本文主要是介绍关联规则 FP-Growth算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FP-Growth算法
FP-growth 算法思想
- FP-growth算法是韩家炜老师在2000年提出的关联分析算法,它采取如下分治策略: 将提供频繁项集的数据库压缩到一棵频繁模式树 (FP-Tree)但仍保留项集关联信息。
- FP-growth算法是对Apriori方法的改进。生成一个频繁模式而不需要生成候选模式FP-growth算法以树的形式表示数据库,称为频繁模式树或FP-tree。此树结构将保持项集之间的关联。数据库使用一个频繁项进行分段。这个片段被称为“模式片段”。分析了这些碎片模式的项集。因此,该方法相对减少了频繁项集的搜索。
- FP-growth算法是基于Apriori原理的,通过将数据集存储在FP (FrequentPattern)树上发现频繁项集,但不能发现数据之间的关联规则FP-growth算法只需要对数据库进行两次扫描,而Apriori算法在求每个潜在的频繁项集时都需要扫描一次数据集,所以说Apriori算法是高效的。其中算法发现频繁项集的过程是 (1)构建FP树(2)从FP树中挖掘频繁项集
- FP-growth算法和Apriori算法最大的不同有两点第一,不产生候选集第二,只需要两次遍历数据库,大大提高了效率
FP-Tree ( Frequent Pattern Tree )
- FP树(FP-Tree)是由数据库的初始项集组成的树状结构。FP树的目的是挖掘最频繁的模式。
- FP树的每个节点表示项集的一个项根节点表示null,而较低的节点表示项集。在形成树的同时,保持节点与较低节点 (即项集与其他项集)的关联
算法步骤
FP-growth算法的流程为
- 首先构造FP树,然后利用它来挖掘频繁项集
- 在构造FP树时,需要对数据集扫描两遍
- 第一遍扫描用来统计频率,第二遍扫描至考虑频繁项集
算法例子
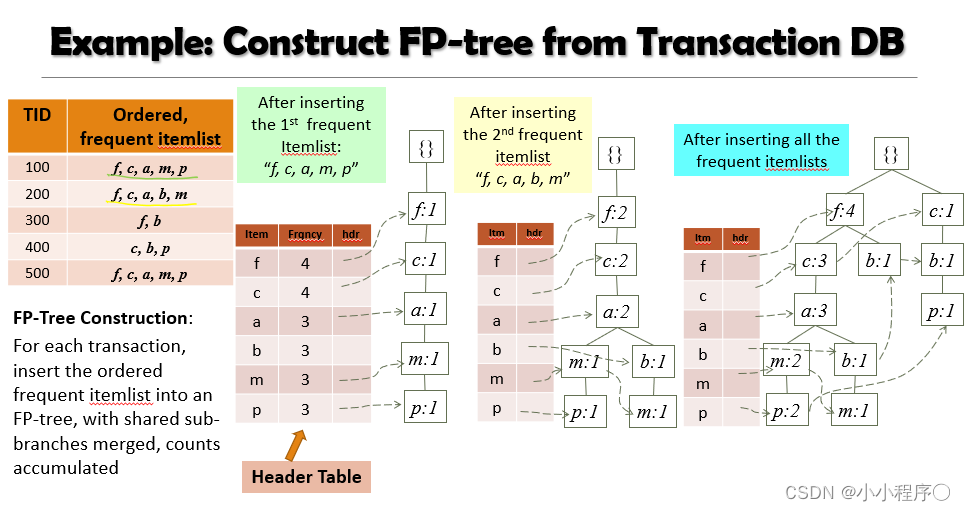
下期使用代码实现FP-Growth算法
这篇关于关联规则 FP-Growth算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








