本文主要是介绍实测:TB级倾斜摄影模型合并根节点前后加载效果对比,结果惊人,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着无人机性能快速提升,单个项目涉及到的倾斜摄影模型数据范围、数据量及单个模型体积也在不断变大,带来的问题是数据显示速度却越来越慢,那么如何在不升级配置的情况下提升模型的加载速度呢?
-
TB级倾斜摄影模型合并根节点前后加载效果对比

未合并根节点的大数据

合并根节点之后的效果
-
是什么原因导致加载速度差异的呢?
原因在于对模型的加载是以tile瓦片为单位进行扫描显示的,所以tile文件夹越多会导致加载扫描时间瓦片的时长也就越长,内存占用也较多,导致加载和浏览时出现明显卡顿。
1. 为什么倾斜摄影模型分块会产生这么多根节点呢?
在CC(Smart3D)中,对于体积量大的数据建模时都需要对模型进行分块。分块大小的依据是内存,内存大分块大,瓦片数量少;反之,内存小的分块就小,瓦片数就会很多。受内存限制(一般128G,256G是比较大的了),航测范围大,模型体积变大,瓦片数量变多。
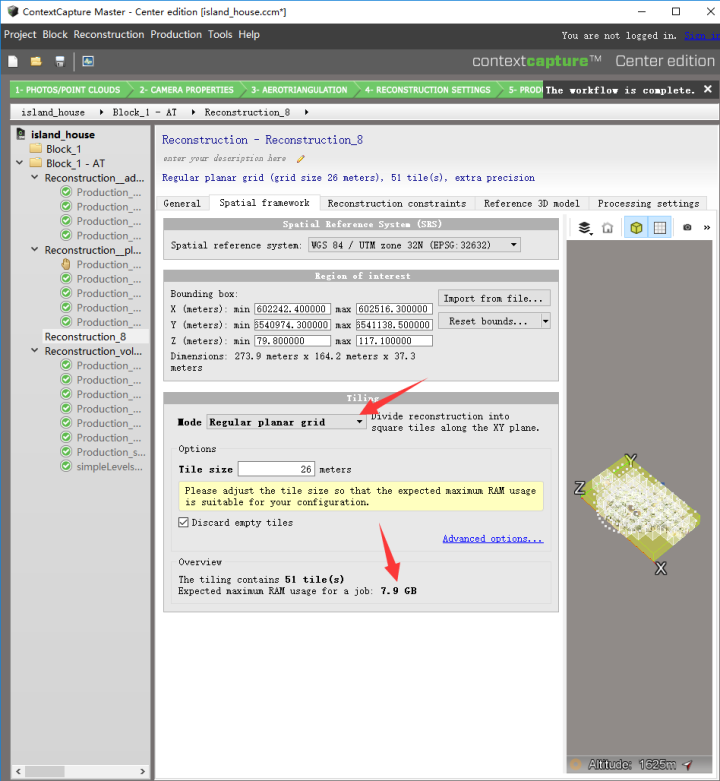
2. CC能否合并根节点呢?
CC软件本身是可以直接对根节点进行合并操作的,但是其操作较为繁琐,存在的问题是瓦片数量过多,软件容易崩溃。
3. 如何解决这个问题?
基于上面说的卡顿原因,不难看出如果模型数据合并根节点后只有一个根节点,是不是就可以秒速加载了呢?尝试解决方案有以下三个方面:
A. 直接从本源入手,建模时提升计算机内存减少分块瓦片数,但是受限于内存;
B. CC直接合并根节点,但崩溃率高;
C. 最佳解决办法:图新地球对已生产好的osgb数据基于原片进行重新生产
-
图新地球合并根节点操作如下:
第一步:图新地球支持对大模型的根节点可进行高速合并,所以首先要下载打开图新地球
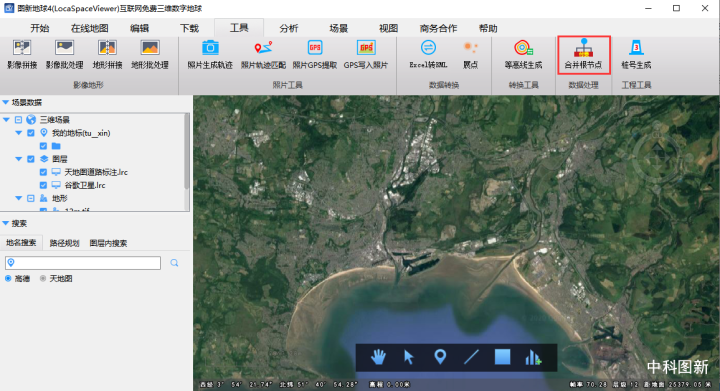
第二步:对原先加载的模型生成lfp索引,再进行根节点合并操作,根据需求对面片数、纹理高宽进行设置;

第三步:在设置好后点击确定进行根节点的合并;
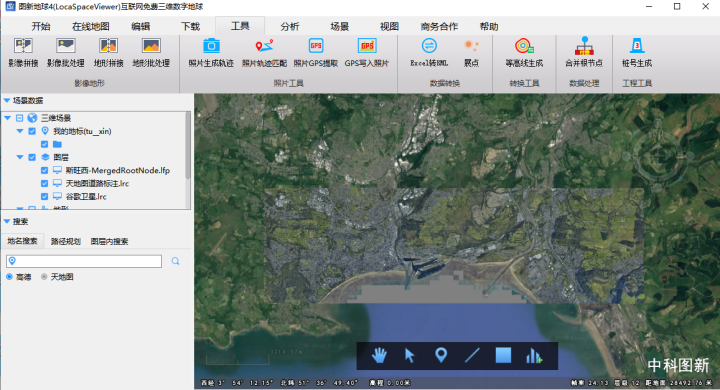
完成合并根节点操作之后,重新打开模型数据即可秒速加载。
-END-
这篇关于实测:TB级倾斜摄影模型合并根节点前后加载效果对比,结果惊人的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





