本文主要是介绍手把手教你解决 Hive 的数据倾斜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 数据倾斜是什么?
- 产生数据倾斜的场景
- 1.空值引发的数据倾斜
- 2.不可拆分的大文件产生的数据倾斜
- 3.数值膨胀引发的数据倾斜
- 4.不同数据类型引发的数据倾斜
- 5.Count(distinct) 引发的数据倾斜
- 6.表 Join 操作时引发数据倾斜
- 7.group by 引发的数据倾斜
- 解决数据倾斜
- 数据准备
- 模拟数据倾斜场景
- 1.Group By 引发的数据倾斜
- 2.Count(distinct) 引发的数据倾斜
- 3.Join 操作引发的数据倾斜
数据倾斜是什么?
在 Hive 中,数据倾斜是指某些任务的数据量或处理时间远远超过其他任务,导致整体任务执行效率低下的现象。
产生数据倾斜的根本原因是在进行 Shuffle 流程后,导致 Key 的分布不均匀,造成某些 Reduce 处理的数量较大,形成数据倾斜,导致整个任务的执行效率下降。
产生数据倾斜的场景
1.空值引发的数据倾斜
如果在进行聚合操作时,存在大量空值,会导致这些空值会被分配到一个 Reduce 中,导致该 Reduce 需要处理大量的数据,造成数据倾斜现象。
解决方法
-
过滤空值
-
给空值数据设计随机值
例如:
select a,b,c from t1 join t2 on case when t1.id is null then concat('randNum',rand()) else t1.id end = t2.id;
2.不可拆分的大文件产生的数据倾斜
在处理某些大文件数据时,由于其源压缩格式不能进行拆分,例如:Gzip、Snappy,导致在处理这些数据时,只能将其放在一个 MapTask 中进行处理,从而产生数据倾斜。
解决方法
-
先在 HDFS 上进行解压,然后再进行操作
-
尽量选用可拆分的压缩文件格式
3.数值膨胀引发的数据倾斜
在多维聚合计算时,如果进行分组聚合的字段过多,且数据量很大,Map 端的聚合不能很好地起到数据压缩的情况下,会导致 Map 端产出的数据急速膨胀,导致作业产生 OOM。
解决方法
- 在 Hive 中可以通过参数
hive.new.job.grouping.set.cardinality配置的方式自动控制作业的拆解,该参数默认值是30。该参数主要针对grouping sets/rollups/cubes这类多维聚合的操作生效,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
4.不同数据类型引发的数据倾斜
表 A 的 Key 值是 int 类型,表 B 中的 Key 值既有 int 又有 string 类型,在两个表之间进行 Join 操作时,会默认按 Hash 中 int 类型的 id 进行分配,导致大量 string 类型的数据会被分配到一个 Reduce 中,产生数据倾斜。
解决方法
-
在连接时转换为统一的数据类型,将表 B 中的 Key 统一转换为
string类型(虽然表 A 的 Key 是int类型,但是 Hive 底层会在连接时会进行隐式转换) -
在建表时,统一数据类型
5.Count(distinct) 引发的数据倾斜
Count(distinct) 是产生数据倾斜的经典场景,因为该任务是全局排序的操作,在没有分组的情况下,只会产生一个 Reduce 任务,数据量大时自然就会产生数据倾斜。
解决方法
- 先进行去重操作,然后分组统计
例如:
-- 优化前
select a,count(distinct b) from t group by a;-- 优化后
select a,sum(1) from (select a, b from t group by a,b)t1 group by a;
如果去重字段较多,可以先采用上述方式进行计算,最后再进行 union all。
6.表 Join 操作时引发数据倾斜
在小表 Join 大表时,如果某个 Key 的值过大,就会产生数据倾斜。
解决方法
-
MapJoin,将小表加载到内存中,在 Map 端就进行 Join 操作,避免了 Shuffle 流程。在 Hive 中默认开启该功能,但限制了小表的大小,可以通过配置参数
set hive.mapjoin.smalltable.filesize=2500000;进行修改,默认小表最大25MB。将小表放在 Join 操作中的左表中,优先加载到内存中。 -
set hive.auto.convert.join=true;设置是否允许 Hive 自动根据文件量大小将common join转成map join,避免大量的 Shuffle 操作,该值默认为true。
MapJoin 优化就是在 Map 阶段完成 Join 工作,而不是像通常的 common join 在 Reduce 阶段按照 Join 的列值进行分发数据到每个 Reduce 上进行 Join 工作,这样避免了 Shuffle 阶段,从而避免了数据倾斜。
这个操作会将所有的小表全量复制到每个 Map 任务节点,然后再将小表缓存在每个 Map 节点的内存里与大表进行 Join 工作,所以小表的大小的不能太大,否则会出现 OOM 报错。
在 Hive 中,还可以通过 hive.optimize.skewjoin 参数用于处理在执行 JOIN 操作时可能出现的数据倾斜问题,默认为 false。设置这个参数为 true可以让 Hive 自动优化和处理倾斜的 JOIN,从而提高查询性能。
对于检测到的倾斜键值,Hive 会将其单独处理。具体方法是将这些倾斜数据分成小批次,并分配给多个 Reducer 处理。在 Map 阶段,Hive 会统计每个键值的数据量,如果某个键值的数据量超过一定阈值(该值可以通过参数 hive.skewjoin.key 调整,默认为 100000 行),则会被判定为倾斜数据。
如果是大表 Join 大表的场景,且数据量无法通过过滤等操作减少,那么这种情况就只能调整 Reduce 的大小了。
7.group by 引发的数据倾斜
分组维度过小,某值的数量过多,从而引发数据倾斜。
解决方法
- 调整 Hive 参数
set hive.map.aggr=true; --默认true,在map端会做部分聚集操作,效率更高但需要更多的内存
-- 进行GroupBy操作时,是否自动检测并处理数据倾斜,均衡Reducer负载,默认为false
set hive.groupby.skewindata=true;
将 hive.groupby.skewindata 设置为 true 时,它会使数据倾斜时达到负载均衡。
它将计算变成了两个 MapReduce,在第一个 MR 的 shuffle 过程进行 Partition 时,随机给 key 打标记,使每个 key 随机均匀分布到各个 Reduce 上计算,但是这样只能完成部分计算,因为相同 key 没有分配到相同 Reduce上。
第二个 MR 就是正常的执行流程,对第一次 MR 的执行结果再次执行,但是数据分布不均匀的问题在第一个 MR 已经得到了很大的改善,所以并不会造成数据倾斜。
解决数据倾斜
数据准备
在这里,我通过 Python 生成了包含数据倾斜问题的模拟数据:
import random# 文件名
filename = 'input_data.txt'# 数据量
num_records = 50000000# 倾斜key
skewed_key = 'key_skewed'# 生成数据
with open(filename, 'w') as f:for _ in range(num_records):if random.random() < 0.8:f.write(f'{skewed_key}\t{random.randint(1, 100)}\n')else:key = f'key_{random.randint(1, 10000)}'value = random.randint(1, 100)f.write(f'{key}\t{value}\n')print(f'Data written to {filename}')
一共会生成 5000w 条数据,其中 80% 为倾斜数据,因为它们的 key 相同,剩下的为正常数据。
数据生成完成后,大小约为 643MB,将生成的数据上传到 HDFS 中:
hdfs dfs -mkdir -p /user/hive/warehouse/skew_data
hdfs dfs -put input_data.txt /user/hive/warehouse/skew_data/
接下来,创建 Hive 表并加载数据:
CREATE DATABASE IF NOT EXISTS skew_db;
USE skew_db;CREATE TABLE IF NOT EXISTS skewed_table (key STRING,value INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';LOAD DATA INPATH '/user/hive/warehouse/skew_data/input_data.txt' INTO TABLE skewed_table;
这里直接创建,不指定任何存储与压缩格式。
模拟数据倾斜场景
环境说明
- 执行环境:
Hive On Spark - YARN 总资源:
<memory:12 GB, vCores:12> - AM 最小资源:
<memory:1024, vCores:1> - AM 最大资源:
<memory:2048, vCores:2> - 容量调度器:
0.8
1.Group By 引发的数据倾斜
在这里,我先不做任何优化操作,直接进行 group by 操作,按 key 分组统计 value 列的累加求和值。
SELECT key, SUM(value)
FROM skewed_table
GROUP BY key;
执行计划如下:
Explain
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1SparkEdges:Reducer 2 <- Map 1 (GROUP, 53)DagName: ds_20240524105012_45af3c14-bde8-460d-bf4d-ad47b929e96b:1Vertices:Map 1 Map Operator Tree:TableScanalias: skewed_tableStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: key (type: string), value (type: int)outputColumnNames: key, valueStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(value)keys: key (type: string)mode: hashoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col1 (type: bigint)Execution mode: vectorizedReducer 2 Execution mode: vectorizedReduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)keys: KEY._col0 (type: string)mode: mergepartialoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
首先,Stage-1 进行表扫描、选择和分组操作,通过 Map 任务将数据分组,然后通过 Reduce 任务聚合数据。接着,Stage-0 从 Stage-1 获取数据,并输出结果。整个过程采用矢量化执行模式以提高性能。
矢量化执行(Vectorized Execution)是一种提高查询性能的技术,通过一次处理一大块数据(数据块或向量),而不是一行一行地处理。其主要优点包括:
- 更高的处理速度:利用现代 CPU 的并行处理能力,对一批数据进行同时操作。
- 减少函数调用:在处理一大块数据时,只需要一次函数调用,而不是每行数据都调用一次。
- 更好的缓存利用:处理连续的大块数据,提高 CPU 缓存的利用效率。
- 优化内存访问:更高效的内存读取模式,减少访问延迟。
在 Hive 中,可以通过启用矢量化执行参数来利用这种技术:SET hive.vectorized.execution.enabled = true; SET hive.vectorized.execution.reduce.enabled = true;这样,Hive 在处理查询时,会使用矢量化执行来加速数据处理,特别是在处理大数据量时效果显著。
未优化前执行过程如下:
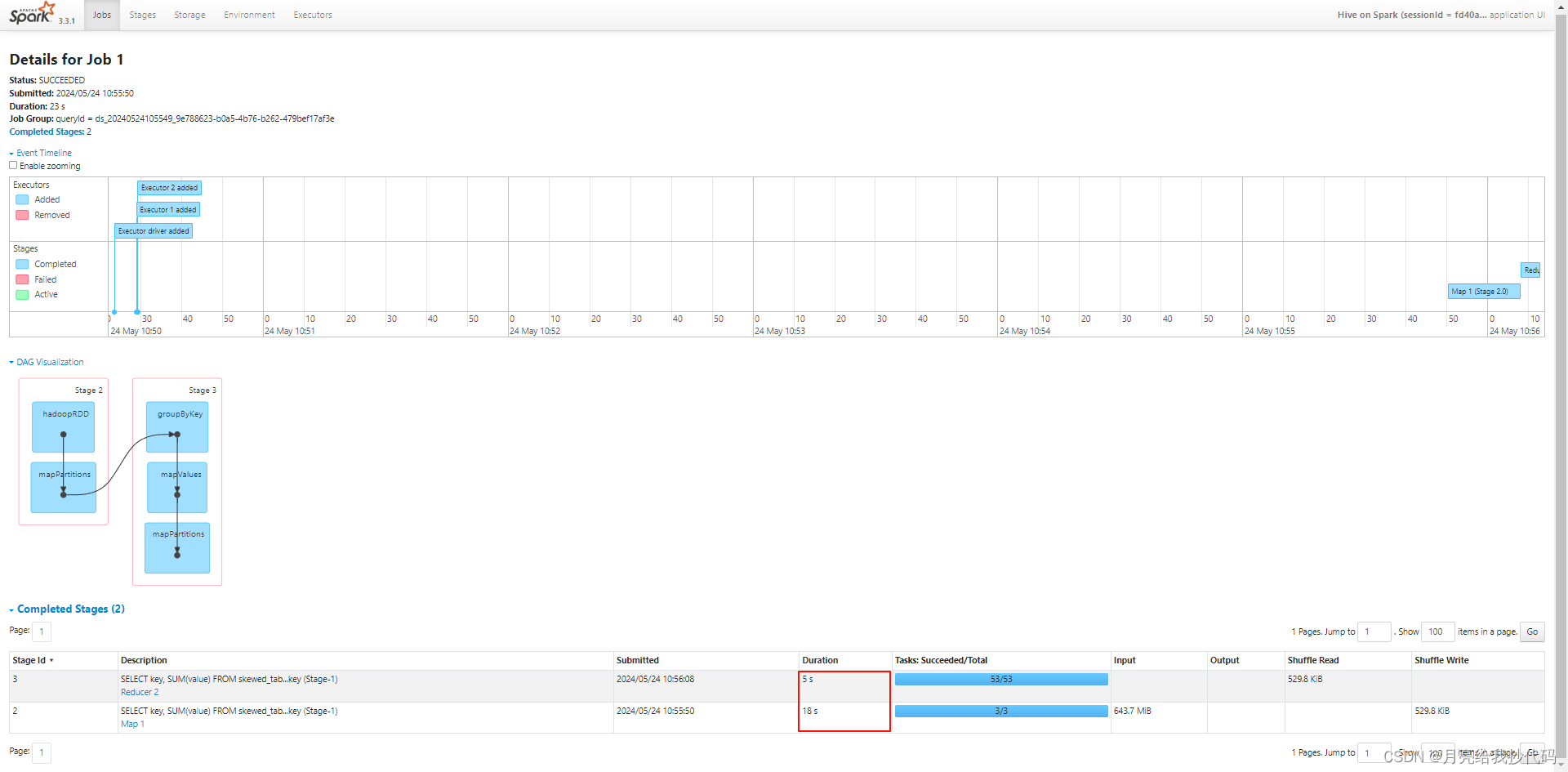
总运行时长为 23s,其中有 3 MapTask, 53 个 ReduceTask,即使没有进行优化,但得益于 Spark 优秀的计算与自动优化能力,它也能做到高效率的运行。
下面调整 Hive 参数,对 group by 数据倾斜进行优化:
-- 控制是否在Map阶段进行部分聚合,默认为true
set hive.map.aggr=true;
-- 进行GroupBy操作时,是否自动检测并处理数据倾斜,均衡Reducer负载,默认为false
set hive.groupby.skewindata=true;
优化后的执行计划如下:
Explain
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1SparkEdges:Reducer 2 <- Map 1 (GROUP PARTITION-LEVEL SORT, 53)Reducer 3 <- Reducer 2 (GROUP, 53)DagName: ds_20240524111335_c1a08cdc-0745-4ee7-8bcb-73813337e5ba:5Vertices:Map 1 Map Operator Tree:TableScanalias: skewed_tableStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: key (type: string), value (type: int)outputColumnNames: key, valueStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(value)keys: key (type: string)mode: hashoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: rand() (type: double)Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col1 (type: bigint)Execution mode: vectorizedReducer 2 Execution mode: vectorizedReduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)keys: KEY._col0 (type: string)mode: partialsoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col1 (type: bigint)Reducer 3 Execution mode: vectorizedReduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)keys: KEY._col0 (type: string)mode: finaloutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
和上面一样,Stage-1 进行表扫描、选择和分组操作,通过 Map 任务将数据分组。第一个 Reduce 做部分聚合(mode: partials),第二个 Reduce 完成最终聚合(mode: final)。接着,Stage-0 从 Stage-1 获取数据,并输出结果。同样,整个过程采用矢量化执行模式。
优化后执行过程如下:
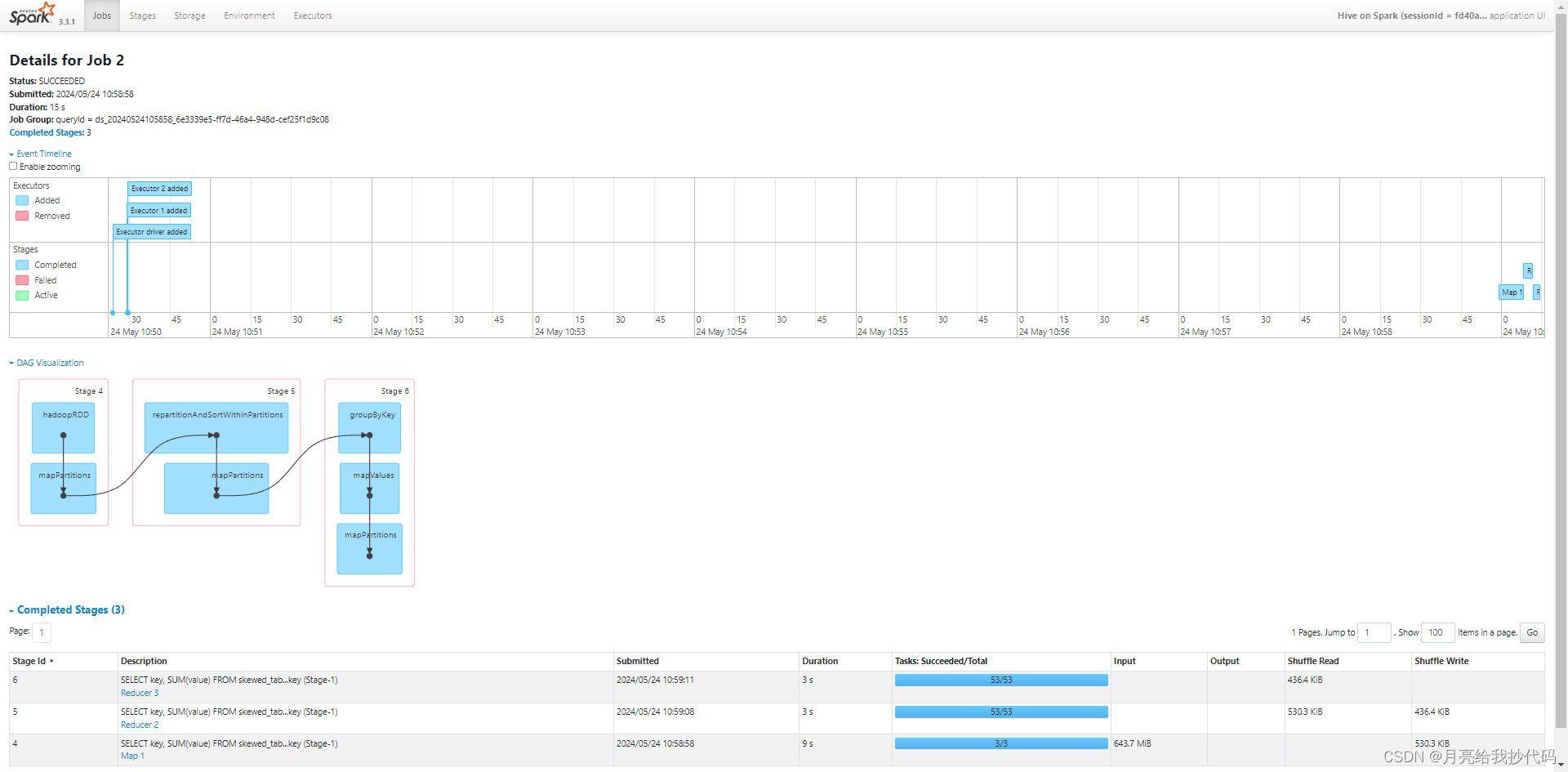
我们从 DAG 图中可以看出,它多了一个阶段,作用是保障倾斜 key 进行分组时的负载均衡操作,改善倾斜 key 造成的影响。
其中有 3 MapTask,2 个 Reduce 任务,每次均为 53 个 ReduceTask。虽然增加了 Reduce 任务,但是运行时长缩短到了 15s,优化了整整 8s,可以看到调参还是起到了一定的作用。
如果你使用的引擎是 Hive On MR,那么该效果会体现的更加明显,感兴趣的同学可以自行尝试一下。
2.Count(distinct) 引发的数据倾斜
不做任何优化,按 key 分组统计每组中存在多少个不同的 value。
SELECT key,count(distinct value) FROM skewed_table GROUP BY key;
执行计划如下:
Explain
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1SparkEdges:Reducer 2 <- Map 1 (GROUP PARTITION-LEVEL SORT, 53)DagName: ds_20240524143342_8247aea2-8786-4f99-a4a8-79cfd844b80a:11Vertices:Map 1 Map Operator Tree:TableScanalias: skewed_tableStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: key (type: string), value (type: int)outputColumnNames: key, valueStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatorkeys: key (type: string), value (type: int)mode: hashoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string), _col1 (type: int)sort order: ++Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEExecution mode: vectorizedReducer 2 Execution mode: vectorizedReduce Operator Tree:Group By Operatorkeys: KEY._col0 (type: string), KEY._col1 (type: int)mode: mergepartialoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: count(_col1)keys: _col0 (type: string)mode: completeoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
首先,Stage-1 进行表扫描、选择和分组操作,通过 Map 任务将数据分组。
这里在 Reduce 任务中,一共有两次 GroupBy 操作,第一次根据 key 和 value 列联合分组去重,减少数据量,然后第二次根据 key 分组统计。最后,Stage-0 从 Stage-1 获取数据,并输出结果,整个过程采用矢量化执行模式。
其实,从这里可以看出,Spark 自动对这种情况进行了优化,它采用的这种方式和我们手动调优的思路是一样的。
未优化前执行过程如下:
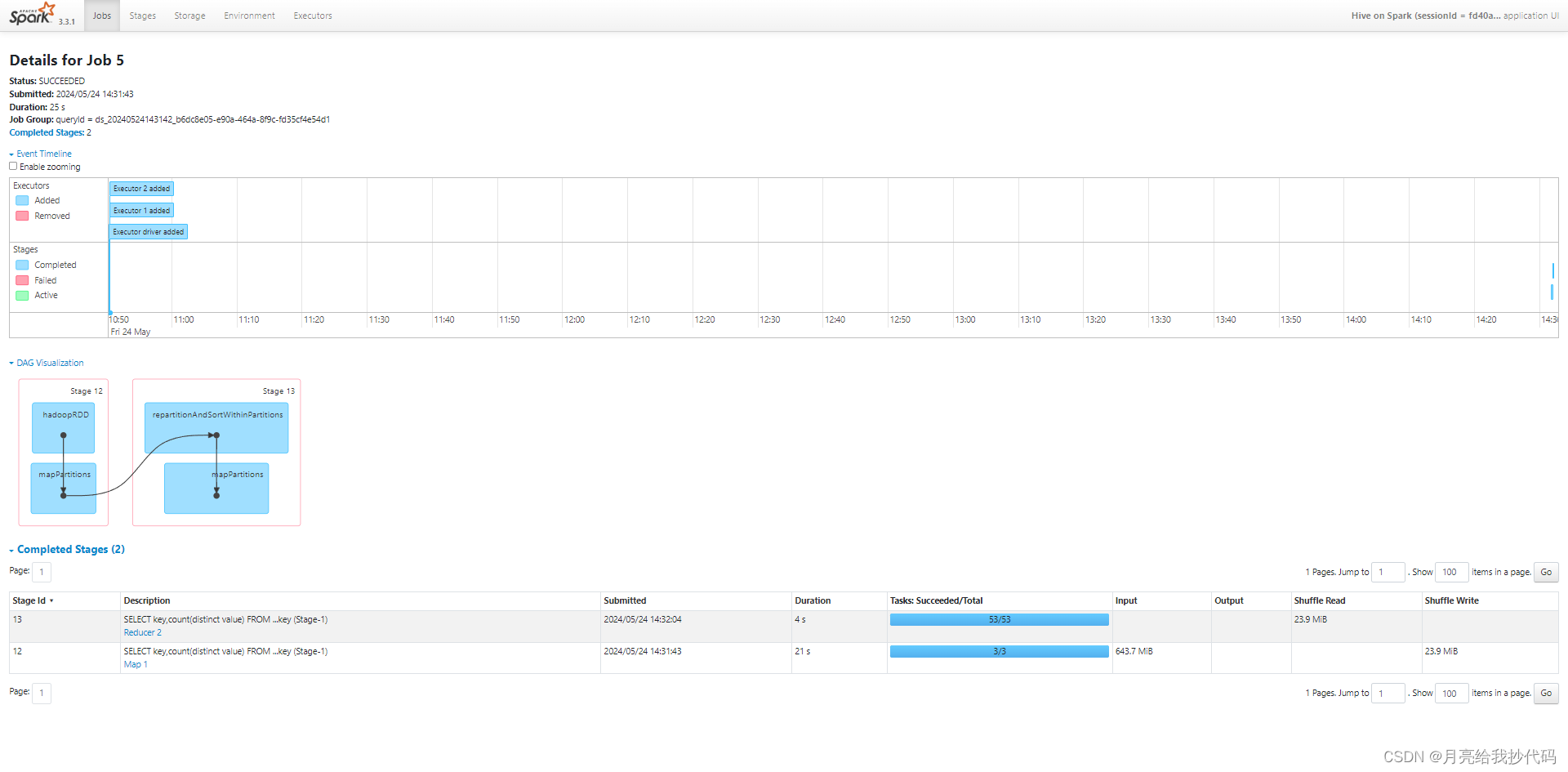
共耗时 25s。
下面通过对 SQL 语句进行优化:
SELECT key,sum(1) FROM (SELECT key,value FROM skewed_table GROUP BY key,value)t1 GROUP BY key;
手动优化后的执行计划如下:
Explain
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1SparkEdges:Reducer 2 <- Map 1 (GROUP PARTITION-LEVEL SORT, 53)DagName: ds_20240524163733_b1dc11cb-2d4b-4a59-8074-804ac1c5a503:13Vertices:Map 1 Map Operator Tree:TableScanalias: skewed_tableStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: key (type: string), value (type: int)outputColumnNames: key, valueStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatorkeys: key (type: string), value (type: int)mode: hashoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string), _col1 (type: int)sort order: ++Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEExecution mode: vectorizedReducer 2 Execution mode: vectorizedReduce Operator Tree:Group By Operatorkeys: KEY._col0 (type: string), KEY._col1 (type: int)mode: mergepartialoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: _col0 (type: string)outputColumnNames: _col0Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(1)keys: _col0 (type: string)mode: completeoutputColumnNames: _col0, _col1Statistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 6748992000 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
优化后执行过程如下:
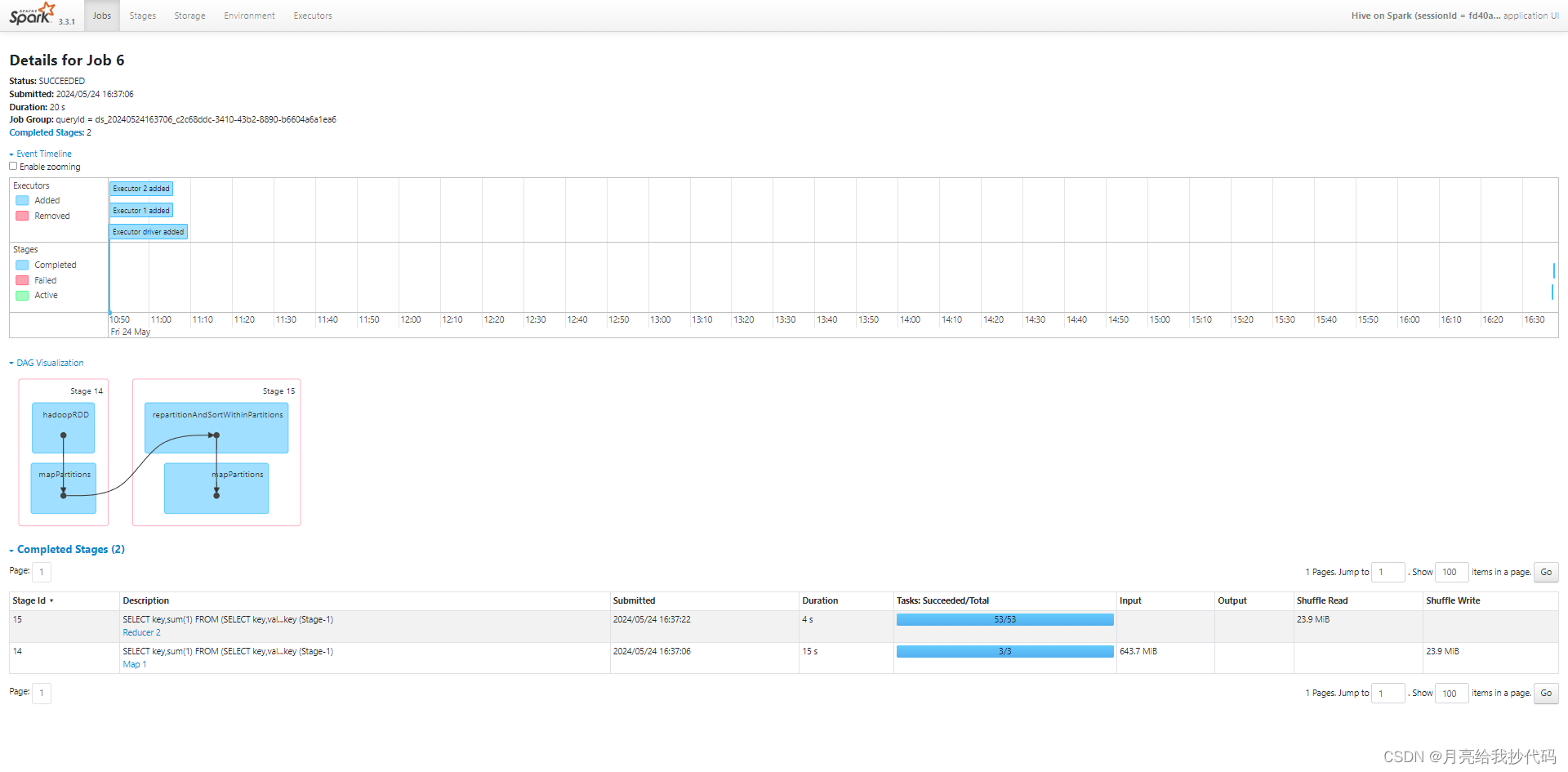
总耗时 20s,缩短了 5s,从执行计划中可以看出,优化前和优化前差不多,这完全是因为 Spark 的功劳,因为它对许多场景都进行了优化,大大减轻了开发人员的负担。
这里快 5s 是因为省去了 Spark 自动调优的时间,因为对 SQL 进行了手动调优,所以 Spark 发现无需再进行优化,直接运行即可,所以这里快了 5s。
3.Join 操作引发的数据倾斜
为了模拟 Join 操作,这里根据主表的数据,再重新创建一张表(后续将此表称为小表):
CREATE TABLE small_table AS SELECT key,'1' `value` FROM skewed_table GROUP BY key;
小表中一共有 10001 条记录,其中的 key 都是不同的值。
现在,将两个表根据 key 进行 Join,完成联合查询:
SELECTsmt.key,smt.value,skt.key,skt.value
FROMsmall_table smt
JOINskewed_table skt
ONskt.key = smt.key
LIMIT10;
毫无疑问,这里肯定会引发数据倾斜,我们小表里头的数据是根据主表的 key 与 value 联合去重后插入的,但是由于我们的主表中,某个 key 存在大量的数据(这里该 key 约为 4000w 条),所以当我在执行 Join 操作时,会因为该 key 直接引发数据膨胀,产生严重的数据倾斜。
先来看看执行流程:
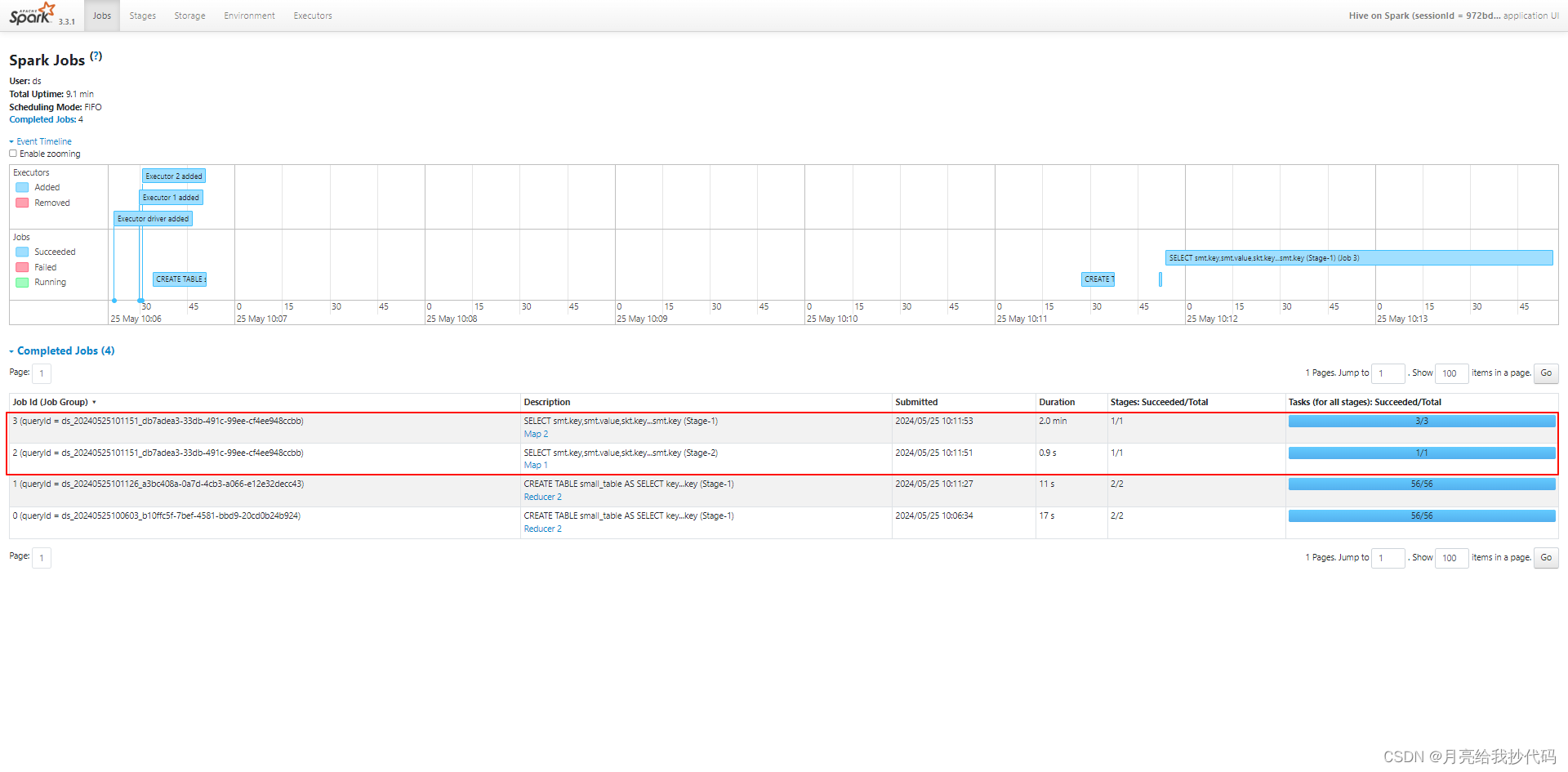
在这个案例中,一共有两个 Map 任务,但是没有 Reduce 任务,这是因为什么呢?
先来看看它们详细的执行内容,首先看第一个 Map:
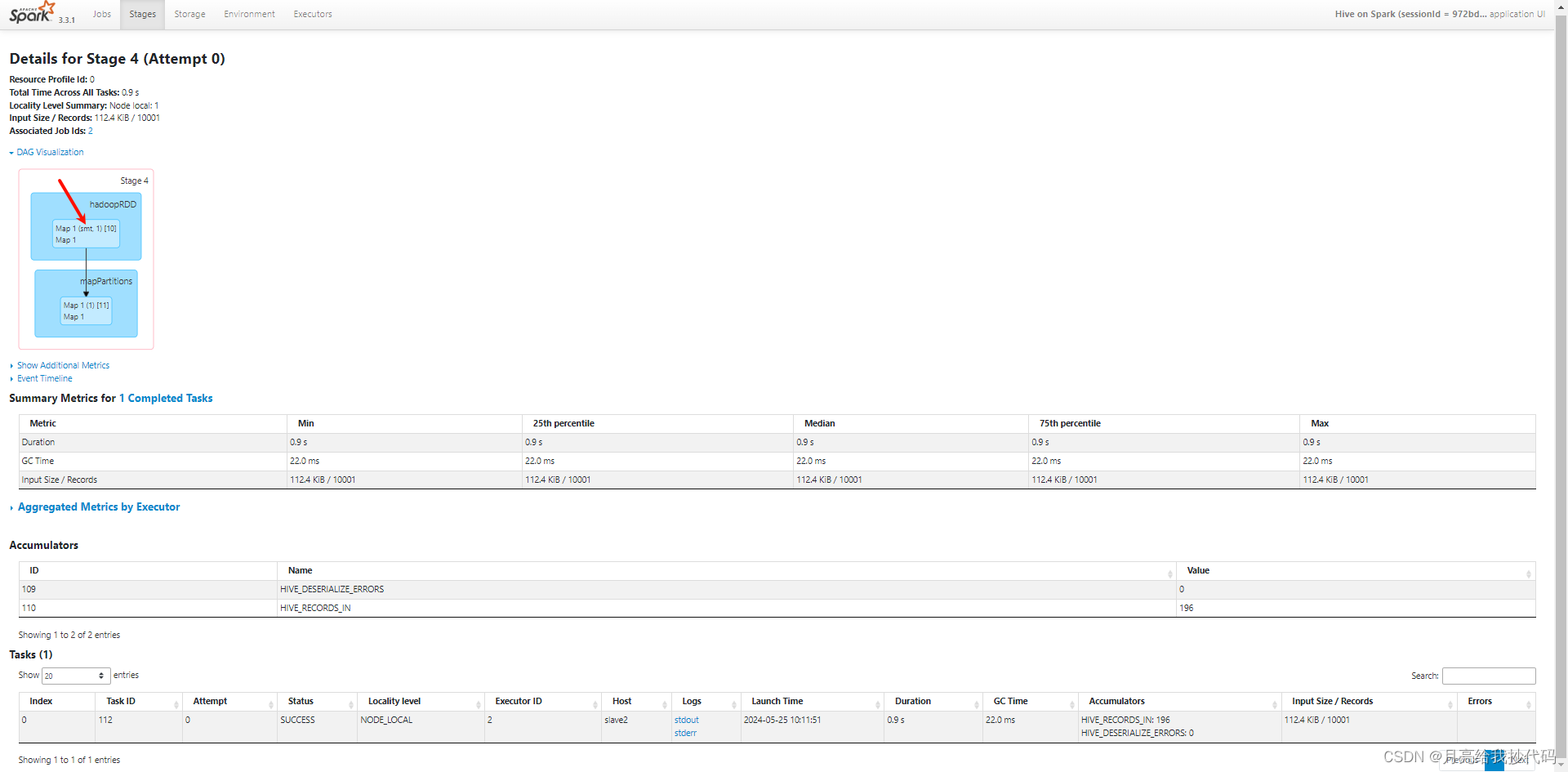
第一个 Map 读取的是小表 small_table 中的数据。
现在我们再来看看第二个 Map 任务:
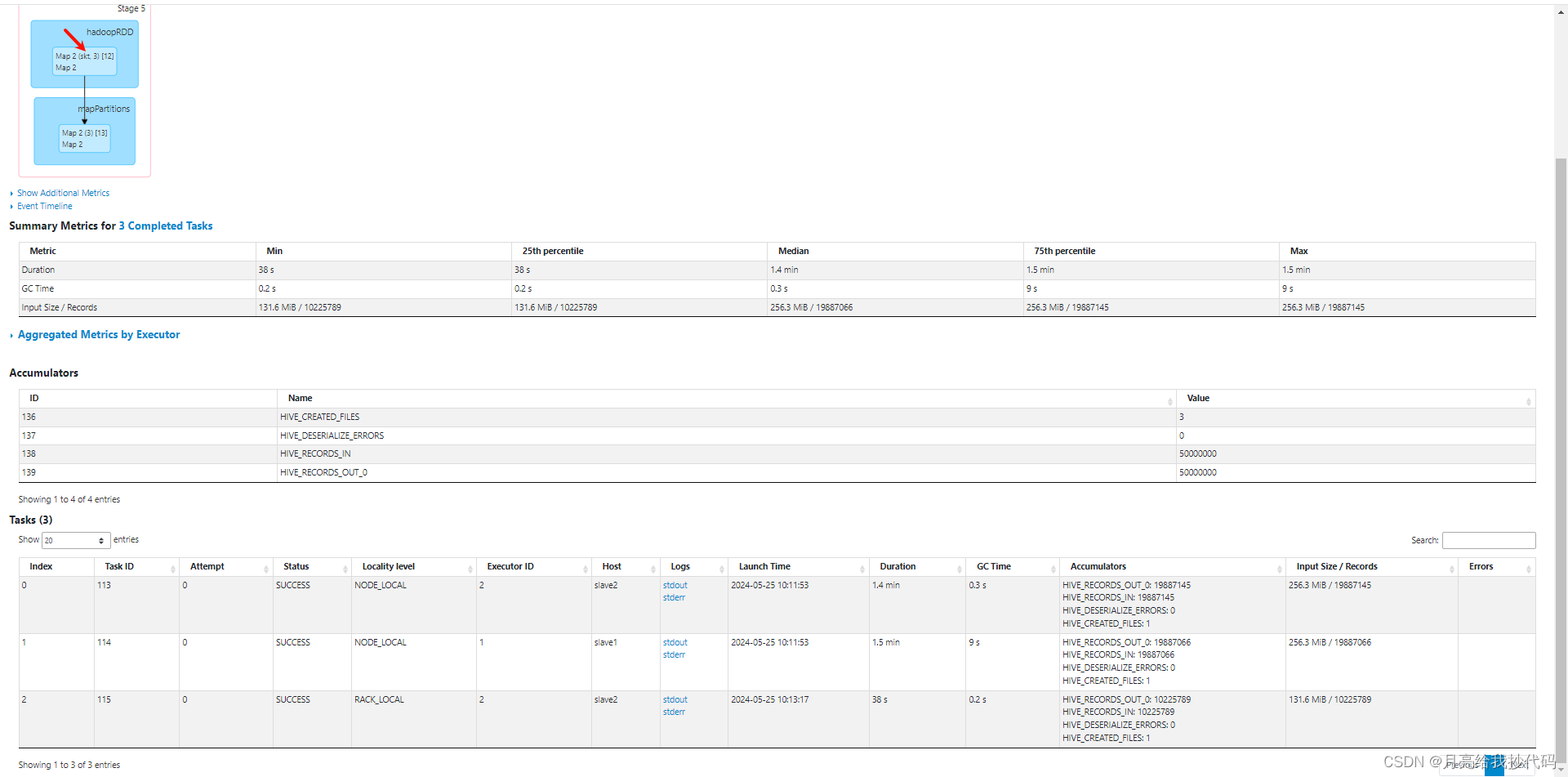
第二个 Map 读取的是主表 skewed_table 中的数据,一共有 3 个 MapTask 任务,因为我们主表的数据文件一共有约 643MB,一个 MapTask 处理 256MB,所以这里需要 3 个 MapTask。
之所以没有 Reduce 任务是因为自动转为了 MapJoin 操作,因为我们小表内容比较少,数据量才 1w 条(约 10MB),而主表有 5000w 条(约 643MB),满足转换为 MapJoin 的条件,它会提前将小表加载到内存中,然后在 Map 阶段执行 Join 操作,避免了 Shuffle 阶段。
所以即使我这里某个 key 的值达到了 4000w 条,它也不会发生数据倾斜。
MapJoin 是默认开启的,所以这里会自动进行转换,可以通过如下参数进行调整:
-- 是否将common join转成map join,默认为true;
set hive.auto.convert.join=true;
--大表Join小表判断的阈值,如果表的大小小于25Mb,则会被判定为小表,默认小表大小为:25Mb
set hive.mapjoin.smalltable.filesize=25000000;
还可以进行一些其它的优化操作:
-- 是否自动处理倾斜的键值,默认false
set hive.optimize.skewjoin=true;
-- 处理自动倾斜的阈值,默认10w行
set hive.skewjoin.key=100000;
当我们开启 Skew Join 之后,在运行时,会对数据进行扫描并检测哪个 key 会出现倾斜,对于会倾斜的 key,会将其分散到多个 Reducer 处理,从而均衡负载,提高查询性能。
这篇关于手把手教你解决 Hive 的数据倾斜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







