fp专题

HexView 刷写文件脚本处理工具-命令行介绍(七)-数据填充(/FP /FR)
/FR 选项:填充区域 用途:用于创建并填充内存区域。数据填充:如果未提供 /FP 参数,HexView 将使用随机数据来填充区块或区域。如果提供了 /FP 参数,则会重复使用 /FP 参数指定的值。对现有数据的影响:填充操作不会影响现有数据,因此甚至可以用来填充段之间的数据。范围指定方法: 通过起始地址和长度,用逗号分隔(例如:/FR:0x1000,0x200)。通过起始地址和结束地址,用减号

理解机器学习实战 --- FP-Growth算法高效发现频繁项集
FP-growth算法介绍: 一种非常好的发现频繁项集的算法 基于Apriori算法构建,但是数据结构不同,使用叫做FP树的数据结构来存储集合。 FP-grouw算法原理: 基于数据集构造FP树 支持度:某一项类别出现的次数,可以理解为出现的频率。 非频繁项:某一项出现的次数小于一定次数,我们称之为非频繁项集。 步骤一: 1.遍历所有的数据集合,计算

二进制炸弹的fp是什么?
🏆本文收录于「Bug调优」专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收藏&&订阅!持续更新中,up!up!up!! 问题描述 我在解二进制炸弹第四阶段的递归时,对主函数中的片段的理解如下: 8bc4: e3530002 cmp r3, #28bc8:

电影数据集关联分析及FP-Growth实现
(1)数据预处理 我们先对数据集进行观察,其属性为’movieId’ ‘title’ ‘genres’,其中’movieId’为电影的序号,但并不完整,‘title’为电影名称及年份,‘genres’为电影的分类标签。因此电影的分类标签可以作为我们研究此数据集关联分析的文本数据。 我们可以看到电影的分类标签在同一个电影下不只有一个,且用’|’分开,因此我们对数据进行以下
weka实战004:fp-growth关联规则算法
apriori算法的计算量太大,如果数据集略大一些,会比较慢,非常容易内存溢出。 我们可以算一下复杂度:假设样本数有N个,样本属性为M个,每个样本属性平均有K个nominal值。 1. 计算一项频繁集的时间复杂度是O(N*M*K)。 2. 假设具有最小支持度的频繁项是q个,根据它们则依次生成一项频繁集,二项频繁集,....,r项频繁集合,它们的元素数量分别是:c(q, 1), c(q,
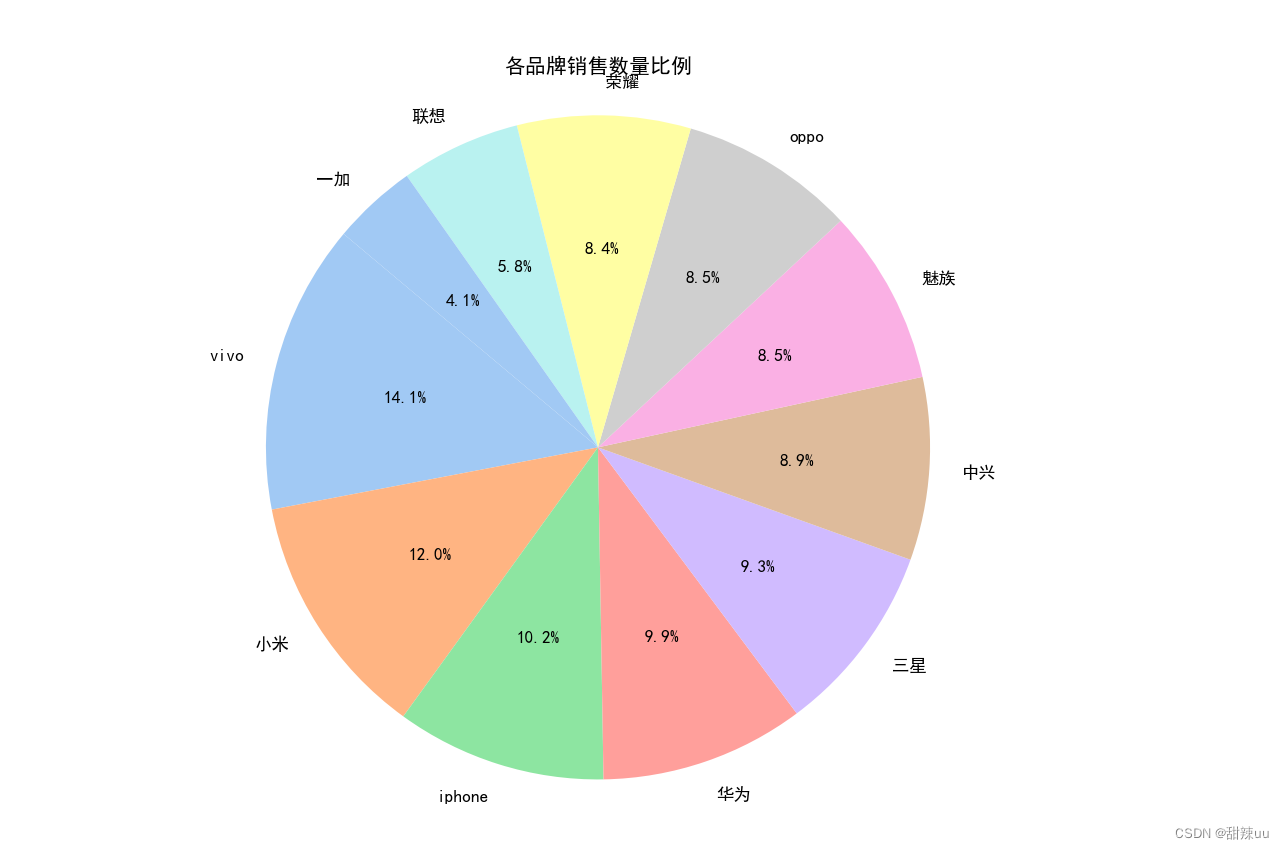
实战16:基于apriori关联挖掘FP-growth算法挖掘关联规则的手机销售分析-代码+数据
直接看视频演示: 基于apriori关联挖掘关联规则的手机销售分析与优化策略 直接看结果: 这是数据展示: 挖掘结果展示: 数据分析展示:
该不该做独立站?你适合做FP独立站吗?
在全球化的浪潮中,越来越多的跨境电商选择独立站来扩展市场。为了获取更大的利润,独立站这一赛道慢慢衍生出了售卖擦边产品的FP独立站。与其他独立站相比,FP独立站主要贩卖的是侵Q、黑五类的商品,收益大,风险也大,因此,有很多商家想入局,却总在起点徘徊。 接下来,我来给大家介绍一下FP独立站的几个特点: 最显著的特点一定是高利润了。FP独立站销售的产品往往是知名品牌的仿制品,由于不需要支付高昂的品牌
《机器学习实战》笔记之十二——使用FP-Growth算法来高效发现频繁项集
第十二章 使用FP-Growth算法来高效发现频繁项集 FP-growth算法,基于Apriori构建,但在完成相同任务时采用了不同的技术,其只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此其比Apriori算法快。FP算法需要将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对。 12.1 FP树:用于编
kernel-5.4 module fp->f_op->read() unable to handle
在编写kernel驱动时 fp->f_op->read() unable to handle pos = 0;kernel_read(fp, buf, len, &pos); // 改为kernel_read()--ok//fp->f_op->read(fp, buf, len, &fp->f_pos);

手把手教你解决FP独立站收款问题
独立站成为了许多跨境卖家的首选平台,尤其是对于那些销售FP产品的卖家来说,它提供了一个更为宽松的经营环境。然而,FP独立站虽然规避了平台审核的风险,却面临着另一个挑战——收款问题。 由于FP产品属于敏感领域,与普货产品的销售相比,收款难成为了核心问题,冻结封号屡见不鲜。不少主流支付通道对FP产品交易持保留态度,甚至拒绝服务,银行也会为了规避风险而对FP独立站的交易进行严格监控,甚至直接冻结
Java FP(Java8): Java中函数式编程的Map和Fold(Reduce)
在函数式编程中,Map和Fold是两个非常有用的操作,它们存在于每一个函数式编程语言中。既然Map和Fold操作如此强大和重要,但是Java语言缺乏Map和Fold机制,那么该如何解释我们使用Java完成日常编码工作呢?实际上你已经在Java中利用手动编写循环的方式实现了Map和Fold操作(译者注:许多动态语言如python都提供了内置的实现)。 免责声明:本篇文章仅仅只是一篇入门简介,并
【目标检测】计算YOLOv5/7/8/9的TP, FP, FN, Recall和Precision
1. 设定IoU和Conf阈值 2. 保存推理结果的txt文件 3. 计算TP, FP, FN import osclasses = {0: "class 1",1: "class 2"}def iou(box1, box2):box1_x1 = box1[0] - box1[2] / 2box1_y1 = box1[1] - box1[3] / 2box1_x2 = box1[0] + b
浅谈Slick(3)- Slick201:从fp角度了解Slick
我在上期讨论里已经成功的创建了一个简单的Slick项目,然后又尝试使用了一些最基本的功能。Slick是一个FRM(Functional Relational Mapper),是为fp编程提供的scala SQL Query集成环境,可以让编程人员在scala编程语言里用函数式编程模式来实现对数据库操作的编程。在这篇讨论里我想以函数式思考模式来加深了解Slick。我对fp编程模式印象最深的就是类

【频繁模式挖掘】FP-Tree算法(附Python实现)
一、实验内容简介 该实验主要使用频繁模式和关联规则进行数据挖掘,在已经使用过Apriori算法挖掘频繁模式后,这次使用FP-tree算法来编写和设计程序,依然使用不同规模的数据集来检验效果,最后分析和探讨实验结果,看其是否达到了理想的效果。本实验依然使用Python语言编写。 二、算法说明 首先简单介绍频繁模式和关联规则: 频繁模式一般是指频繁地出现在数据集中的模式。 关联规则是形如X

【yolov5小技巧(1)】---可视化并统计目标检测中的TP、FP、FN
文章目录 🚀🚀🚀前言一、1️⃣相关名词解释二、2️⃣论文中案例三、3️⃣新建相关文件夹四、4️⃣detect.py推理五、5️⃣开始可视化六、6️⃣可视化结果分析 👀🎉📜系列文章目录 嘻嘻 暂时还没有~~~~ 🚀🚀🚀前言 在目标检测过程中,看F1置信度分数,依旧map@0.5或者AP、recall这些评估指标虽然可以很简单粗暴的看出模型训练的
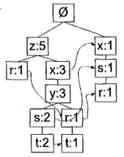
FP-growth算法来高效发现频繁集
FP-growth算法是一种高效发现频繁集的算法,比Apriori算法高效,但是不能用于发现关联规则。FP-growth算法只需要对数据即信两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否是频繁,所以FP-growth更快。FP-growth算法主要分为两个过程: 构建FP树;从FP树中挖掘频繁项集。 1.FP树介绍 FP代

x86_64架构栈帧以及帧指针FP
文章目录 一、x86_64架构寄存器简介二、x86_64架构帧指针FP三、示例四、保存帧指针参考资料 一、x86_64架构寄存器简介 在x86架构中,有8个通用寄存器可用:eax、ebx、ecx、edx、ebp、esp、esi和edi。在x86_64(x64)扩展中,这些寄存器被扩展为64位,以’r’前缀代替’e’,并添加了另外8个寄存器:r8、r9、r10、r11、r12、r1
机器学习中TP,TN,FP,FN,Acc,Pre,Sen, Rec的含义
1、 TP,TN,FP,FN的理解 定义 第一个字母T/F代表预测的结果是否和实际情况相符:即如果真实情况为正样本(P),预测为正样本(P),则为T;如果真实情况为负样本(N),预测为负样本(N),则为T;如果真实情况为P,预测为N,则为F;如果真实情况为N预测为P,则为F。 第二个字母P/N代表预测结果的正负:如果预测为正样本,则为P;如果预测为负样本,则为N。 TP:true posi

ARM FP寄存器及frame pointer介绍
理论上来说,ARM的15个通用寄存器是通用的,但实际上并非如此,特别是在过程调用的过程中。 PCS(Procedure Call Standard for Arm architecture)就定义了过程调用中,寄存器的特殊用途。 Role in the procedure call standard r15 PC The Program Counter. r14 LR The Lin

前端vite+vue3——可视化页面性能耗时指标(fmp、fp)
文章目录 ⭐前言💖vue3系列文章 ⭐可视化fmp、fp指标💖 MutationObserver 计算 dom的变化💖 使用条形图展示 fmp、fp时间 ⭐项目代码⭐结束 ⭐前言 大家好,我是yma16,本文分享关于 前端vite+vue3——可视化页面性能耗时(fmp、fp)。 fmp的定义 FMP(First Meaningful Paint)是一种衡
JS 中的 FP 和 OOP
JavaScript是一种广泛应用于Web开发的脚本语言,它支持多种编程范式,包括 命令式编程 函数式编程(FP) 面向对象编程(OOP) 函数式编程(FP)是一种编程范式,它将计算视为函数的求值过程,强调使用纯函数和避免共享状态和可变数据。在JavaScript中,函数是一等公民,可以作为参数传递给其他函数,也可以作为返回值返回。FP的一些核心概念包括不可变性、高阶函数、纯函数和函数组合。通过
Apriori 与 FP-growth 算法
关联规则挖掘:Apriori 与 FP-growth 算法 关联规则挖掘概述Apriori 算法基本原理应用实例 FP-growth 算法基本原理应用实例 其他机器学习算法:机器学习实战工具安装和使用 关联规则挖掘是数据挖掘领域中的一个重要任务,旨在发现数据集中不同项之间的关联关系。Apriori 算法和 FP-growth 算法是两种常用的关联规则挖掘算法,它们在挖掘频繁项集和

浅谈语义分割、图像分类与目标检测中的TP、TN、FP、FN
语义分割 TP:正确地预测出了正类,即原本是正类,识别的也是正类 TN:正确地预测出了负类,即原本是负类,识别的也是负类 FP:错误地预测为了正类,即原本是负类,识别的是正类 FN:错误地预测为了负类,即原本是正类,识别成了负类 代码可见:一整套计算correct, labeled, inter, union, tp, fp, tn, fn的代码 目标检测 1

机器学习分类评估四个术语TP,FP,FN,TN
分类评估方法主要功能是用来评估分类算法的好坏,而评估一个分类器算法的好坏又包括许多项指标。了解各种评估方法,在实际应用中选择正确的评估方法是十分重要的。 这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negative)分别是: 1.True positives(TP):被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取、分析与分类研究。主要涉及到关联规则与序列模式挖掘两块。关联规则挖掘使用基于有趣性度量标准的FP-Growth算法,序列模式挖掘使用基于有趣性度量标准的GSP算法。若想实现以上优化算法,首先必须了解其基本算法,并编程实现。关键点还是在于理解算法思想,只有懂得
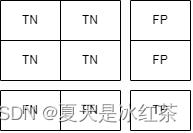
多分类中混淆矩阵的TP,TN,FN,FP计算
关于混淆矩阵,各位可以在这里了解:混淆矩阵细致理解_夏天是冰红茶的博客-CSDN博客 上一篇中我们了解了混淆矩阵,并且进行了类定义,那么在这一节中我们将要对其进行扩展,在多分类中,如何去计算TP,TN,FN,FP。 原理推导 这里以三分类为例,这里来看看TP,TN,FN,FP是怎么分布的。 类别1的标签: 类别2的标签: 类别3的标签: 这样我们就能知道了混淆矩阵的对角线