倾斜专题

Redis 中的热点键和数据倾斜示例详解
《Redis中的热点键和数据倾斜示例详解》热点键是指在Redis中被频繁访问的特定键,这些键由于其高访问频率,可能导致Redis服务器的性能问题,尤其是在高并发场景下,本文给大家介绍Redis中的热... 目录Redis 中的热点键和数据倾斜热点键(Hot Key)定义特点应对策略示例数据倾斜(Data S

数据倾斜?Spark 3.0 AQE专治各种不服
Spark3.0已经发布半年之久,这次大版本的升级主要是集中在性能优化和文档丰富上,其中46%的优化都集中在Spark SQL上,SQL优化里最引人注意的非Adaptive Query Execution莫属了。 Adaptive Query Execution(AQE)是英特尔大数据技术团队和百度大数据基础架构部工程师在Spark 社区版本的基础上,改进并实现的自适应执行引擎。近些年来,S

Spark学习之路 (九)SparkCore的调优之数据倾斜调优
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 某个task执行特别慢的情况 某个task莫名其妙内存溢出的情况 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数据 解决方案二:过滤少数导致倾斜的key 解决方案三:提

数据倾斜是多么痛?spark作业调优秘籍
原文:https://mp.weixin.qq.com/s?__biz=MzI5OTAwMTM1MQ==&mid=2456325754&idx=1&sn=e8f284f79f24cdf4046d7419c61b58ff&chksm=fb011d12cc7694049c8971d41fe1391063b6fd33e63685fc072787d55576f5117782c71fba4b&mpshare

Spark性能调优之道——解决Spark数据倾斜(Data Skew)的N种姿势
原文:http://www.infoq.com/cn/articles/the-road-of-spark-performance-tuning?utm_campaign=rightbar_v2&utm_source=infoq&utm_medium=articles_link&utm_content=link_text 为何要处理数据倾斜(Data Skew) 什么是数据倾斜 对Spark/

three.js实现 加载3dtiles ,瓦片 ,倾斜摄影,功能
预览:https://z2586300277.github.io/three-cesium-examples/#/codeMirror?navigation=ThreeJS&classify=expand&id=loadTiles 部署站点预览:http://threehub.cn/ 开源地址:https://z2586300277.github.io/three-cesium-example

Kafka中的数据本身就是倾斜的,使用FlinkSQL该如何处理
又是经历了一段不太平的变动,最近算是稳定了点,工作内容又从后端开发转换成了sql boy,又要开始搞大数据这一套了。不同的是之前写实时任务的时候都是用的java代码,新环境却更加偏向与使用flink sql 解决,所以记录下使用flink sql 的一些感悟和遇到的问题吧。 查看反压: 如果flink任务是这么一坨或者几坨task组合在一起,有些时候是如法看

Python微磁学磁倾斜和西塔规则算法
📜有限差分-用例 📜离散化偏微分方程求解器和模型定型 | 📜三维热传递偏微分方程解 | 📜特定资产期权价值偏微分方程计算 | 📜三维波偏微分方程空间导数计算 | 📜应力-速度公式一阶声波方程模拟二维地震波 | 📜微磁学计算磁化波动求解器、色散关系和能垒的弦法 | 📜磁倾斜导数数据平滑 📜指数衰减:🖊常微分方程数值求解器 | 🖊绘制衰减图 | 🖊绘制(正向欧拉、反向欧拉和

谷歌倾斜摄影覆盖面积究竟有多大?这里有了准确数字
自谷歌地球诞生以来,凭借着数据种类多、覆盖面积广、数据精度高、更新及时、交互体验良好的优势,很多人喜欢在上面恣意浏览,足不出户,俯瞰地球美好河山,探索自然地理奇妙景观。谷歌地球中倾斜摄影数据是继谷歌卫星影像数据外最重要的数据,是目前市面上包含倾斜摄影数据的产品中覆盖面积最广且数据精度很高的产品,数据全域精度优于10cm,局部区域精度高达5cm。 谷歌地球倾斜摄影有如下优势: 逼真的三维效果:谷歌地

Cesium前端实现倾斜摄影数据单体化的效果
倾斜摄影数据要实现单体化,有好几种方式: 其一:利用收费的超图IServer制作单体化,具体制作流程在他们官方网站有制作流程文档(但IServer的收费不菲,性价比不高) 可参考: http://support.supermap.com.cn:8090/iserver/iClient/for3D/webgl/zh/examples/TopicDoc/LoadObliqueModel_Oper

电位器、金属触摸传感器、红外避障传感器、烟雾传感器、倾斜开关传感器 | 配合Arduino使用案例
电位器 电位器就是一个旋转按钮,可以读取到开关旋转的数值(范围:0-1023) /****** Arduino 接线 ***** VCC - 5v* GND - GND* OUT - A0***********************/int mainPin = A0; // 接继电器的 IN 端口void setup() { Serial.begin(9600); // 串口通信用于输
三维模型轻量化工具:手工模型、BIM、倾斜摄影等皆可用!
老子云是全球领先的数字孪生引擎技术及服务提供商,它专注于让一切3D模型在全网多端轻量化处理与展示,为行业数字化转型升级与数字孪生应用提供成套的3D可视化技术、产品与服务。 老子云是全球领先的数字孪生引擎技术及服务提供商,它专注于让一切3D模型在全网多端轻量化处理与展示,为行业数字化转型升级与数字孪生应用提供成套的3D可视化技术、产品与服务。 老子云轻量化作为全球首款3D模型全自动轻量化处理技术
opencv--3d数据拟合平面并对倾斜平面矫正
对于深度数据而言,mat记录的是深度值,当对深度值进行各种处理,例如获取直线、圆、椭圆等其他形状时,如果平面没有完全水平,你使用opencv处理精度是有损失的,因此这里使用opencv 先对平面进行矫正,矫正原理是在有效平面内随机采集3000点的深度数据,使用深度数据进行拟合平面,计算平面的倾斜较大,然后使用角度对原始数据进行矫正,代码如下: // 将深度图转换为点云std::vector<c

提高倾斜摄影三维模型OSGB格式轻量化
提高倾斜摄影三维模型OSGB格式轻量化 倾斜摄影三维模型以其高精度和真实感受在城市规划、建筑设计和虚拟漫游等领域发挥着重要作用。然而,由于其庞大的数据量和复杂的几何结构,给数据存储、传输和可视化带来了挑战。为了提高倾斜摄影三维模型的性能和运行效率,倾斜摄影三维模型的OSGB格式轻量化成为关键的技术需求。本文将介绍几种提高倾斜摄影三维模型OSGB格式轻量化的创新技术与应用。 首先,基于压
hive中的join操作及其数据倾斜
hive中的join操作及其数据倾斜 join操作是一个大数据领域一个常见的话题。归根结底是由于在数据量超大的情况下,join操作会使内存占用飙升。运算的复杂度也随之上升。在进行join操作时,也会更容易发生数据倾斜。这些都是需要考虑的问题。 过去了解到很多关于join操作的知识点,特此总结一下。 join操作可以分为三类:小表join小表、大表join小表、大表join大表 其中小表jo
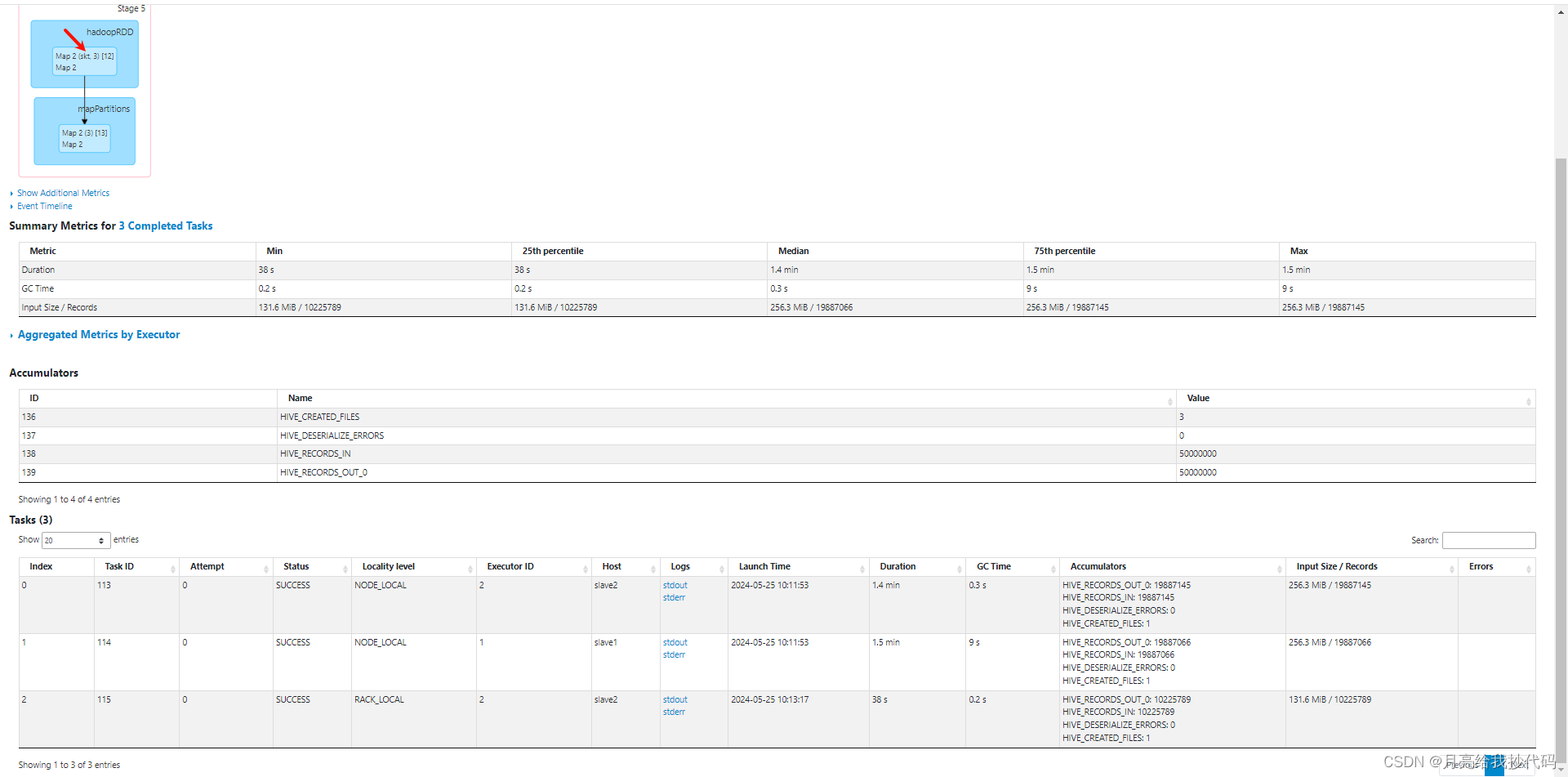
手把手教你解决 Hive 的数据倾斜
文章目录 数据倾斜是什么?产生数据倾斜的场景1.空值引发的数据倾斜2.不可拆分的大文件产生的数据倾斜3.数值膨胀引发的数据倾斜4.不同数据类型引发的数据倾斜5.Count(distinct) 引发的数据倾斜6.表 Join 操作时引发数据倾斜7.group by 引发的数据倾斜 解决数据倾斜数据准备模拟数据倾斜场景1.Group By 引发的数据倾斜2.Count(distinct) 引发的

倾斜摄影自动化建模成果的数据组织和单体化
来源:超图软件 2015-04-23 13:43:37 倾斜摄影三维建模及应用是近年来测绘 领域关注的热点,产业链上下游的企业为此都在积极探索,以推动该项技术的健康发展和落地应用。然而,什么样的技术才是真正符合用户实际应用需求的?在这 里,我们要和大家讲解倾斜摄影应用的两个重要话题——倾斜摄影自动化建模成果(后文简称“倾斜模型”)的数据组织和单体化。 数据组织:要LOD 更要便捷和安全

什么是数据倾斜,应该如何解决这个问题
数据倾斜(Data Skew)是指在分布式计算系统中,数据被不均匀地分布到各个节点上,导致某些节点拥有的数据量远大于其他节点。这种情况可能会引起资源分配不均,从而影响计算效率和性能。数据倾斜在很多场景下都可能出现,比如在进行数据的分组操作(如MapReduce中的reduce阶段)时,如果某些键对应的数据量特别大,就可能导致数据倾斜。 解决数据倾斜问题通常可以采用以下几种方法: 1. **重新
Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 (详细)
摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。 为何要处理数据倾斜(Data Skew) 什么是数据倾斜 对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。 何谓数据倾斜?数据倾斜指的

数据倾斜的两个解决方案
解决方案六:采样倾斜key并分拆join操作 方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。 方案实现

简单实用的倾斜摄影实景三维模型Web端展示管理方法,还不赶紧试试吗?
四维轻云是一款地理空间数据在线管理平台,具有地理空间数据在线管理、浏览及分享等功能。在四维轻云平台中,用户可以不受时间地点的限制,随时随地上传倾斜摄影实景三维模型、激光点云、正射影像、数字高程模型、航拍原片、人工模型和矢量数据等地理空间数据。 现在,就为大家介绍简单实用的倾斜摄影实景三维模型Web端展示管理方法,快来试试吧! 1、注册登录 首先,在四维轻云官网中完成注册并登录。

漫谈千亿级数据优化实践:数据倾斜(纯干货)
0x00 前言 引用 数据倾斜是大数据领域绕不开的拦路虎,当你所需处理的数据量到达了上亿甚至是千亿条的时候,数据倾斜将是横在你面前一道巨大的坎。 迈的过去,将会海阔天空!迈不过去,就要做好准备:很可能有几周甚至几月都要头疼于数据倾斜导致的各类诡异的问题。 郑重声明: 话题比较大,技术要求也比较高,笔者尽最大的能力来写出自己的理解,写的不对和不好的地方大家一起交流
Hive _ Hive 数据倾斜调优策略
hive--Hive之数据倾斜的原因和解决方法 https://blog.csdn.net/qq_34941023/article/details/71189842 hive数据倾斜优化 https://blog.csdn.net/jin6872115/article/details/79878391 Hive学习之路 (十九)Hive的数据倾斜 https://www

31_spark九—数据倾斜与shuffle调优
Spark数据倾斜与shuffle调优 1. 数据倾斜原理和现象分析 1.1 数据倾斜概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。 数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。 1.2 数据倾斜发生时的现象 (1)绝大多数task执行得都非常快,但个别task执行

正射影像、倾斜摄影测量相关软件汇总
从事倾斜摄影测量相关工作的同事经常会用到一些三维建模软件,使用过程中会发现不同软件的优劣势也有一定的区别,以下列举的软件排名不分先后,大家可以根据自己的工作和学习要求进行选择。 1.Pix4D Mapper Pix4Dmapper是一款专门用做测绘的软件,从数据采集(pix4Dcapture)到DOM、DSM及三维模型生产都有涉及。但是三维效果相对于samrt3D来说还是有些差距,但DOM正射
实测:TB级倾斜摄影模型合并根节点前后加载效果对比,结果惊人
随着无人机性能快速提升,单个项目涉及到的倾斜摄影模型数据范围、数据量及单个模型体积也在不断变大,带来的问题是数据显示速度却越来越慢,那么如何在不升级配置的情况下提升模型的加载速度呢? TB级倾斜摄影模型合并根节点前后加载效果对比 未合并根节点的大数据 合并根节点之后的效果 是什么原因导致加载速度差异的呢? 原因在于对模型的加载是以tile瓦片为单位进行扫描显示