. 计算一项频繁集的时间复杂度是O(N*M*K)。 2. 假设具有最小支持度的频繁项是q个,根据它们则依次生成一项频繁集,二项频繁集,....,r项频繁集合,它们的元素数量分别是:c(q, 1), c(q,
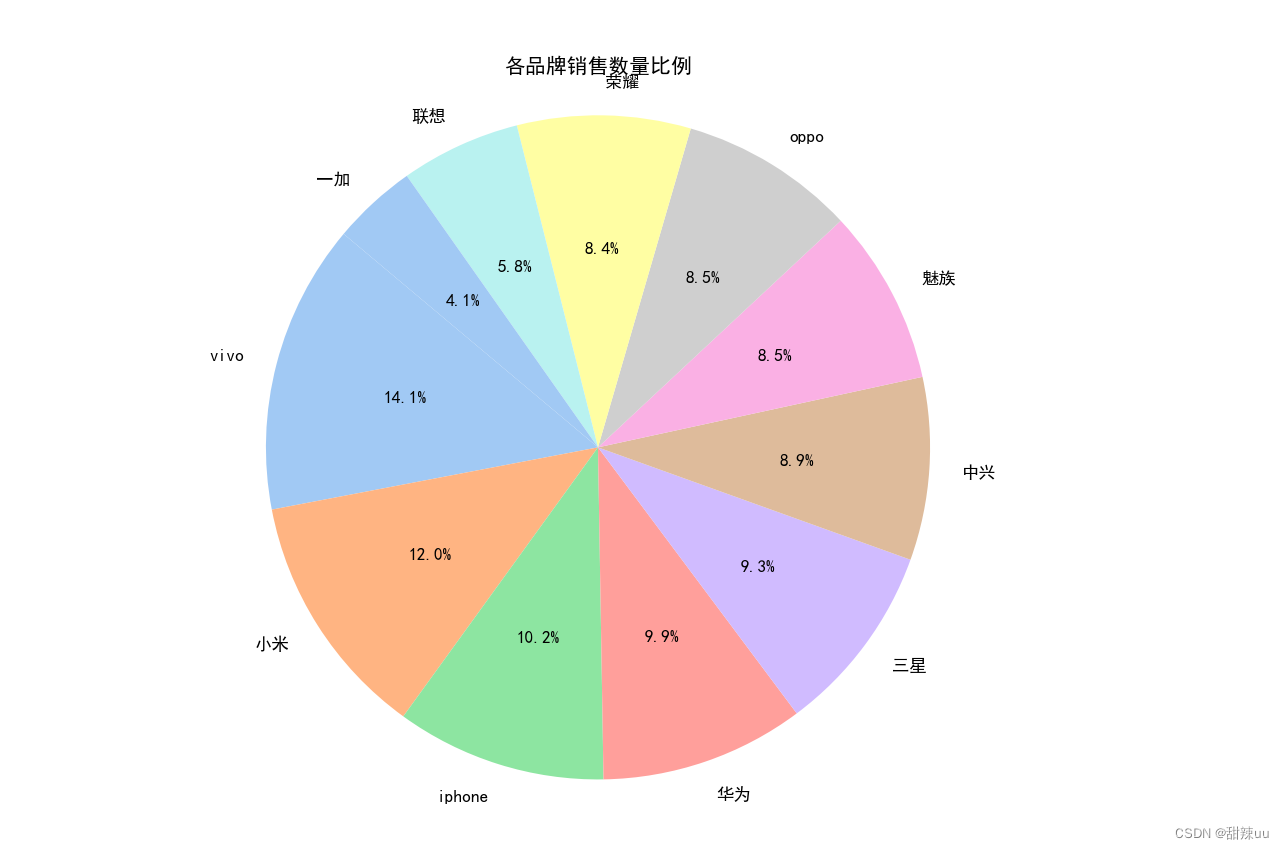
实战16:基于apriori关联挖掘FP-growth算法挖掘关联规则的手机销售分析-代码+数据
直接看视频演示: 基于apriori关联挖掘关联规则的手机销售分析与优化策略 直接看结果: 这是数据展示: 挖掘结果展示: 数据分析展示:

智能优化算法 | Matlab实现成长优化算法(Growth Optimizer,GO)(内含完整源码)
智能优化算法 | Matlab实现成长优化算法(Growth Optimizer,GO)(内含完整源码) 文章目录 智能优化算法 | Matlab实现成长优化算法(Growth Optimizer,GO)(内含完整源码)文章概述源码设计 文章概述 智能优化算法 | Matlab实现成长优化算法(Growth Optimizer,GO)(内含完整源码)成长优化算法(Gr
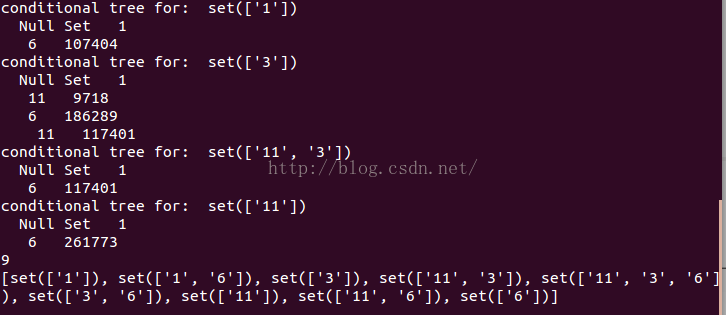
《机器学习实战》笔记之十二——使用FP-Growth算法来高效发现频繁项集
第十二章 使用FP-Growth算法来高效发现频繁项集 FP-growth算法,基于Apriori构建,但在完成相同任务时采用了不同的技术,其只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此其比Apriori算法快。FP算法需要将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对。 12.1 FP树:用于编


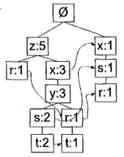
FP-growth算法来高效发现频繁集
FP-growth算法是一种高效发现频繁集的算法,比Apriori算法高效,但是不能用于发现关联规则。FP-growth算法只需要对数据即信两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否是频繁,所以FP-growth更快。FP-growth算法主要分为两个过程: 构建FP树;从FP树中挖掘频繁项集。 1.FP树介绍 FP代
Apriori 与 FP-growth 算法
关联规则挖掘:Apriori 与 FP-growth 算法 关联规则挖掘概述Apriori 算法基本原理应用实例 FP-growth 算法基本原理应用实例 其他机器学习算法:机器学习实战工具安装和使用 关联规则挖掘是数据挖掘领域中的一个重要任务,旨在发现数据集中不同项之间的关联关系。Apriori 算法和 FP-growth 算法是两种常用的关联规则挖掘算法,它们在挖掘频繁项集和
数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取、分析与分类研究。主要涉及到关联规则与序列模式挖掘两块。关联规则挖掘使用基于有趣性度量标准的FP-Growth算法,序列模式挖掘使用基于有趣性度量标准的GSP算法。若想实现以上优化算法,首先必须了解其基本算法,并编程实现。关键点还是在于理解算法思想,只有懂得

Python数据挖掘学习笔记(7)频繁模式挖掘算法----FP-growth
一、相关原理 FP-Growth算法是韩嘉炜等人在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快整个挖掘

第六章FP-Growth
海量数据下,Apriori算法的时空复杂度都不容忽视。 1)空间复杂度:如果L1数量达到104的量级,那么C2中的候选项将达到107的量级。 2)时间复杂度:每计算一次Ck就需要扫描一遍数据库。 此时,人们希望设计一种方法,“挖掘全部频繁项集而无须这种代价昂贵的候选产生过程”。一种试图这样做的有趣的方法称为频繁模式增长(FP-
《增长黑客》Growth Hacker互联网的市场营销
在看试读样章时看到的一句话:献给我的父母 和每一个为了理想在异乡打拼的逐梦人。 这句话是多么的有冲出力,淋漓尽致表达北漂一族和在外地打拼程序员的心声。 什么是增长黑客? 增长黑客(Growth Hacker)具体的说,就是一群以数据驱动营销、以市场指导产品,通过技术手段转化贯彻增长目标的人。他们通常既了解技术,又深谙用户心理,擅长发挥创意,绕过限制,通过低成本的手段
FII Tech Growth投资SECO
米兰--(美国商业资讯)--由FondoItaliano d’Investimento SGR管理的基金FII Tech Growth今日宣布,该基金向欧洲嵌入式电子市场领导者之一的SECO SpA进行了第二次投资。 SECO总部位于托斯卡纳区阿雷佐,由企业家Daniele Conti和Luciano Secciani于1979年创立,在美国、德国和台湾设有子公司。该公司致力于设计和制造

从零实现机器学习算法(十四)FP-growth
目录 1. FP-growth简介 2. FP-growth模型 2.1 FP-growth数据结构 2.2 频繁项集 2.3 关联规则 3. 总结与分析 1. FP-growth简介 FP-growth也是一种经典的频繁项集和关联规则的挖掘算法,在较大数据集上Apriori需要花费大量的运算开销,而FP-growth却不会有这个问题。因为FP-growth只扫描整个数据库两次

玩转大数据21:基于FP-Growth算法的关联规则挖掘及实现
1.引言 关联规则挖掘是大数据领域中重要的数据分析任务之一,其可以帮助我们发现数据集中项目之间的关联关系。关联规则挖掘是指在交易数据或者其他数据集中,发现一些常见的关联项,如购物篮中经常一起出现的商品组合。关联规则挖掘的应用非常广泛,如市场营销、推荐系统等领域。 2 FP-Growth算法原理 FP-Growth是一种关联分析算法,由韩嘉炜等人在2000年提出。它采取分治策略,将提供频繁
关于spark运行FP-growth算法报错com.esotericsoftware.kryo.KryoException
Spark运行FP-growth异常报错 在spark1.4版上尝试运行频繁子项挖掘算法是,照搬官方提供的python案例源码时,爆出该错误com.esotericsoftware.kryo.KryoException (java.lang.IllegalArgumentException: Can not set final scala.collection.mutable.ListBuffe
FP Growth原理
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结。作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈。为了解决这个问题,FP Tree算法(也称FP Growth算法)采用了一些技巧,无论多少数据,只需要扫描两次数据集,因此提高了算法运行的效率。下面我们就对FP Tree算法做一个总结。 1. FP Tree数据结构 为了减少I
关联分析算法Apriori 和 FP-Growth (Python实现)
一.原理 关联是指当一件事发生时,另外一件事也随着发生。关联分析也称关联挖掘,就是在各种数据之间挖掘规律或者模式。在数据挖掘中,最经典的案例就是尿不湿与啤酒的故事,这就是典型的关联关系。 关联规则的挖掘算法主要包括Apriori算法和FP-Growth算法。 • Apriori算法是一种基于候选生成和剪枝的经典算法。它首先生成所有的单个项集作为候选集,然后通过计算支持度来剪枝得到频繁项集,最后
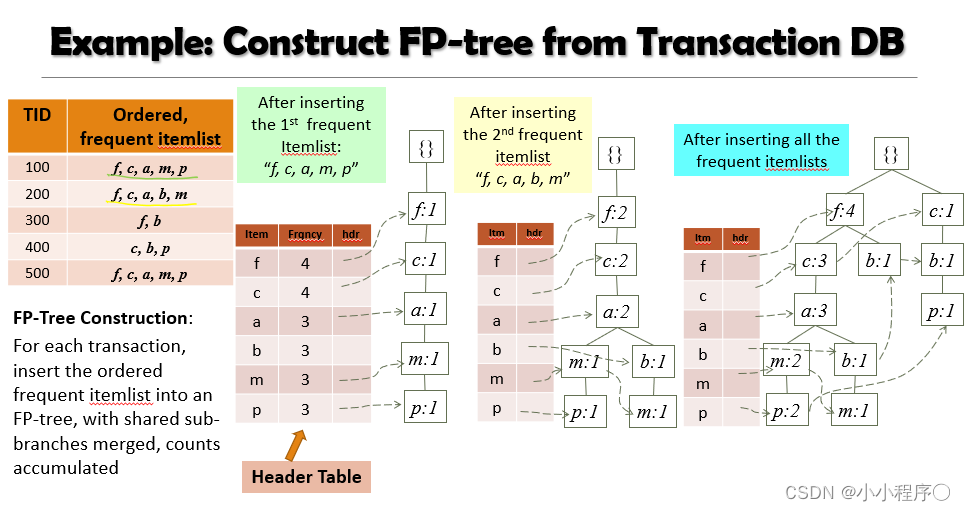
关联规则 FP-Growth算法
FP-Growth算法 FP-growth 算法思想 FP-growth算法是韩家炜老师在2000年提出的关联分析算法,它采取如下分治策略: 将提供频繁项集的数据库压缩到一棵频繁模式树 (FP-Tree)但仍保留项集关联信息。FP-growth算法是对Apriori方法的改进。生成一个频繁模式而不需要生成候选模式FP-growth算法以树的形式表示数据库,称为频繁模式树或FP-tree。此树结
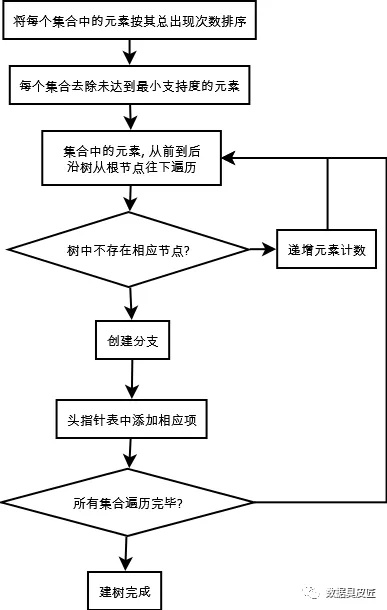
机器学习|FP-Growth
在上篇文章频繁项集挖掘实战和关联规则产生.中我们实现了Apriori的购物篮实战和由频繁项集产生关联规则, 本文沿《数据挖掘概念与技术》的主线继续学习FP-growth。因《数据挖掘概念与技术》中FP-growth内容过于琐碎且不易理解,我们的内容主要参考了《机器学习实战》第12章的内容。本文是对书中内容的通俗理解和代码实现,更详细的理论知识请参考书中内容, 本文涉及的完整jupyter代码和《机

机器学习9—关联分析之Apriori算法和FP-Growth算法
Apriori算法和FP-Growth算法 一、Apriori算法1.1Apriori算法原理1.2Apriori算法实例1.3Apriori算法实例代码演示(用python来写)1.4Apriori算法中apriori()函数使用 二、FP-Growth算法2.1FP-Growth算法概述2.2FP-Growth算法的特点2.3FP-Growth算法的原理2.4FP-Growth算法中函数

FP-Growth算法实现
频繁项集挖掘(二)FP-Growth算法 FP-Growth(Frequent Patterns)相比于Apriori是一种更加有效的频繁项集挖掘算法,FP-Growth算法只需要对数据库进行两次扫描,而Apriori算法对于每次产生的候选项集都会扫描一次数据集来判断是否频繁,因此当数据量特别巨大,且扫描数据库的成本比较高时,FP-Growth的速度要比Apriori快。 但是FP-Growt
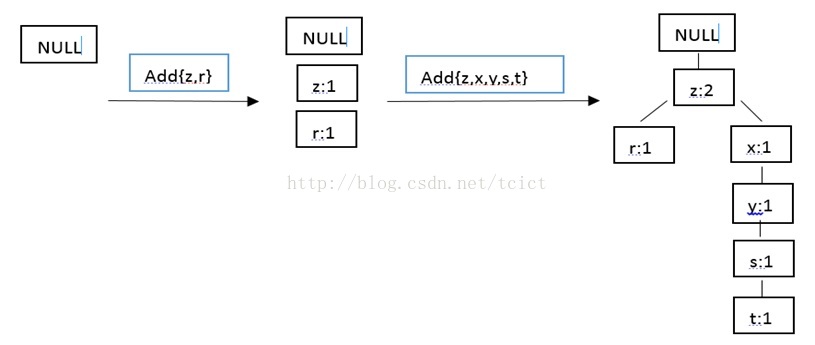
Python基础原理:FP-growth算法的构建
和Apriori算法相比,FP-growth算法只需要对数据库进行两次遍历,从而高效发现频繁项集。对于搜索引擎公司而言,他们需要通过查看互联网上的用词,来找出经常在一块出现的词。因此就需要能够高效的发现频繁项集的方法,FP-growth算法就可以完成此重任。 FP-growth算法是基于Apriori原理的,通过将数据集存储在FP(Frequent Pattern)树上发现频繁项集。
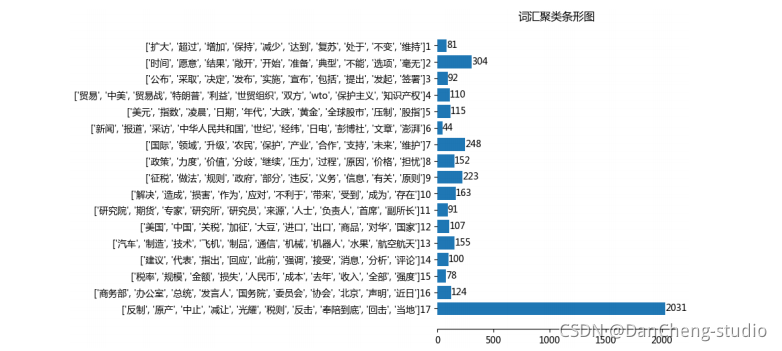
竞赛选题 题目:基于FP-Growth的新闻挖掘算法系统的设计与实现
文章目录 0 前言1 项目背景2 算法架构3 FP-Growth算法原理3.1 FP树3.2 算法过程3.3 算法实现3.3.1 构建FP树 3.4 从FP树中挖掘频繁项集 4 系统设计展示5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于FP-Growth的新闻挖掘算法系统的设计与实现 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料,