faiss专题

自然语言处理(NLP)-第三方库(工具包):Faiss【向量最邻近检索工具】【为稠密向量提供高效相似度搜索】【多种索引构建方式,可根据硬件资源、数据量选择合适方式】【支持十亿级别向量的搜索】
一、Faiss介绍 Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。它包含多种搜索任意大小向量集(备注:向量集大小由RAM内存决定)的算法,以及用于算法评估和参数调整的支持代码。Faiss用C++编写,并提供与Numpy完美衔接的Python接口。除此以外,对一些核心算法提供了GPU实

构建高效搜索系统 - Faiss向量数据库的快速入门
目录 快速入门 创建第一个Faiss索引 加载数据到索引中 执行基本查询 评估索引性能 快速入门 创建第一个Faiss索引 先需要导入必要的库,并定义一个索引对象。使用最基础的Flat索引作为例子。 import numpy as npimport faiss# 设置向量的维度d = 128# 创建一个Flat索引,使用L2(欧几里得)距离index = fa

LLM大语言模型调用本地知识库+faiss+m3e-base或是bge-m3 超级简单教程本地存储
LLM大语言模型调用本地知识库+faiss超级简单教程本地存储: 1、新建数据集./data/dz.json: [{"id": "0","text": "你的名字","answer": "张三"}, {"id": "1","text": "你是哪个公司开发的","answer": "xxxxxxxxx公司"},.......更多知识库] 2、下载模型如: moka-ai/m3e-ba
【大数据】深入解析向量数据库Faiss:搭建与使用指南
摘要:本文将介绍向量数据库的概念,重点讲解Faiss这一高性能相似性搜索库。通过分析官网内容,详细阐述Faiss的安装过程及使用方法,帮助读者快速上手并应用于实际项目中。 什么是向量数据 向量数据是一种数据类型,通常用于数学、物理学、计算机科学和数据分析等领域。在技术术语中,向量数据通常指的是以下几种概念: 数学向量: 在数学中,向量是一个具有大小和方向的量,可以在平面上或空间中表示为

【Faiss】基础索引类型(六)
基础索引类型 数据准备 import numpy as np d = 512 #维数n_data = 2000 np.random.seed(0) data = []mu = 3sigma = 0.1for i in range(n_data):data.append(np.random.normal(mu, sigma, d))data = np.arr
【Faiss】indexes 前(后)处理(五)
Pre and post processing 在某些情形下,需要对Index做前处理或后处理。 ID映射 默认情况下,faiss会为每个输入的向量记录一个次序id,在使用中也可以为向量指定任意我们需要的id。 部分index类型有add_with_ids方法,可以为每个向量对应一个64-bit的id,搜索的时候返回这个指定的id。 #导入faissimport syssys.path
【Faiss】indexes IO和index factory(四)
I/O操作 faiss.write_index(index, "index_file.index") #将index保存为index_file.index文件index = faiss.read_index("index_file.index") #读入index_file.index文件 #完全复制一个indexindex_new = faiss.clone_index(index)i

【Faiss】快速入门(二)
Tutorial 快速入门 数据准备 faiss可以处理固定维度d的向量集合,这样的集合这里用二维数组表示。 一般来说,我们需要两个数组: 1.data。包含被索引的所有向量元素; 2.query。索引向量,我们需要根据索引向量的值返回xb中的最近邻元素。 为了对比不同索引方式的差别,在下面的例子中我们统一使用完全相同的数据,即维数d为512,data包含2000个向量,每个向量符合正态分布。
【faiss】安装(一)
faiss安装 使用Anaconda安装 使用Anaconda安装使用faiss是最方便快速的方式,facebook会及时推出faiss的新版本conda安装包,在conda安装时会自行安装所需的libgcc, mkl, numpy模块。 faiss的cpu版本目前仅支持Linux和MacOS操作系统,gpu版本提供可在Linux操作系统下用CUDA8.0/CUDA9.0/CUDA9.1编译的
【faiss】使用的一点总结
1,支持两种相似性计算方法:L2距离(即欧式距离)和点乘(归一化的向量点乘即cosine相似度); 2,按照是否编码压缩数据可以分为两类算法,使用压缩的算法可以在单台机器上处理十亿级别的向量规模; 3,并非线程安全的——不支持并行添加向量或搜索与添加的并行;仅在CPU模式下支持并行搜索; 4,只有继承了IndexIVF 的算法才支持向量的 remove() 操作,但由于是连续存储,remove的时
【Faiss】GPU
Fassi通过CUDA支持GPU,要求3.5以上算力,float16要求CUDA7.5+ 通过index_gpu_to_cpu可以将索引从GPU复制到CPU,index_cpu_to_gpu 和 index_cpu_to_gpu_multiple可以从CPU复制到GPU,并支持GpuClonerOptions来调整GPU存储对象的方式。 GpuIndexFlat, GpuIndexIVFFla
向量数据库 Faiss 的搭建与使用
向量数据库 Faiss 的搭建与使用 一、引言 在人工智能和大数据技术飞速发展的今天,向量数据库作为处理高维数据检索的关键技术,越来越受到重视。Faiss,作为由 Meta AI(原 Facebook AI Research)开源的高效相似性搜索库,以其卓越的性能和灵活性,成为众多技术选型中的佼佼者。本文将深入探讨 Faiss 的搭建和使用,旨在为读者提供一个全面而详细的指南。 二、Fais

详细说明:向量数据库Faiss的搭建与使用
当然,Faiss(Facebook AI Similarity Search)是一个用来高效地进行相似性搜索和密集向量聚类的库。它能够处理大型数据集,并且在GPU上的性能表现尤为出色。下面详细介绍Faiss的搭建与使用。 1. 搭建Faiss 1.1 安装依赖包 首先,需要安装Faiss及其依赖包。可以使用如下命令: # 如果使用CPU版本pip install faiss-cpu#

深入理解Faiss:高效向量检索的利器
近年来,随着人工智能和机器学习技术的飞速发展,向量检索技术变得越来越重要。无论是在推荐系统、图像搜索还是自然语言处理等领域,向量检索都扮演着至关重要的角色。而在众多向量检索库中,Faiss(Facebook AI Similarity Search)无疑是最受欢迎的选择之一。本文将带你深入了解Faiss,探讨其核心原理、关键特性和实际应用。 一、什么是Faiss?
使用faiss存储HuggingFaceBgeEmbeddings向量化处理数据及反序列化加载使用的例子
周末宅在家里无所事事,实验了一下如何使用bge对word文档进行向量化处理后并存储到faiss里面供后续反序列化加载使用,下面是具体实现代码。 一,加载word数据并读取内容进行向量化存储 import osimport docxfrom tqdm import tqdmfrom langchain.docstore.document import Documentfrom langc
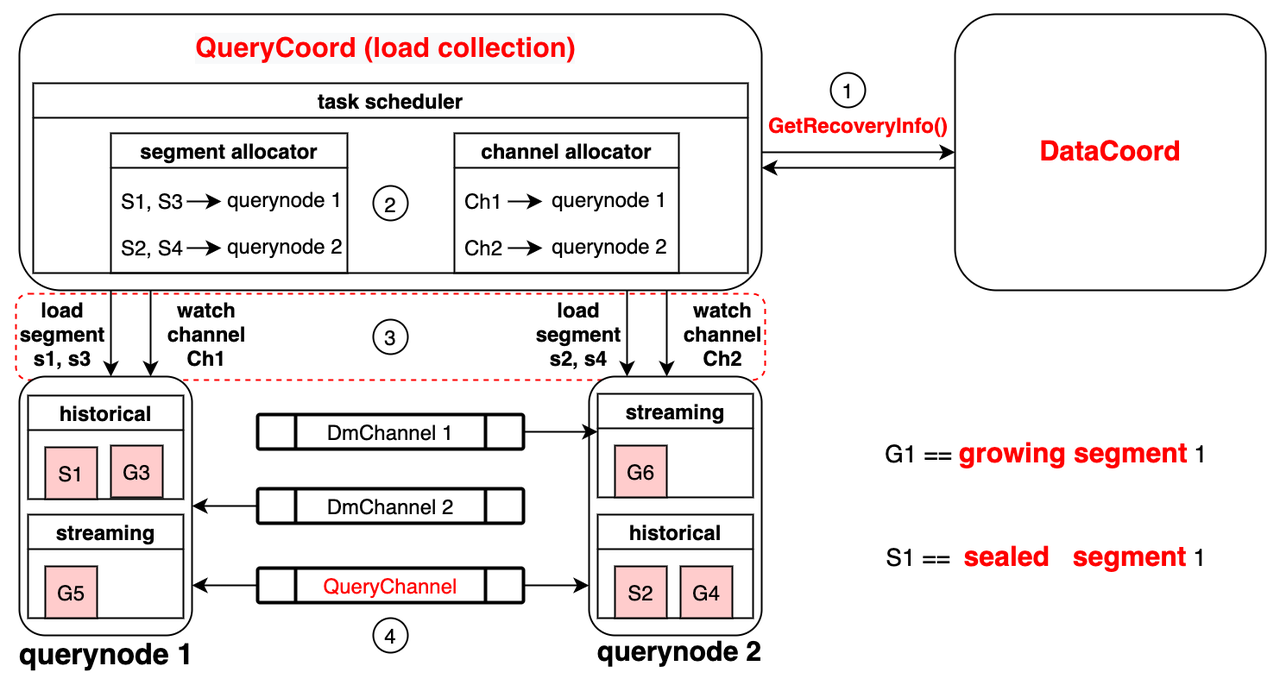
【向量检索】之向量数据库Milvus,Faiss详解及应用案例
Reference https://www.modb.pro/db/509268 笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等 - 知乎 (zhihu.com) 向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss - 苏洋的文章 - 知乎 常用的三种索引方式及原理-CSDN 向量搜索应用 向量检索技术,其

Faiss框架使用与FaissRetriever实现
Faiss是一个由Facebook AI Research开发的库,用于高效相似性搜索和稠密向量聚类。它为机器学习和深度学习中的向量检索问题提供了一种高效的解决方案,特别是在处理大规模数据集时。Faiss支持多种索引类型,包括基于量化的索引、基于聚类的索引和基于哈希的索引等,以适应不同的应用场景和性能需求。 FaissRetriever是一个基于Faiss的检索器,它通常用于检索与给定查询向量最相
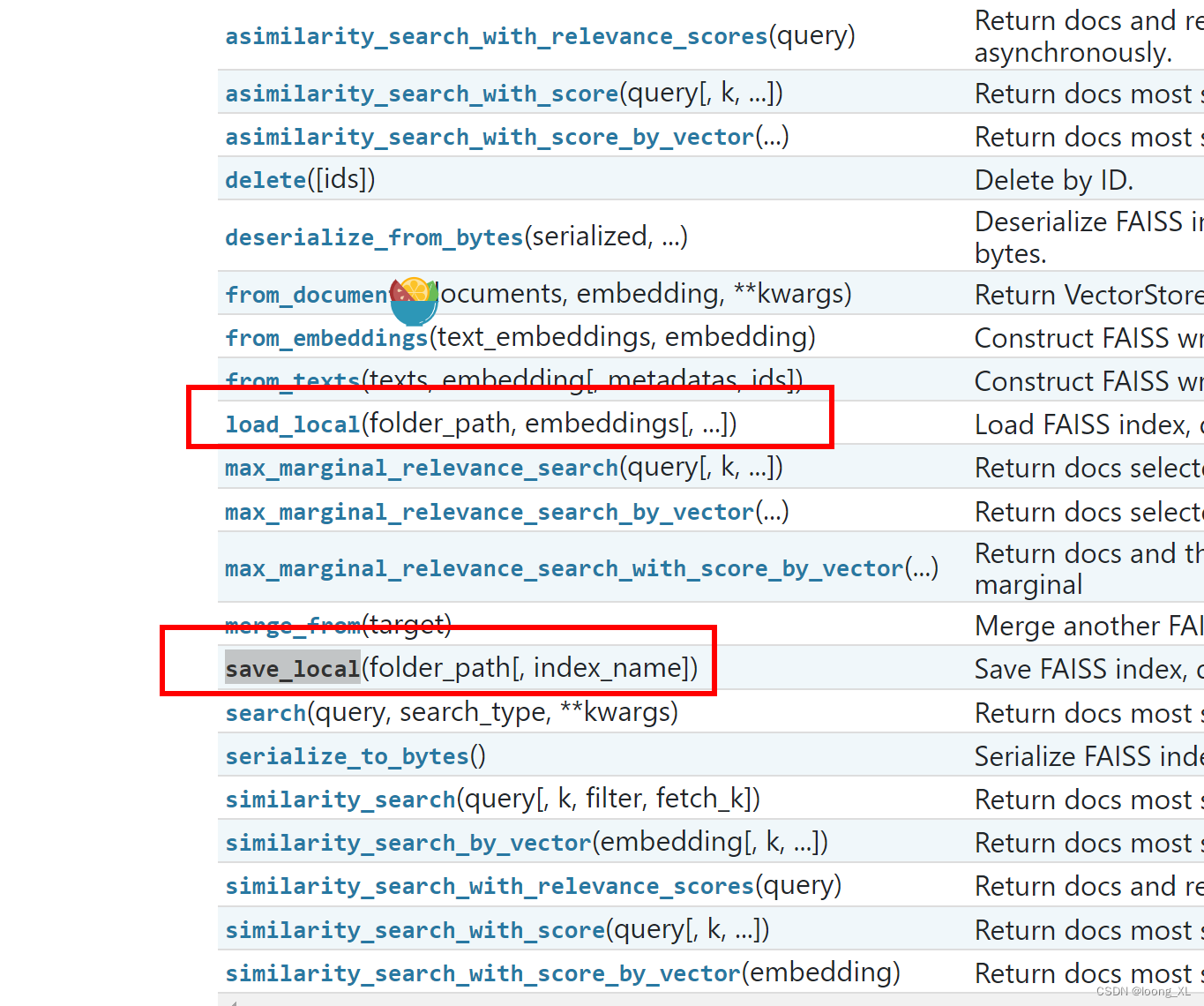
langchain_community FAISS保存与加载faiss index
参考: https://github.com/langchain-ai/langchain/issues/18285 https://api.python.langchain.com/en/latest/vectorstores/langchain_community.vectorstores.faiss.FAISS.html#langchain_community.vectorstores.fa

Faiss核心解析:提升推荐系统的利器【AI写作免费】
首先,这篇文章是基于笔尖AI写作进行文章创作的,喜欢的宝子,也可以去体验下,解放双手,上班直接摸鱼~ 按照惯例,先介绍下这款笔尖AI写作,宝子也可以直接下滑跳过看正文~ 笔尖Ai写作:只要输入简单的要求和描述,就能自动生成各种高质量文稿内容。笔尖Ai写作:内置1000+写作模板,小白也能快速上手。 Ai论文、Ai开题报告、Ai公文写作、Ai商业计划书、文献综述、Ai生成、Ai文献推荐、Ai论

Faiss: 使用conda安装faiss-cpu库
Faiss是用于相似性搜索和密集聚类向量的库,安装了Anaconda版本的Python,可以使用conda命令来安装faiss-cpu版本库: conda install -c pytorch faiss-cpu 有些朋友留言问faiss-cpu支持的操作系统版本,从目前anaconda官网给出的信息,目前仅支持MAC和Linux的版本,并不支持Windows系统。相关信息可以参考官网的给出
Faiss:高效相似度搜索与索引技术深度解析
Faiss:高效相似度搜索与索引技术深度解析 一、引言 在大数据时代,信息的海量化使得快速、准确地从海量数据中检索出相似信息变得至关重要。Faiss(Facebook AI Similarity Search)是一个由Facebook AI团队开发的开源库,专为高维向量相似性搜索和密集向量聚类而设计。Faiss凭借其高效的索引结构和搜索算法,在图像检索、推荐系统、信息检索等领域得到了广泛应用。

【简单介绍下Faiss原理和使用】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 🥳目录 🥳Faiss简介🥳Faiss的原理🥳Faiss使用🥳Faiss使用注意事项 🥳Faiss简介 💥Faiss是Facebook AI R
Faiss:高效向量搜索引擎的原理与实践
向量搜索在机器学习、数据检索和推荐系统中扮演着至关重要的角色。它能够帮助我们快速找到在大规模数据集中与查询点最接近的数据点。Faiss(发音类似于"fess"),是由Facebook AI Research(FAIR)团队开发的一个库,专门用于高效地进行大规模向量的相似性搜索和聚类。本文将详细分析Faiss的原理,并提供实用的使用总结,帮助读者更好地理解和利用这个强大的工具。 1. 什么是Fai

Faiss使用指南:5步掌握高效相似性搜索【AI写作助手】
首先,这篇文章是基于笔尖AI写作进行文章创作的,喜欢的宝子,也可以去体验下,解放双手,上班直接摸鱼~ 按照惯例,先介绍下这款笔尖AI写作,宝子也可以直接下滑跳过看正文~ 笔尖Ai写作:只要输入简单的要求和描述,就能自动生成各种高质量文稿内容。笔尖Ai写作:内置1000+写作模板,小白也能快速上手。 Ai论文、Ai开题报告、Ai公文写作、Ai商业计划书、文献综述、Ai生成、Ai文献推荐、Ai论

langchain 链式写法-使用本地 embedding 模型,Faiss 检索
目录 示例代码1 示例代码2 示例代码1 使用本地下载的 embedding 模型去做 embedding,然后从中查相似的 import osfrom dotenv import load_dotenvfrom langchain_community.llms import Tongyiload_dotenv('key.env') # 指定加载 env 文件key