dbscan专题

用Pytho解决分类问题_DBSCAN聚类算法模板
一:DBSCAN聚类算法的介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,DBSCAN算法的核心思想是将具有足够高密度的区域划分为簇,并能够在具有噪声的空间数据库中发现任意形状的簇。 DBSCAN算法的主要特点包括: 1. 基于密度的聚类:DBSCAN算法通过识别被低密

机器学习:DBSCAN算法(内有精彩动图)
目录 前言 一、DBSCAN算法 1.动图展示(图片转载自网络) 2.步骤详解 3.参数配置 二、代码实现 1.完整代码 2.代码详解 1.导入数据 2.通过循环确定参数最佳值 总结 前言 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法。

机器学习 之 DBSCAN算法 及实现
1.K-means 与 DBSCAN 的比较 K-means 和 DBSCAN 都是聚类算法,但它们之间有显著的区别: K-means: 基于中心点的方法,要求用户提前指定簇的数量。适用于球形簇,且簇大小相近。无法处理噪声数据和任意形状的簇。 DBSCAN: 基于密度的方法,无需提前指定簇的数量。可以发现任意形状的簇,并能识别噪声点。适合处理含有噪声的数据集和不规则形状的簇。 以下图中的数

《机器学习》 DBSCAN算法 原理、参数解析、案例实现
目录 一、先看案例 1、对K-mean算法 1)优点: 2)缺点: 2、使用DBSCAN去分类 二、DBSCAN算法 1、什么是DBSCAN 2、实现过程 三、参数解析 1、用法 2、参数 1)eps: 邻域的距离阈值 2)min_samples: 样本点要成为核心对象所需要的ϵϵ-邻域的样本数阈值 3)metric:最近

【机器学习】(5.4)聚类--密度聚类(DBSCAN、MDCA)
1. 密度聚类方法 2. DBSCAN DBSCAN(Density-Based Spatial Clustering of Applications with Noise)。一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为 密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。 2.1 DBSCAN算

DBSCAN算法及Python实践
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的空间聚类应用)算法是一种基于密度的聚类算法,它在机器学习和数据挖掘领域有广泛的应用。以下是DBSCAN算法的主要原理和特点: 一、基本原理 DBSCAN算法将簇定义为密度相连的点的最大集合,即一个簇是由密度可达关系导出的最大密度相连样本集合。

聚类算法:DBScan算法
对算法的用例是在Spark平台对学生上网记录处理的一个实例,参考地址见GitHub上的DBScan算法运用实例 一、问题提出 先考虑一个问题,对下左图中的数据集合怎么聚类?对右图的无规则的数据集合又该如何聚类? 二、概念介绍 邻域半径(radius):以当前对象为核心确定密度区域范围时引用的长度,二维平面中就指以当前对象为圆心确定圆时引用所用的半径。如下图中的Eps

004、KMeans和DBSCAN的比较
KMeans 聚类 工作原理 选择K个初始中心点(可以随机选择或使用其他方法)。迭代过程: 分配每个数据点到最近的中心点:计算每个数据点到所有中心点的距离,将数据点分配到最近的中心点所属的簇。更新中心点:计算每个簇内所有数据点的均值,将该均值作为新的中心点。 停止条件:当中心点不再变化或达到预设的最大迭代次数时停止迭代。 优缺点 优点: 简单易理解,容易实现。计算速度快,适合大规模数据集。

从大量文本中挖掘‘典型意见‘-基于DBSCAN的文本聚类实战
文本聚类,是一个无监督学习里面非常重要的课题,无论是在风控还是在其他业务中,通过对大规模文本数据的分析,找出里面的聚集观点,有助于发现新的问题或者重点问题。 通过对评论文本的分析,我们可以发现消费者关注的产品或服务痛点 通过对店铺商品标题的文本聚类,可以知道店铺主要集中卖什么类型的商品 通过对来电语音转文本聚类,可以知道公司售后业务的典型问题或者新问题的爆发 ... ... 通过对新闻文

【聚类】基于位置(kmeans)层次(agglomerative\birch)基于密度(DBSCAN)基于模型(GMM)
原博文: 一、聚类算法简介 聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别使得内内相似性大,内间相似性小。有时候作为监督学习中稀疏特征的预处理(类似于降维,变成K类后,假设有6类,则每一行都可以表示为类似于000100、010000)。有时候可以作为异常值检测(反欺诈中有用)。 应用场景:新闻聚类、用户购买模式(交

DBSCAN 算法【python,机器学习,算法】
DBSCAN 即 Density of Based Spatial Clustering of Applications with Noise,带噪声的基于空间密度聚类算法。 算法步骤: 初始化: 首先,为每个数据点分配一个初始聚类标签,这里设为0,表示该点尚未被分配到一个聚类中。设置一个聚类ID(cluster_id),初始化为0,用于标识不同的聚类。 遍历数据点: 遍历数据集中的每个点。如
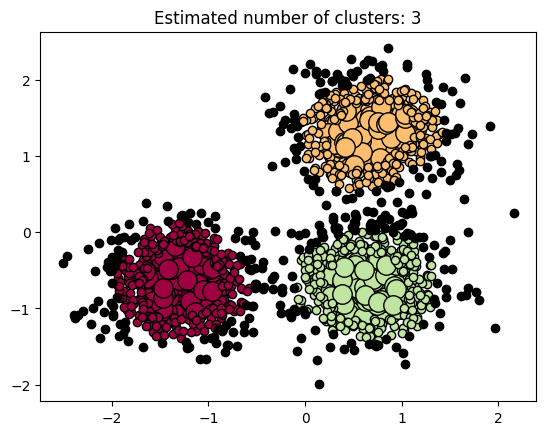
基于密度的聚类算法DBSCAN详解!
公众号:尤而小屋编辑:Peter作者:Peter 大家好,我是Peter~ 今天给大家介绍基于密度的聚类算法DBSCAN,包含: DBSCAN算法定义sklearn.cluster.DBSCAN参数详解DBSCAN聚类实战DBSCAN聚类效果评估DBSCAN聚类可视化DBSCAN算法优缺点总结 https://scikit-learn.org/stable/auto_examp
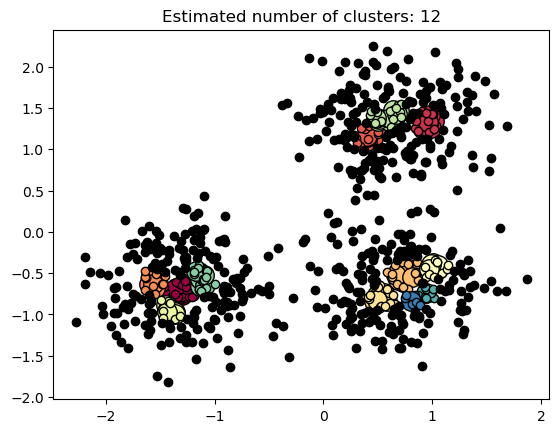
【机器学习聚类算法实战-5】机器学习聚类算法之DBSCAN聚类、K均值聚类算法、分层聚类和不同度量的聚集聚类实例分析
🎩 欢迎来到技术探索的奇幻世界👨💻 📜 个人主页:@一伦明悦-CSDN博客 ✍🏻 作者简介: C++软件开发、Python机器学习爱好者 🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+ 如果文章有所帮助,欢迎留下您宝贵的评论, 点赞加收藏支持我,点击关注,一起进步! 目录 前言 正文 01- DBSCAN聚类算法简

点云DBSCAN聚类,同时获取最多点数量的类,同时删除其他的类并显示
代码的主要目的是处理一个点云文件(从某个巷道或类似环境中获取的),并尝试识别并可视化其中的主要结构(比如墙壁),同时去除可能的噪声和异常点。它首先读取一个点云文件,进行降采样和异常点移除,然后使用DBSCAN聚类算法对剩余的点云进行聚类,最后选择并可视化包含最多点的聚类,该聚类理论上应代表墙壁。 细节分析: 设定点云文件路径 filename_model1 和降采
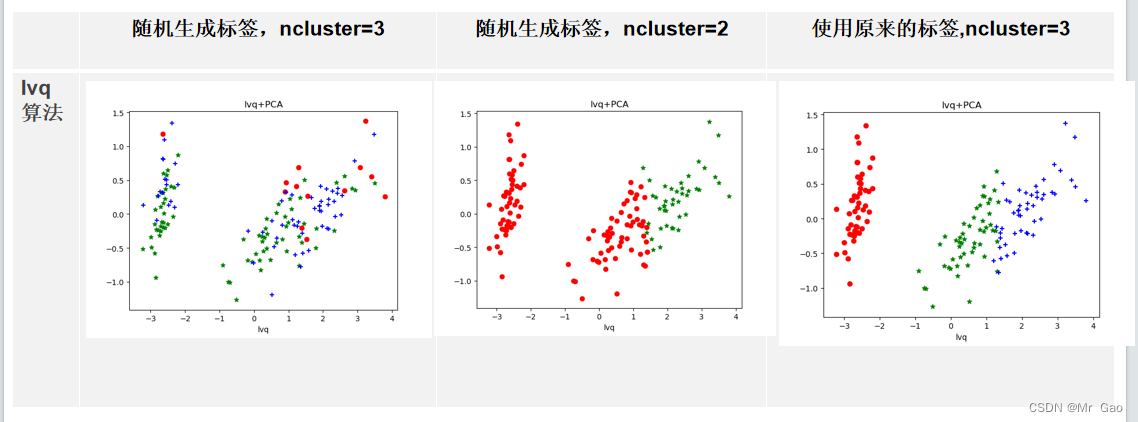
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比 注:下面的代码可能需要做一点参数调整,才得到所有我的运行结果。 kmeans算法: import matplotlib.pyplot as plt # 导入matplotlib的库import numpy as np # 导入numpy的包from sklearn import datase

DBSCAN算法学习
DBSCAN算法 文章目录 DBSCAN算法概述应用场景优缺点基于sklearn库的样例DBSCAN、分层聚类和K均值聚类比较 概述 DBSCAN算法是一种基于密度的聚类算法,能够自动识别不同的簇,并与噪声数据分开。以下是关于DBSCAN算法的重要知识点概述: 基本概念: DBSCAN是Density-Based Spatial Clustering of Applica

DBSCAN 论文笔记-理解
论文: 点击这里下载DBSCAN论文原文 论文翻译:-.- 理解参考: 论文/算法的理解 https://www.cnblogs.com/pinard/p/6208966.html http://blog.csdn.net/Exupery_/article/details/76181272Python sklearn.cluster.DBSCAN的理解使用 http://scikit-

【聚类算法】DBSCAN详解
目录 定义计算步骤代码演示总结 定义 今天,我们一起学习聚类算法分享章节中中的最后一类 —— 密度聚类算法。而在密度聚类里面最具代表性的是DBSCAN。(Density-Based Spatial Clustering of Applications with Noise)对应的中文翻译就是基于密度的噪点空间聚类法。名字是不是有点拗口?其实没关系。你只要记住它是基于点密度的聚类方
使用Python实现DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它可以有效地识别具有任意形状的簇,并且能够自动识别噪声点。在本文中,我们将使用Python来实现一个基本的DBSCAN聚类算法,并介绍其原理和实现过程。 什么是DBSCAN算法? DBSCAN算法通过检测数据点的密度来发现簇。它定义了两
【图像分割】基于matlab DBSCAN算法超像素分割【含Matlab源码 515期】
⛄一、获取代码方式 获取代码方式1: 完整代码已上传我的资源:【图像分割】基于matlab DBSCAN算法超像素分割【含Matlab源码 515期】 点击上面蓝色字体,直接付费下载,即可。 获取代码方式2: 付费专栏Matlab图像处理(初级版) 备注: 点击上面蓝色字体付费专栏Matlab图像处理(初级版),扫描上面二维码,付费29.9元订阅海神之光博客付费专栏Matlab图像处理(初级

DBSCAN密度聚类-Python
# -*- coding: utf-8 -*-"""Spyder EditorThis is a temporary script file.密度聚类亦称“基于密度的聚类”(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定DBSCAN是一种著名的密度聚类算法,主要是依赖两个主要的参数来进行聚类的,即对象点的区域半径Eps和区域内点的个数

k-means、DBSCAN、层次聚类等常用5中聚类方法
文章目录 1 K-Means聚类2 均值漂移聚类3 具噪声基于密度的空间聚类算法4 高斯混合模型的期望最大化聚类5 凝聚层次聚类 1 K-Means聚类 基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中
机器学习-06-无监督算法-02-层次聚类和密度聚类DBSCAN算法
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中无监督算法,包括层次和密度聚类等。 参考 DBSACN在线动态演示 本门课程的目标 完成一个特定行业的算法应用全过程: 懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合 +算法评估+持续调优+工程化接口实现 机器学习定义 关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用: 对于某
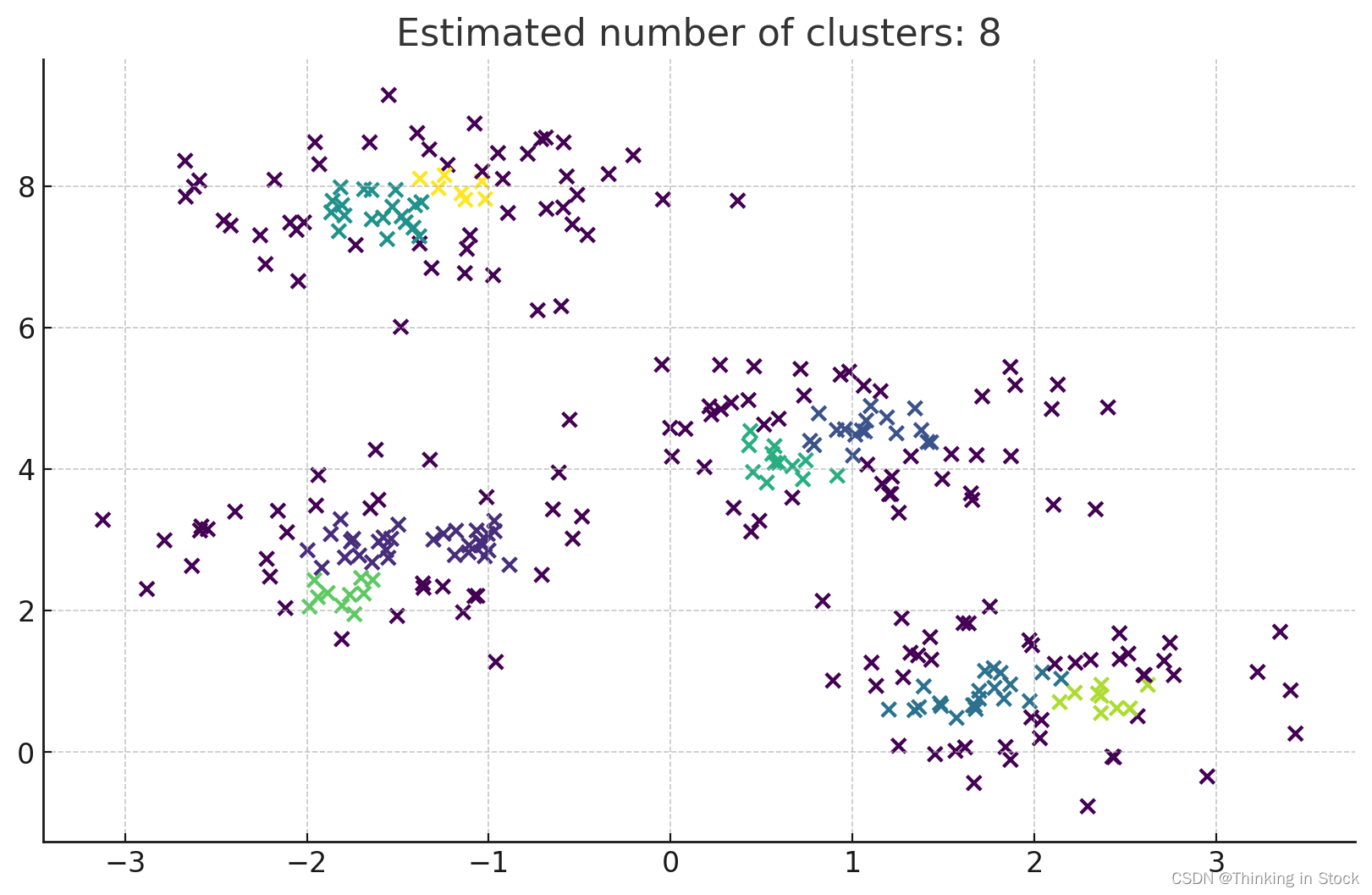
【理解机器学习算法】之Clustering算法(DBSCAN)
DBSCAN(基于密度的空间聚类应用噪声)是数据挖掘和机器学习中一个流行的聚类算法。与K-Means这样的划分方法不同,DBSCAN特别擅长于识别数据集中各种形状和大小的聚类,包括存在噪声和离群点的情况。 以下是DBSCAN工作原理的概述: 1. 核心概念: - Epsilon (ε):距离参数,指定点周围邻域的半径。 - 最小点数 (MinPts):形成密集区域所需的最小点数,这
聚类算法DBSCAN
DBSCAN:Density-Based Spatial Clustering of Applications with Noise,基于密度和带有噪声点的聚类。 DBSCAN算法与K-MEANS算法一样,没有数学原理上的推导,理解起来比较容易。K-MEANS算法可以处理简单的数据集,对于复杂数据集的分类效果并不好,DBSCAN则可以处理更为复杂的数据集。 1.DBSCAN基本概念 1.核心对象:
4.3 DBSCAN聚类算法(自己写的函数python)
代码如下: import numpy as npimport cv2import timeimport os#聚类算法def cluster(points, radius=100,nums=250):"""points: pointcloudradius: max cluster range"""print("................", len(points))items =