cvpr2021专题

《Learning To Count Everything》CVPR2021
摘要 论文提出了一种新的方法来解决视觉计数问题,即在给定类别中仅有少量标注实例的情况下,对任何类别的对象进行计数。将计数问题视为一个少样本回归任务,并提出了一种新颖的方法,该方法通过查询图像和查询图像中的少量示例对象来预测图像中所有感兴趣对象的存在密度图。此外,还提出了一种新颖的适应策略,使网络能够在测试时仅使用新类别中的少量示例对象来适应任何新的视觉类别。为了支持这一任务,作者还引入了一个包含

CVPR2021-PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Re
作者:Zhang kai + Prof. Noah Snavely Cornell University, Department of Computer Science 光照:natural, static illumination 对象:specular objects 视点:multi-view 相机类型:RGB 时间:no 问题:multi-view inverse render

【CVPR2021】LoFTR:基于Transformers的无探测器的局部特征匹配方法
LoFTR:基于Transformers的局部检测器 0. 摘要 我们提出了一种新的局部图像特征匹配方法。我们建议先在粗略级别建立像素级密集匹配,然后再在精细级别细化良好匹配,而不是按顺序进行图像特征检测、描述和匹配。与使用成本体积搜索对应关系的密集方法相比,我们在 Transformer 中使用自注意力层和交叉注意力层来获得以两个图像为条件的特征描述符。Transformer 提供的全局

CVPR2021-语义分割调研
语义分割调研(2021) 一、 Rethinking BiSeNet For Real-time Semantic Segmentation · Paper: https://arxiv.org/abs/2104.13188 · Code: https://github.com/MichaelFan01/STDC-Seg 文章归类:图像分割,网络结构创新,实时 主体思想: 1、希望利用

【CVPR2021】Dynamic Region-Aware Convolution
论文:https://arxiv.org/pdf/2003.12243.pdf 代码:https://github.com/shallowtoil/DRConv-PyTorch (非官方实现) 这个论文的核心词是:动态网络。作者认为,传统卷积对于不同样本使用相同的 filter,如果能够对不同区域的特征使用不同的卷积核可以显著提升特征表达能力。如下图所示,把图像分割为不同区域,对不同区

CVPR2021 | 国防科大:基于几何稳定性分析的物体位姿估计方法
本文转载自机器之心。 物体6D姿态估计是机器人抓取、虚拟现实等任务中的核心研究问题。近些年来,随着深度学习技术和图像卷积神经网络的快速发展,在提取物体的几何特征方面出现了许多需要改善的问题。国防科技大学的研究人员致力于通过将几何稳定性概念引入物体 6D 姿态估计的方法来解决问题。 物体 6D 姿态估计的目的是确定物体从模型坐标系到相机坐标系的刚性变换矩阵。现有方法通常通过求解观测物体与物体三

论文阅读:CVPR2021 | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
文章目录 1、前言2、Introduction3、Method3.1、Overall ArchitectureSwin Transformer block3.2、Shifted Window based Self-AttentionSelf-attention in non-overlapped windowsShifted window partitioning in successive

【论文阅读-姿态估计】CVPR2021_CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild
本文将介绍一篇基于自监督的3D人体姿态估计方法,作者来自德国汉诺威大学和加拿大英属哥伦比亚大学。 论文链接:https://arxiv.org/abs/2011.14679 代码链接: 尚未公开 主要思想: 本文提出了一个利用多视角2D图像估计3D人体姿态的模型,主要框架如下图所示。 首先将同一姿态不同视角下的图像分别输入两个共享权重的Lifting网络,这部分网络输出为两个分支,一个分支输出

【论文解读】单目3D目标检测 MonoDLE(CVPR2021)
本文分享单目3D目标检测,MonoDLE模型的论文解读,了解它的设计思路,论文核心观点,模型结构,以及效果和性能。 目录 一、MonoDLE简介 二、论文核心观点 三、模型框架 四、模型预测信息与3D框联系 五、损失函数 六、核心内容——3D框中心点偏差分析 七、忽略远距离目标 八、实验对比与模型效果 一、MonoDLE简介 MonoDLE作为一个延续Center

CVPR2021 | 最新CVPR2021论文抢先看,附全部下载链接!
CVPR2021最全1660篇pdf(4.3G) 链接: https://pan.baidu.com/s/1GWkqUOcO6KMOu-uLJrSpbA 提取码: vwkx 持续更新Github: https://github.com/Sophia-11/Awesome-CVPR-Paper 2021持续论文集锦百度云请在【计算机视觉联盟】后台回复 CVPR2021 往年论文

CVPR2021 MotionRNN: A Flexible Model for Video Prediction with Spacetime-Varying Motions
动机 1、现实世界的运动是非常复杂的,总是在空间和时间上变化。在降水预报中,要准确预测随时空变化的运动,如雷达回波的变形、积累或消散,具有极大的挑战性。 2、最新的已知的视频预测模型,如PredRNN、MIM和Conv-TT-LSTM,主要关注于捕捉随时间的变化简单的状态转换。它们忽略了运动中复杂的变化,所以在高度变化的情况下不能准确地预测。 3、基于光流的方法使用局部不变状态转换来捕捉短期

CVPR2021 General Instance Distillation for Object Detection
动机 知识蒸馏是一种有效的模型压缩方法。这种方法可以使轻量级的学生模型从较大的教师模型中获取有效知识。 目标附近的特征区域有相当多的信息,这对于知识蒸馏是有用的。然而,不仅目标附近的特征区域,而且即使是来自背景区域的判别块也有意义的知识。 为了应对检测任务中前景和背景区域的不均衡,之前的蒸馏检测方法都需要精心设计正例与负例之间的比例,并且仅蒸馏与GT相关的区域可能会忽略背景中潜在的信息区域。

CVPR2021 Paper Reading——Inception Convolution with Efficient Dilation Search
动机 1、空洞卷积核的dilation (空洞率)是一个非常有效的超参数,可以调节不同任务之间的有效感受野(ERF)分布。 由于输入图片的尺寸变化以及感兴趣目标的尺寸变化,ERF根据不同任务进行调整是很重要的。即使在相同的任务中,对于一个具体的卷积层ERF的优化也是不同的,不同有效的搜索算法适用于不同的任务。例如,在图像分类中,输入的尺寸往往比较小(例如:224 × 224),而在目标检测中,
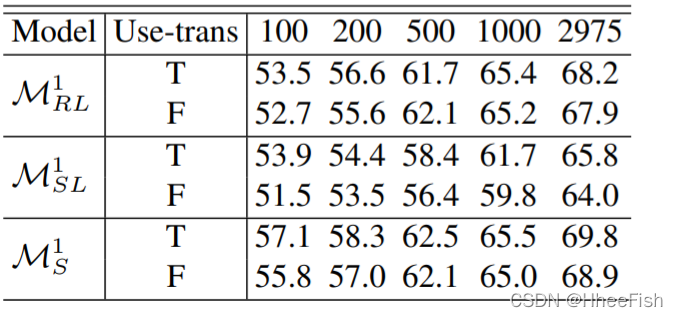
CVPR2021-Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentati
Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation:基于双层领域混合的半监督领域自适应语义分割 0.摘要1.介绍2.相关工作2.1.用于语义分割的无监督域自适应2.2.语义分割的半监督学习。2.3.半监督域自适应 3.方法3.1.问题陈述3.2.领域混合教师
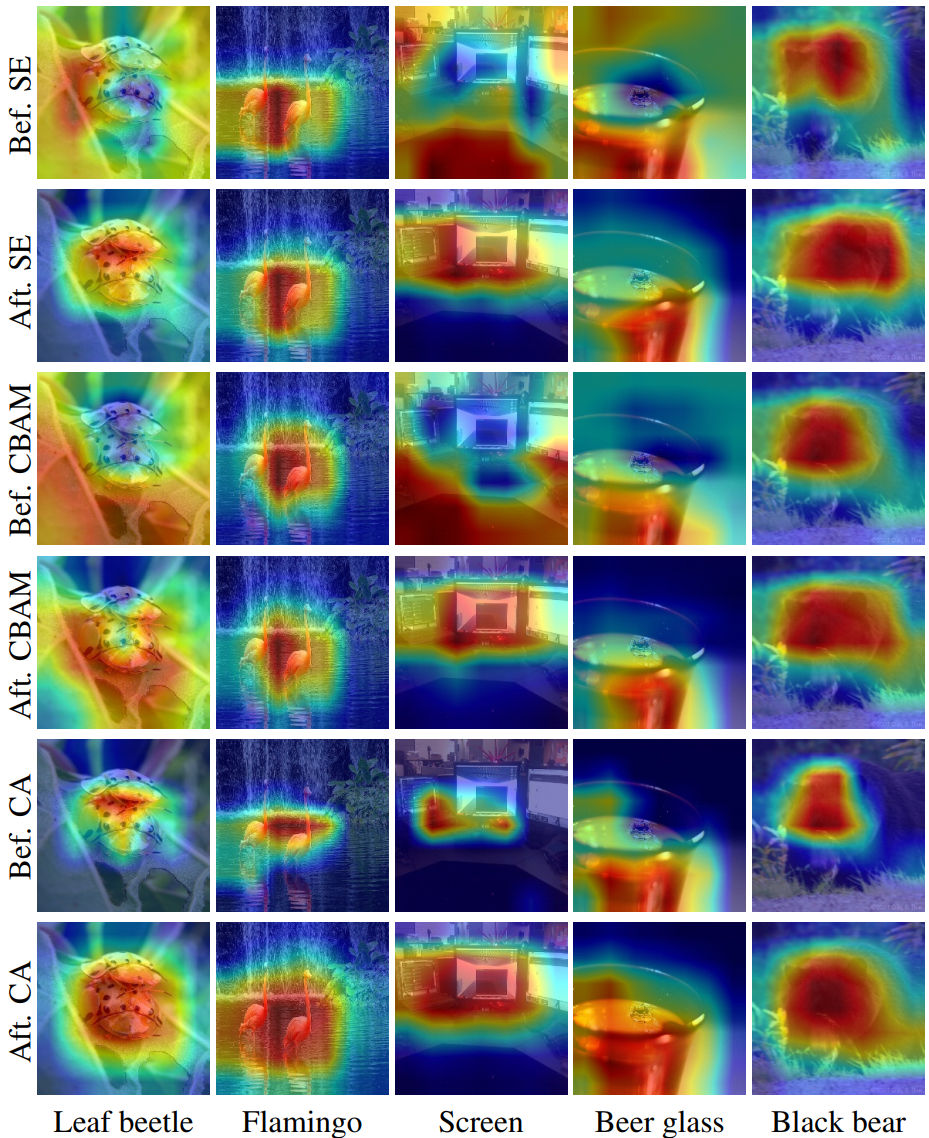
论文解读:Coordinate Attention for Efficient Mobile Network Design(CVPR2021)
论文前言 原理其实很简单,但是论文作者说得很抽象,时间紧的建议直接看3.1中原理简述CBMA、原理简述CBMA以及3.2中原理简述coordinate attention block即可。 Abstract 最近关于mobile network设计的研究已经证明了通道注意(例如,the Squeeze-and-Excitation attention)对于提高模型性能的显着有效性,但

基于无监督退化表示学习的 Blind SR | 环境搭建 | 训练简记【更新补充】|【CVPR2021】
🥇 版权: 本文由【墨理】原创、在CSDN首发、如需转载,请联系博主❤️ 如果文章对你有帮助、感谢三连 接上篇博文,简记训练数据构建 + 代码排除 bug 基于无监督退化表示学习的 Blind SR | 环境搭建 | 测试简记 文章目录 📔 主要参数配置文件分析📕 安排训练--主要参数改动📗 resume 接着某个epoch 的模型继续训练📘 模型训练 刚开始 GP

赛道 | CVPR2021-MMAct挑战赛跨模态动作识别双冠方案解读
日前,计算机视觉和模式识别领域的三大顶级会议之一CVPR正在进行中,深兰DeepBlueAI团队在动作识别国际挑战赛 (ActivityNet) 研讨会上,参加了 MMAct 挑战赛中仅设的两个赛道——“跨模态裁剪动作识别”和“跨模态未裁剪动作时序定位”,并均以大比分领先取得第一。 竞赛要求参赛者提出跨模态视频动作识别/定位方法,以弥补使用 MMAct[1] 数据集的纯视觉方法的缺点。此任务

CA-用于轻型网络的坐标注意力 | CVPR2021
Coordinate Attention for Efficient Mobile Network Design 创新点 为轻型网络提出 CA(Coordinate Attention)注意力机制;CA 注意力通过嵌入位置信息到通道注意力,避免在二维全局池化中位置信息的损失还可以使CA能够捕获长距离的依赖关系。 问题 SE(Squeeze-and-Excitation)注意力在编码过程中忽
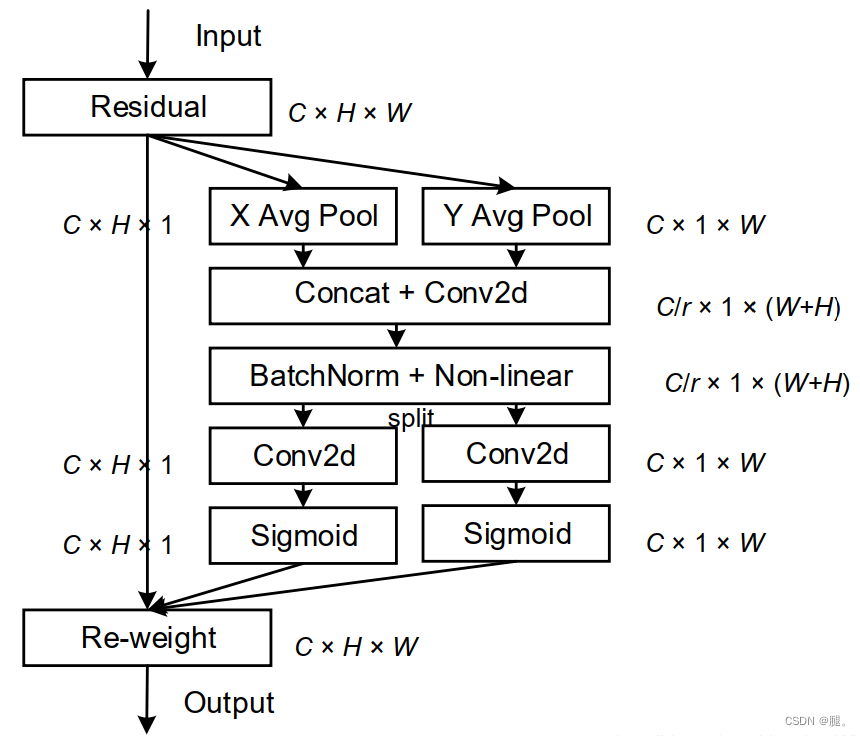
CVPR2021| 继SE,CBAM后的一种新的注意力机制:坐标注意力机制(Coordinate Attention)
一、前言 论文:http://arxiv.org/abs/2103.02907论文:http://arxiv.org/abs/2103.02907 论文:源码:https://github.com/Andrew-Qibin/CoordAttention 在本文中提出了一种新颖且高效的注意力机制,通过嵌入位置信息到通道注意力,从而使移动网络获取更大区域的信息而避免引入大的开销

文献阅读(59)CVPR2021-Swin Transformer-Hierarchical Vision Transformer using Shifted Windows
本文是对《Swin Transformer-Hierarchical Vision Transformer using Shifted Windows》一文的浅显翻译与理解,如有侵权即刻删除。 更多相关文章,请移步: 文献阅读总结:计算机视觉 文章目录 Title总结1 整体框架2 移动窗口 Title 《Swin Transformer-Hierarchical Visi
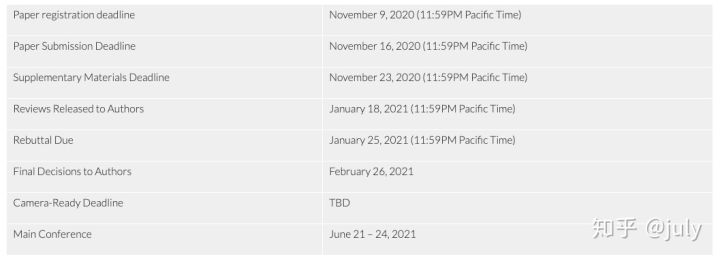
CVPR2021 注册投稿倒计时,开始肝论文吧
9.10 AAAI投稿刚结束,有种似凉非凉的赶脚,为了不浪费稿子,一稿多投可以提上议程了,比如接下来的CVPR、ICCV、IJCAI等等,早点着手总不会错。 CVPR 2021的官网是,http://cvpr2021.thecvf.com,要投的或者感兴趣的,可以先看看了解下。 为了看得方便,这边把投稿流程截图了,图中pacific time是太平洋时间,和北京时间相差16个小时,换成北京时间

(CVPR2021) Video MoCo: Contrastive Video Representation Learning with Temporally Adversarial Example
使用对抗的方法,引入了对于时序robust的正样本,具体方式为使用lstm随机drop掉video clip中的一些帧,同时由于负样本的队列中,越早进入的样本与正样本的差距越大,故给队列中的负样本一个权重系数(小于1),越新的样本权重越大。 损失函数: 生成器: 判别器: 实验结果: 结论:
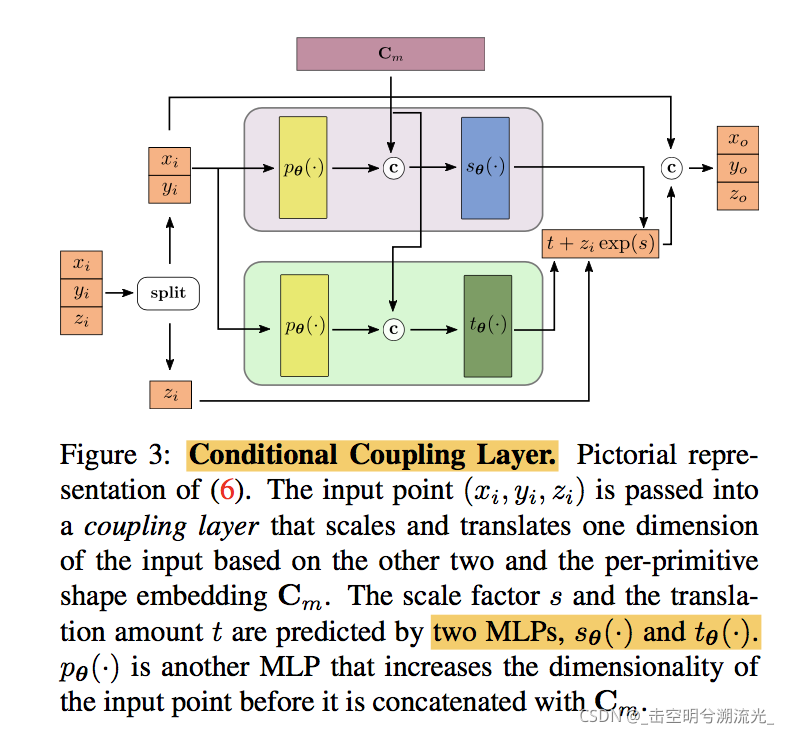
论文笔记:CVPR2021 Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Network
Motivation: recovering the geometry of a 3D shape from a single RGB image 常用的primitive-based representations 寻求推断在不同对象实例之间推断语义一致的part排列,并提供更具解释性的替代方法,而非仅注意提取全局物体。 现存的一些方法由于其简单的参数化,这些原语的表达能力有限无法捕捉复杂

GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields(CVPR2021 Best paper)
目录 1. 简介1.1 参考资料1.2 课题研究背景(个人理解)1.3 文章发展脉络 2. NeRF2.1 解决的问题2.2 解决方法2.2.1 场景表示2.2.2 渲染成图像2.2.3 优化2.2.3.1 位置编码2.2.3.2 分层采样 3. GRAF3.1 简介3.2 方法3.2.1 NeRF相关公式3.2.2 GRAF框架3.2.2.1 ray sampling3.2.2.2 C
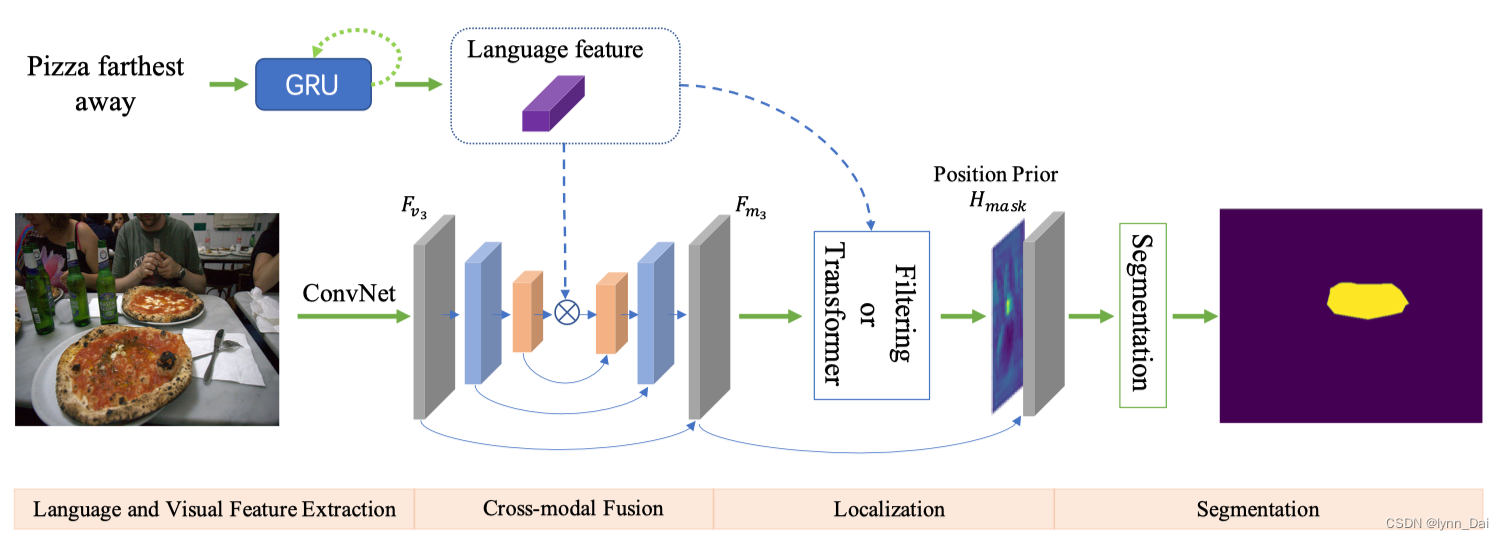
【cvpr2021】Locate then Segment: A Strong Pipeline for Referring Image Segmentation
文章地址:LTS motivation: 以前的方法网络架构和实验实践越来越复杂,使得算法分析和比较变得越来越困难。此外,他们没有明确定位语言表达引导的参考对象,只利用耗时的后处理 DCRF 来生成最终的细化分割。 idea&contribution: 提出一种新的方法,将RIS解耦为两个子序列任务:(a)引用对象位置预测,(b)对象分割掩码生成。 模型首先融合视觉和语言特征以获得跨模态
【cvpr2021】Locate then Segment: A Strong Pipeline for Referring Image Segmentation
文章地址:LTS motivation: 以前的方法网络架构和实验实践越来越复杂,使得算法分析和比较变得越来越困难。此外,他们没有明确定位语言表达引导的参考对象,只利用耗时的后处理 DCRF 来生成最终的细化分割。 idea&contribution: 提出一种新的方法,将RIS解耦为两个子序列任务:(a)引用对象位置预测,(b)对象分割掩码生成。 模型首先融合视觉和语言特征以获得跨模态