本文主要是介绍Kafka中的数据本身就是倾斜的,使用FlinkSQL该如何处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
又是经历了一段不太平的变动,最近算是稳定了点,工作内容又从后端开发转换成了sql boy,又要开始搞大数据这一套了。不同的是之前写实时任务的时候都是用的java代码,新环境却更加偏向与使用flink sql 解决,所以记录下使用flink sql 的一些感悟和遇到的问题吧。
查看反压:
如果flink任务是这么一坨或者几坨task组合在一起,有些时候是如法看出反压的。无法看出反压的意思是,资源明知已经配置的很大了,反压显示也是正常的绿色,但是数据一直堆积着,这个时候一定要disable chain:pipeline.operator-chaining=false,才能正确的看到是否有反压,以及哪个节点在反压

Kafka中的数据一读出来就反压了,该如何解决:
本人遇到了这么一个flink sql任务,kafak中的数据读取出来之后,没有groupby之类的操作,就是与HBase表进行join,然后进行where条件过滤,然后任务就反压了。kafka分区数量为48,程序并行度为200,如下所示:
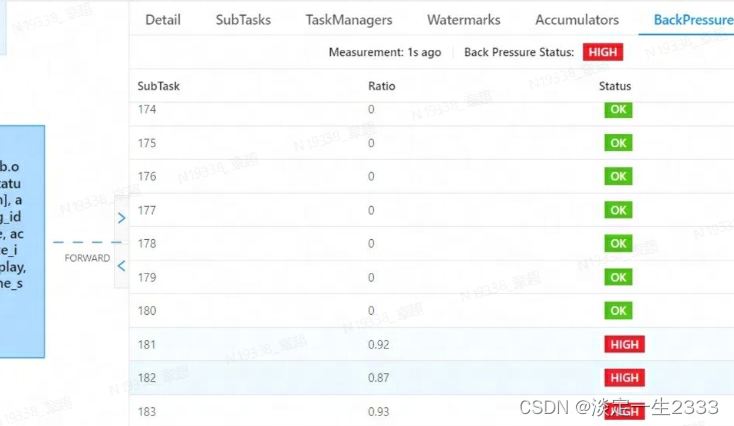
因为kafka分区数为48,所以最多也就49个task会读取数据,也就是200的并行度其实很多都没起作用,这个时候就要让flink程序在读取kafka数据之后shuffle一下,将数据均匀的分散到各个task上。查了下 有轮询分区(Round-Robin(rebalance))和 重缩放分区(rescale)两种方式。
Round-Robin(rebalance):
就是将数据hash到下游的各个task中,数据打算的最散。最终程序也是通过设置rebalance.parallelism解决的数据倾斜的问题。
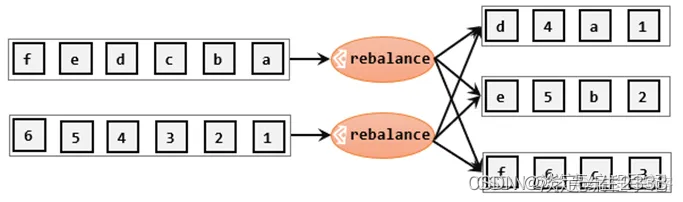
Rescale:
也是一种hash方式,但是是一种较为轻量级的负载均衡。它会基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。
举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。

后续慢慢深入了解FlinkSQl技术和业务吧,希望能产出更多高质量内容文章呀!
参考:
Flink的八种分区策略源码解读 | Jmx's Blog
这篇关于Kafka中的数据本身就是倾斜的,使用FlinkSQL该如何处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



