flinksql专题

Kafka中的数据本身就是倾斜的,使用FlinkSQL该如何处理
又是经历了一段不太平的变动,最近算是稳定了点,工作内容又从后端开发转换成了sql boy,又要开始搞大数据这一套了。不同的是之前写实时任务的时候都是用的java代码,新环境却更加偏向与使用flink sql 解决,所以记录下使用flink sql 的一些感悟和遇到的问题吧。 查看反压: 如果flink任务是这么一坨或者几坨task组合在一起,有些时候是如法看

flinksql BUG : flink hologres-cdc source FINISHED
org.apache.flink.runtime.JobException: The failure is not recoverable or the failure does not allow to restart.at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler
袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈、交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代。在进行产品研发的过程中,技术小哥哥们能文能武,不断提升产品性能和体验的同时,也把这些提升和优化过程记录下来,现录入“袋鼠云研发手记”专栏中,以和业内童鞋们分享交流。 下为“袋鼠云研发

FlinkSQL中的回退更新-Retraction
公众号《大数据技术与架构》,大数据领域高级进阶 已关注 5 人赞同了该文章 前言 如果你在使用FlinkSQL时出现如下的报错: Table is not an append-only table. Use the toRetractStream() in order to handle add and retract messages. 那么你就有必要了解一下Flink中的回退更新。
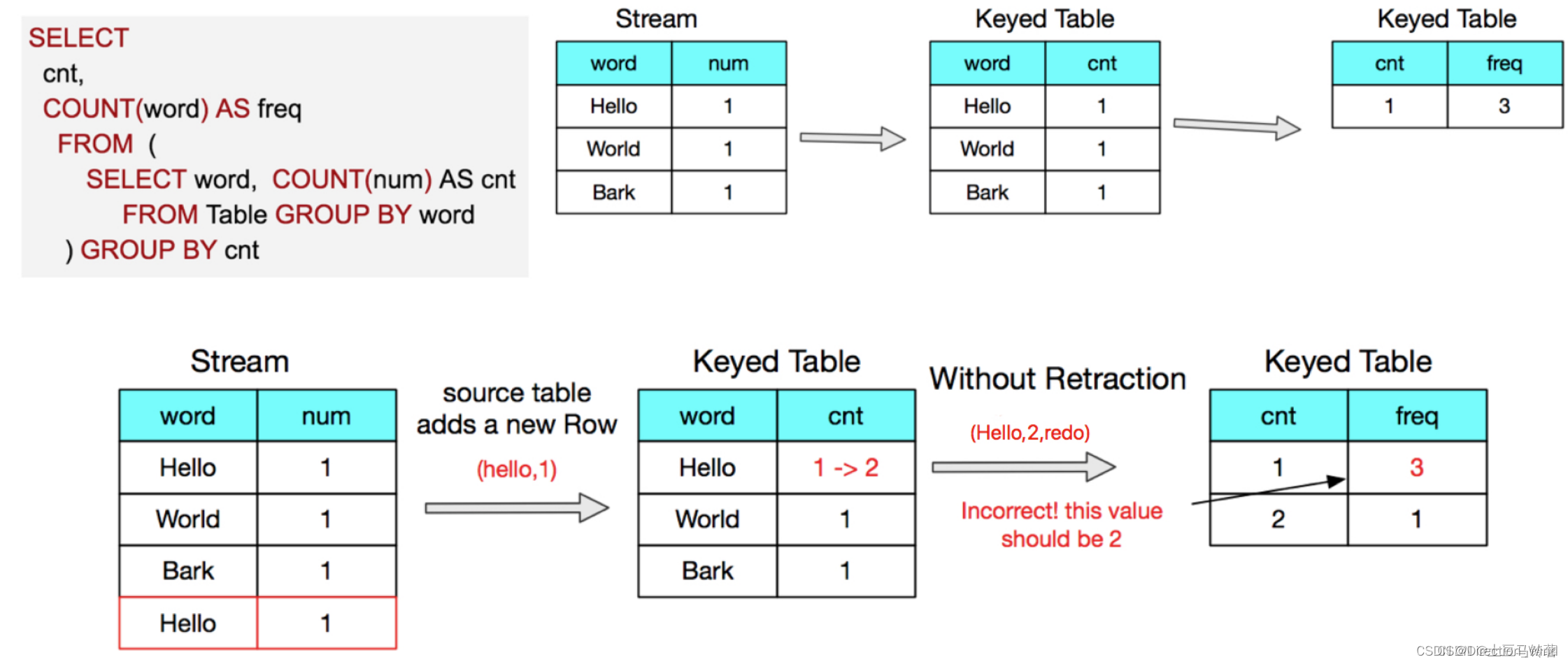
flinksql 回撤流中主键发生变更的影响(group by中的值发生改变)
flinksql 回撤流中,主键发生变更的影响 1 什么是回撤流2 主键变更场景3 实践中发现的比较好的的实时数仓架构 1 什么是回撤流 这篇文章主要谈论一个场景,简单来说: 首先我们来简单的说一下什么是回撤流,以及回撤流的底层原理,举个例子: 这个说的不是很清晰 ,其实倒数第二个图当作输出 比较好看出来,再bank 这一条来之后,数据结果是 hello 1 world 1

flinksql的 / 的结果只会保留整数部分,flinksql 不支持 div运算符。hive、 mysql : / 结果是小数, div 结果只会保留整数部分
flinksql的 / 的结果只会保留整数部分,flinksql 不支持 div运算符。 hive、 mysql : / 结果是小数, div 结果只会保留整数部分 mysql> select 3/2 ;+--------+| 3/2 |+--------+| 1.5000 |+--------+1 row in set (0.00 sec)mysql> mysql>
FlinkSQL State的生命周期
FlinkSQL未显示配置state生命周期 FlinkSQL默认没有配置state 的过期时间。也就是说默认情况是FlinkSQL从不清除状态。如果状态后端保存在rocksdb中,直到本地磁盘被打满,服务挂掉,报错如下: java.io.IOException: [bf3ba881614e80c741fb962c87b7d6fd] Failed to fetch BLOB 122648170
FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个、频率最高的放在最后这种方式来微调 join 查询的性能。需要确保表的顺序不会产生笛卡尔积,因为不支持这样的操作并且会导致查询失败。
flinksql在实时数仓hologres的计算问题排查
要排查 Flink 实时计算从 Hologres 源表到目标表的错误,可以采取以下步骤: 检查 Flink 程序逻辑: 确保 Flink 程序中源表到目标表的数据转换逻辑正确。检查是否正确地连接了源表和目标表,并且字段映射正确。 检查 Hologres 连接: 确保 Flink 程序正确地连接到 Hologres 数据库,并且连接信息没有问题。检查连接是否稳定,排除网络或连接池问题。 验证

flink重温笔记(十九): flinkSQL 顶层 API ——FlinkSQL 窗口(解决动态累积数据业务需求)
Flink学习笔记 前言:今天是学习 flink 的第 19 天啦!学习了 flinkSQL 中窗口的应用,包括滚动窗口,滑动窗口,会话窗口,累计窗口,学会了如何计算累计值(类似于中视频计划中的累计播放量业务需求),多维数据分析等大数据热点问题,总结了很多自己的理解和想法,希望和大家多多交流,希望对大家有帮助! Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有
flink重温笔记(十五): flinkSQL 顶层 API ——实时数据流转化为SQL表的操作
Flink学习笔记 前言:今天是学习 flink 的第 15 天啦!学习了 flinkSQL 基础入门,主要是解决大数据领域数据处理采用表的方式,而不是写复杂代码逻辑,学会了如何初始化环境,鹅湖将流数据转化为表数据,以及如何查询表数据,结合自己实验猜想和代码实践,总结了很多自己的理解和想法,希望和大家多多交流! Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有
Flinksql实时计算——group by key和 group by key 带窗口聚合有什么不同
在 Flink SQL 中,GROUP BY key 和 GROUP BY key 带窗口聚合的主要区别在于它们如何处理数据的时间维度和计算结果的粒度。 简单的 GROUP BY key: 当使用简单的 GROUP BY 对 key 进行聚合时,你会得到一个按指定 key 分组的静态聚合结果。这个聚合是基于 key 的所有历史数据进行的,不考虑时间窗口或数据排序。 例如,假设你有一个包含用

flinksql流批一体计算平台为什么选型是Streamx
flink实时计算平台为什么选型是Streamx 一、概述 1.1 背景 Apache Flink被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力终于诞生了今天的框架 —— StreamX, 项目的初衷是 —— 让 Flink 开发更简单, 使用
FlinkSql一个简单的测试程序
FlinkSql一个简单的测试程序 以下是一个简单的 Flink SQL 示例,展示了如何使用 Flink Table API 和 Flink SQL 进行基本的数据流处理。 定义数据实体 CC : - CC 类表示数据流中的元素,包含两个字段: character (字符)和 count (计数)。 - 提供了无参构造函数和带参构造函数,用于创建 CC 对象。 // 1.
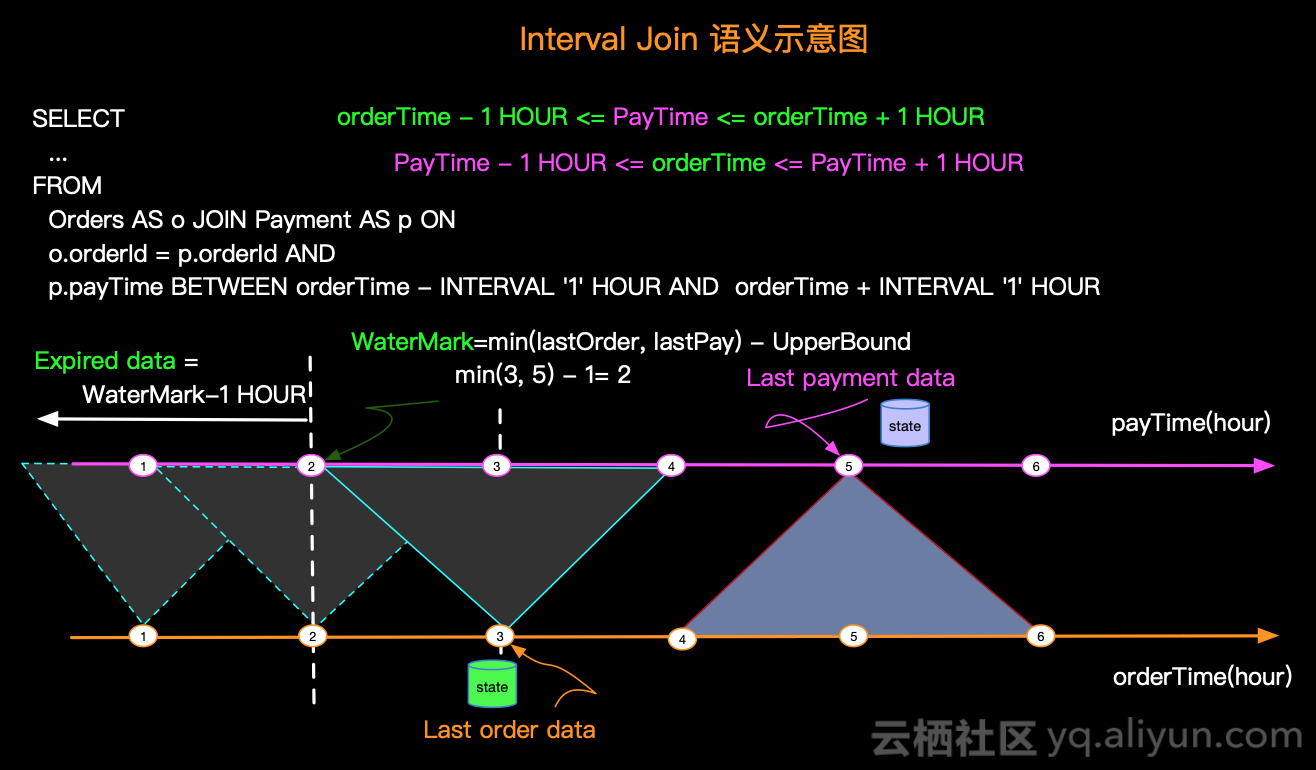
详述FlinkSql Join操作
FlinkSql 的 Join Flink 官网将其分为了 Joins 和 Window Joins两个大类,其中里面又分了很多 Join 方式 参考文档: Joins | Apache Flink Window JOIN | Apache Flink Joins 官网介绍共有6种方式: Regular Join:流与流的 Join,包括 Inner Join、Outer
FlinkSql通用调优策略
历史文章迁移,稍后整理 使用DataGenerator 提前进行压测,了解数据的处理瓶颈、性能测试和消费能力 开启minibatch:"table.exec.mini-batch.enabled", "true" 开启Local+Global 两阶段聚合:"table.exec.mini-batch.enabled", "true" 解决数据倾斜问题: 流式倾斜,开启miniba
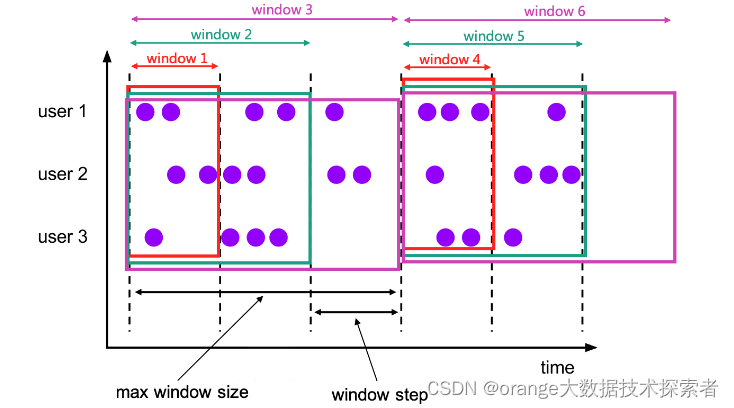
FlinkSql 窗口函数
Windowing TVF 以前用的是Grouped Window Functions(分组窗口函数),但是分组窗口函数只支持窗口聚合 现在FlinkSql统一都是用的是Windowing TVFs(窗口表值函数),Windowing TVFs更符合 SQL 标准且更加强大,支持window join、Window aggregations、Window Top-N、Window Dedu
【Flink】FlinkSQL实现数据从Kafka到MySQL
简介 未来Flink通用化,代码可能就会转换为sql进行执行,大数据开发工程师研发Flink会基于各个公司的大数据平台或者通用的大数据平台,去提交FlinkSQL实现任务,学习Flinksql势在必行。 本博客在sql-client中模拟大数据平台的sql编辑器执行FlinkSQL,使用Flink实现数据从Kafka传输到MySQL具体操作,这个在生产开发中比较常用
【Flink】FlinkSQL的DataGen连接器(测试利器)
简介 我们在实际开发过程中可以使用FlinkSQL的DataGen连接器实现FlinkSQL的批或者流模拟数据生成,DataGen 连接器允许按数据生成规则进行读取,但注意:DataGen连接器不支持复杂类型: Array,Map,Row。 请用计算列构造这些类型 创建有界DataGen表 CREATE TABLE test ( a INT, b STRING, creat

【FlinkSQL】一文读懂流join方式
目录 一、常规join 二、时间窗口join 三、时态表join 基于事件时间的时态 Join 基于处理时间的时态 Join 四、时态表函数join 对于离线计算、批处理,join操作比较好理解,可以参考文章 hive 各种 join (left outer join、join、full outer join)。但是数据流的join和离线join是有差异的,流是无限的
【Flink】FlinkSQL读取Mysql表中时间字段相差13个小时
问题:Flink版本1.13,在我们使用FlinkSQL读取Mysql中数据的时候,发现读取出来的时间字段中的数据和Mysql表中的数据相差13个小时,Mysql建表语句及插入的数据如下; CREATE TABLE `mysql_example` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID', `name` var
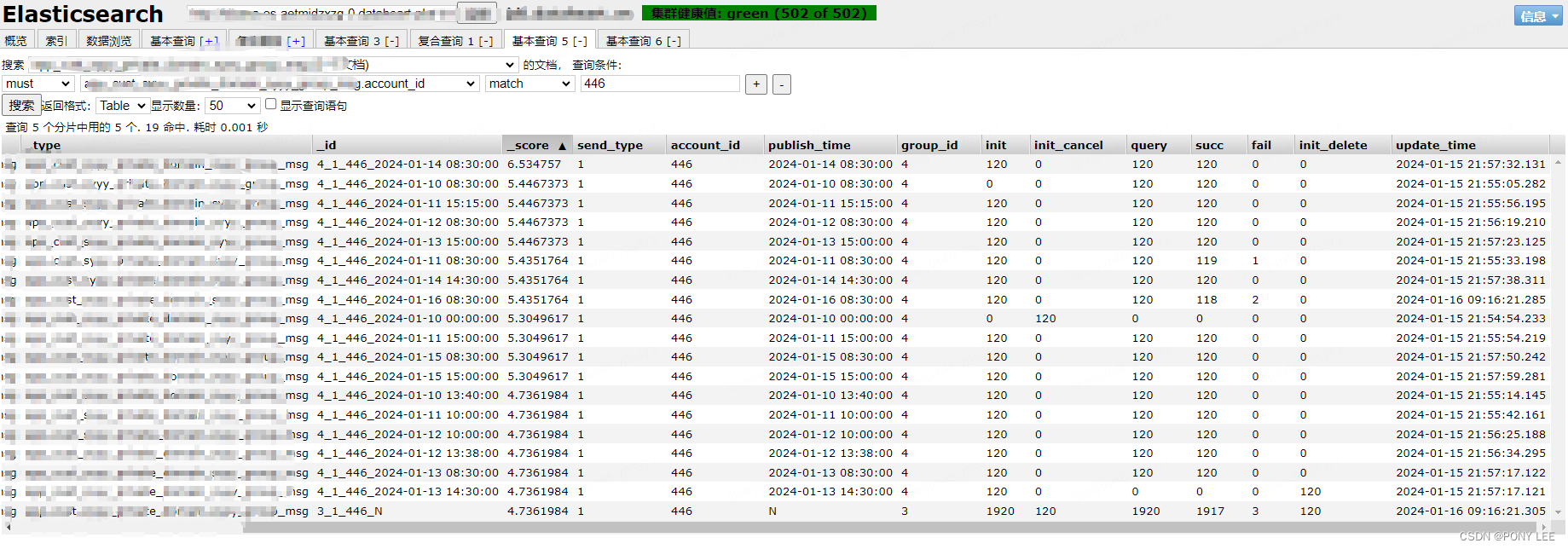
FlinkSQL【分组聚合-多维分析-性能调优】应用实例分析
FlinkSQL处理如下实时数据需求: 实时聚合不同 类型/账号/发布时间 的各个指标数据,比如:初始化/初始化后删除/初始化后取消/推送/成功/失败 的指标数据。要求实时产出指标数据,数据源是mysql cdc binlog数据。 代码实例 --SET table.exec.state.ttl=86400s; --24 hour,默认: 0 msSET table.exec.state.t
FlinkSQL窗口实例分析
Windowing TVFs Windowing table-valued functions (Windowing TVFs),即窗口表值函数 注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,window_end TUMBLE函数采用三个必需参数,一个可选参数: TUMBLE(TA
FlinkSQL时间更新问题
最近项目中使用FlinkSQL来做数据统计,遇到一些问题,小结一下。 第一个问题:聚合好的正确数据写入数据库后不正确。 场景:因为是做数据聚合,会upsert(更新或写入)数据,为了保证效率,批量每10s中在数据库中写一次数据,异步写入,每次最多更新500条。 结果:日志打印出最终的统计结果正确,但写入数据库的值不正确。 原因:异步写入,无法保证写入顺序,如果一批数据中有 对同一条记录进行
五分钟,Docker安装flink,并使用flinksql消费kafka数据
1、拉取flink镜像,创建网络 docker pull flinkdocker network create flink-network 2、创建 jobmanager # 创建 JobManager docker run \-itd \--name=jobmanager \--publish 8081:8081 \--network flink-network \--env FLIN
【Flink-Sql-Kafka-To-ClickHouse】使用 FlinkSql 将 Kafka 数据写入 ClickHouse
【Flink-Sql-Kafka-To-ClickHouse】使用 FlinkSql 将 Kafka 数据写入 ClickHouse 1)需求分析2)功能实现3)准备工作3.1.Kafka3.2.ClickHouse 4)Flink-Sql5)验证 1)需求分析 1、数据源为 Kafka,定义 Kafka-Topic 为动态临时视图表。 2、写入到 ClickHouse,自定义