本文主要是介绍CVPR2021-Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentati,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation:基于双层领域混合的半监督领域自适应语义分割
- 0.摘要
- 1.介绍
- 2.相关工作
- 2.1.用于语义分割的无监督域自适应
- 2.2.语义分割的半监督学习。
- 2.3.半监督域自适应
- 3.方法
- 3.1.问题陈述
- 3.2.领域混合教师
- 3.2.1.区域层次上的数据混合。
- 3.2.1.Sample-level数据混合。
- 3.3.多教师知识蒸馏
- 3.4.逐步提高策略
- 4.实验
- 4.1.实验设置
- 4.2.应用细节
- 4.3.性能比较
- 5.消融实验
- 5.1.互补性
- 5.2.迭代次数
- 5.3.图像翻译
- 6.结论
- 参考
0.摘要
尽管基于数据驱动的方法在许多任务中取得了巨大成功,但当应用于看不见的图像域时,泛化能力较差,并且需要昂贵的注释成本,尤其是对于语义分割等密集像素预测任务。近年来,为了缓解这一问题,人们对大量合成数据的无监督领域自适应(UDA)和小样本标记数据的半监督学习(SSL)进行了研究。然而,与受监管的同行相比,他们的绩效仍有很大差距。我们将重点放在半监督域适配(SSDA)的一个更实际的设置上,其中既有少量的标记目标数据,也有大量的标记源数据。为了解决SSDA的任务,提出了一种基于双层域混合的新框架。拟议的框架包括三个阶段。首先,提出了两种数据混合方法,分别在区域级和样本级减小域间距。基于两个层次的混合数据,我们可以分别从整体和局部的角度获得两个互补的领域混合教师。然后,通过从这两位老师那里提取知识来学习一个学生模型。最后,以自我培训的方式生成未标记数据的伪标签,用于另外几轮教师培训。大量的实验结果证明了我们提出的框架在合成到真实语义切分基准上的有效性。
1.介绍
在过去几年中,深度卷积神经网络(CNN)在语义分割方面取得了巨大的进步[1,25,17,26,2,49]。基于CNN的方法的成功得益于大量手动标记的数据[24,8],以及训练样本和测试样本之间独立且相同的数据分布假设。 然而,当在训练集(源域)上训练的模型直接应用于看不见的测试场景(目标域)时,性能会显著下降。此外,在目标域中密集地注释多个样本的像素级标签既耗时又不经济。
为了减少对像素注释的大量需求,一种方法是使用大量易于获取的模拟数据,这些数据可以从GTA5[33]和SYNTHIA[34]等游戏引擎中收集。此外,无监督领域适应(UDA)策略旨在将知识从合成标签丰富的源领域转移到现实世界标签稀缺的目标领域,需要弥合合成和现实世界领域之间的领域鸿沟。UDA方法通过熵最小化[31,43]、生成建模[16,12]和对抗性学习[42,41]来提取域不变表示,取得了令人印象深刻的结果。然而,由于对目标实例的监督不力,这些方法无法完全消除域转移。与监督方法相比,在性能上仍有很大差距。解决重标注问题的另一种方法是仅标注目标域中的一小部分图像,并使用半监督学习(SSL)技术充分利用大量未标记数据[10,30,9,29]。 由于SSL设置中缺少标记数据,因此获得的模型有过度拟合少量标记数据的风险。如何有效地利用来自不同领域的可用未标记和有限标记数据,是提高像素级预测任务模型精度和泛化能力的关键。
因此,最近引入了一个更实用的半监督域自适应(SSDA)任务,它将SSL中的一小组标记目标数据图像与大量标记源域数据和未标记目标域数据相结合。为了解决SSDA问题,一种简单的方法是在额外标记的目标图像上为UDA方法配备额外的监控(见表1中的基线)。例如,提出了缓解语义水平转移(ASS)模型[44],通过对两个标记域的输出使用对抗性学习,更好地促进特征的分布一致性。然而,这些方法无法充分挖掘两个领域中可用的标记和未标记数据中的丰富信息。
语义分割是一项密集的像素预测任务,对一个像素的分类不仅取决于其本身的值,还取决于其邻域的上下文。我们专注于如何有效地利用不同领域的标记数据提取区域级和样本级的域不变表示。拟议的框架包括三个步骤。
- 首先,提出了两种数据混合方法,以减少区域级和样本级的数据差异;区域级数据混合是通过对两个域的标记图像应用两个掩码,并将两个掩码区域相结合来实现的,从而鼓励模型从局部视图中提取语义结构的域不变特征。图像级数据混合直接从整体角度将两个域的标记图像混合。
这两种混合的方式有助于培养两种互补的教师模式,这两种模式都适用于两种数据分布。 - 第二步,我们采用知识蒸馏技术从这两位互补的教师中提取“暗知识”,作为目标领域学生模型学习过程的指导。
通过整合两种观点的知识,并充分利用未标记数据,相同网络结构的学生模型甚至可以比任何教师的性能更好。一旦获得目标域的好学生模型,就可以通过自训练策略生成伪标签,对已标记的目标域数据集进行扩展,进行迭代更新。与直接使用伪标签训练最终模型的传统自我训练方法相比,我们利用这些伪标签获得了两个更强的领域混合教师,这也使得学生通过新一轮的知识提炼变得更强。
总的来说,在我们的框架中,教师和学生都在逐步成长,我们可以得到一个最终训练有素的学生模型。
本文的贡献有三个方面:
- 提出了两种数据混合方法,对跨领域混合教师进行区域级和样本级的培训,以缓解不同领域间数据分布不匹配的问题。
- 在目标域上更强大的学生模型从互补领域的混合教师中提取知识。它可以通过使用伪标签来进一步增强,伪标签是以自训练的方式为未标记的目标数据生成的
- 大量实验表明,该方法在两种常见的合成到真实语义分割基准测试中都能取得优异的性能。
2.相关工作
2.1.用于语义分割的无监督域自适应
为了解决真实感合成数据集和未标记真实数据集之间的领域差异,无监督领域自适应(UDA)语义分割方法得到了广泛的研究。一种主流方法是通过对抗性学习[42,41,6,5,17,37,19],其目的是使用鉴别器来测量两个领域的差异。解决UDA问题的另一种方法是利用生成网络[38,16,50],通过在注释源图像上应用样式转换技术来生成目标样式图像。一些基于自我训练的方法[21,51,23,14]已被用于生成未标记数据的伪标签,并使用它们微调模型。[21]首先生成不同风格的注释图像,学习纹理不变表示,然后使用自训练生成未标记数据的伪标签,在目标域上微调模型。
虽然UDA在语义分割方面取得了令人印象深刻的成果,但由于目标领域缺乏强有力的监督,领域差距无法完全缓解,而且与受监督的领域相比,仍然存在明显的性能差距。
2.2.语义分割的半监督学习。
减少手动像素级标记需求的一种方法是只标记目标分布中的少量数据,并采用半监督学习(SSL)策略在大量未标记和有限标记数据中学习一个伟大的广义模型。此后,人们开发了许多方法来改进模型的泛化[30,20,9,29,18,4,13]。一致性正则化是最流行的方法之一,其关键思想是鼓励网络对扰动的未标记输入给出一致的预测。一项最相关的工作是[10],它通过一个具有师生体系结构的区域级数据增强CutMix[47]来加强教师网络的混合输出和学生对混合输入的预测之间的一致性[40]。我们的方法与他们的方法也有相似的理念,但是,我们建议用两种领域混合方法来训练两个领域混合的教师,以充分利用来自两个不同领域的两组数据。
2.3.半监督域自适应
与UDA相比,还旨在减少数据分布不匹配,半监督领域自适应(SSDA)通过引入部分标记的目标样本来弥合领域差异。
最近,基于深度学习[46,32,22,35]的一些图像分类方法被提出。[46]将SSDA分解为两个子问题:UDA和SSL,并采用联合训练[3]在两个分类器之间交换专业知识,这两个分类器在每个视图的标记和未标记数据之间混合[48]数据进行训练。
由于语义分割中的复杂密集像素预测和示例之间没有明确的决策边界,基于区分类边界的SSDA图像分类方法不能直接应用于语义分割。之前的一项工作是研究SSDA的语义分割。Wang等人[44]提出了缓解语义水平转移(ASS)框架,从全局和语义层面实现跨领域的特征对齐。ASS引入了一个额外的语义级自适应模块,通过对源和目标标记输入的相应输出进行对抗性训练,并在经典的AdapteSeg框架下对额外的少量标记目标数据进行额外监督[41]。然而,对标记的目标样本进行简单的监督并不能充分利用标记的两个域,而且由于监督能力较弱,对抗性损失使得训练不稳定。为了解决这个问题,我们提出了一种新的基于双层域混合方法的迭代框架,无需任何对抗性训练。
3.方法
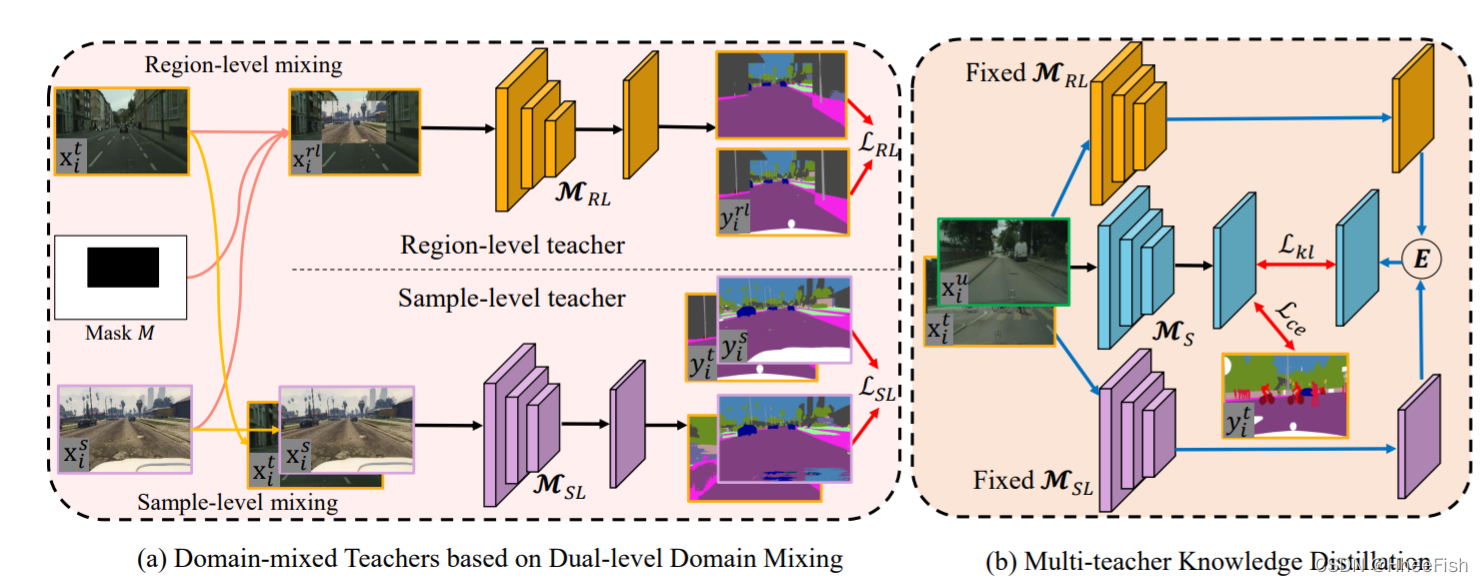
图1所示。提出的SSDA框架的前两个阶段,领域混合教师的培训和多教师知识的提炼。
基于双层混合数据对领域混合教师进行培训。然后使用这两个领域混合的教师来培养一个好学生。学生将为下一轮教师培训生成伪标签。E表示两个领域混合教师的集合操作。黑色箭头表示训练数据流,蓝色箭头表示推理数据流,它们不需要向后流动。红色箭头表示损失的计算。
3.1.问题陈述
在半监督领域自适应问题中,少量目标域的标记影像被提供,设DS={(xsi,ysi)}NS i=1表示NS标记的源域样本,DT={(xt i,yt i)}NT i=1表示NT标记的目标域样本,DU={xu i}NUi=1表示NU未标记的目标域样本。在SSDA设置下,我们的目标是开发一种有效利用可用DS、DT和DU的方法,并获得一种分割模型,该模型对从目标数据分布中采集的未知测试数据具有良好的性能。
3.2.领域混合教师
性能下降源于不同域中不一致的数据分布。我们提出了两种数据混合方法,一种是区域级数据混合,另一种是样本级数据混合,从两个角度缩小数据分布差距。众所周知,带有标记的地面真相的数据为在基于深度学习的方法中训练一个模型提供了大量信息。在SSDA中,提供了两种类型的标记数据,即DS和DT。我们在这两类标记数据上实现了区域级和样本级的数据混合方法,并且可以在混合数据上训练两个领域混合教师模型。由于对数据不同角度的信息进行混合法,这两个领域混合的教师是互补的。
3.2.1.区域层次上的数据混合。
语义分割是一项密集的像素预测任务,一个像素的分类不仅取决于其本身的值,还取决于其所在区域的上下文。因此,当一幅图像同时包含源域和目标域内容时,模型可以学习域不变表示,因为在模型训练过程中可以同时看到不同特征分布的不同区域。
CutMix[47]将一幅图像中的patch剪切粘贴到另一幅图像上,以增强数据,提高模型的泛化能力,受此启发,我们提出在集合DS和DT上进行区域级数据混合,以减少域间的差距。
给定两个标记图像{xt, yt}, {xs, ys},区域级混合操作可描述为:
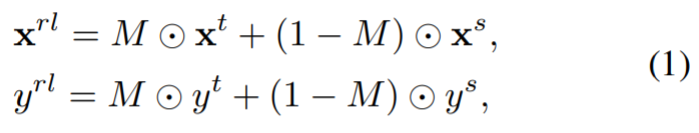
其中M表示二进制掩码,表示需要融合的区域,⊙是逐元素乘法。
如图1所示,混合图像xrl同时包含xs和xt的内容,根据包含该像素的区域来自哪个域,得到每个像素对应的混合标签yrl。
即根据随机选择的坐标从xs中裁剪出一个矩形区域,然后粘贴到xt的相同位置上。区域级数据混合能够在不同的域之间产生中间样本,这就像一座桥梁,填补了域之间的空白。这有助于从局部视图探索跨不同领域的基本语义上下文。此外,该操作可以破坏原目标图像的固有结构,使区域级教师的培训过程规范化。一旦混合图像及其标签准备好,我们可以通过对混合数据的监督训练来训练语义分割模型。
训练目标函数可以写成: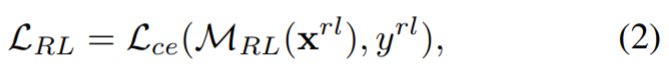
其中MRL表示在地区级混合数据上训练的教师模型,Lce表示交叉熵损失。
3.2.1.Sample-level数据混合。
样本级数据混合的目的是从整体的角度来混合不同领域的数据。源和目标样本是在分布不一致且相差较大的情况下采样的。我们发现,这些数据的直接混合已经在一定程度上有助于缩小不同领域之间的差距。
样本级数据混合方法有两个优点。
- 一方面,大量源图像的引入缓解了模型对少量目标图像的过拟合。
- 另一方面,样本级混合有助于从整体角度探索不同领域之间的中间决策边界。
在我们的实验中,我们从源集DS和目标集DT中随机抽取两个样本,然后在一次迭代中直接将它们输入模型。给定DS和DT两幅图像,样本级教师的训练目标函数定义如下:
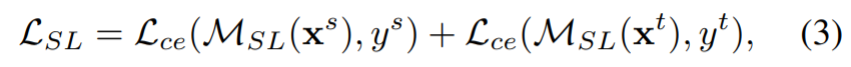
其中MSL表示在样本级混合数据上训练的教师模型。
3.3.多教师知识蒸馏
在获得两名受过培训的领域混合教师后,我们采用知识蒸馏(KD)技术,通过最小化两个模型输出之间的KL-divergence来提取知识。在这里,我们将其用于从这两位互补的教师中提取“黑暗知识”。多教师KD的流水线如图1 (b)所示,其中包括2名经过培训的混合领域教师和1名与教师具有相同网络架构的学生。两名教师的输出被集成为一个更强的指导,以监督学生模型在无标签目标数据的训练。此外,对于少量已标注的目标数据,学生模型还受到标注的监督。
学习学生MS的目标函数定义如下:
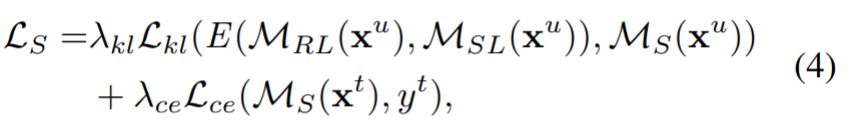
式中,λkl和λce分别为kl发散损失和交叉熵损失的权值,E为两个模型的集合运算。在实验中,通过平均两名互补教师的输出来实现集成操作。
通过整合两种观点的知识,充分利用未标记的数据,我们可以得到一个学生,甚至比任何一个老师的表现都要好。
3.4.逐步提高策略
通常,教师网络比学生网络具有更强的能力。然而,在这里,一个好的学生模型是通过从两个互补的领域混合模型的集合输出中提取知识获得的,这些模型包含大量的未标记数据。我们关注如何在下一步使用学生网络来进一步提高教师的表现
近年来,自训练作为一种简单而有效的方法来解决训练数据缺乏标注的问题,并被广泛应用于SSL和UDA等图像分类任务中。在我们的任务中,我们获得的教师只是基于标记的源数据和少量标记的目标数据进行培训。在自我训练成功的激励下,我们相信教师可以通过这种策略得到进一步的提高。在[23]之后,通过learned student模型生成DU的伪标签,更新DT数据集中已标记的图像集,用于下一轮混合领域教师培训。一旦获得了更强的领域混合教师,就可以通过另一轮多教师KD获得一个更强的学生。
总的来说,我们框架的整个训练过程是迭代的。混合领域的教师和学生都在逐步成长,即他们可以通过知识的升华和自我训练策略来帮助彼此学习。我们在算法1中总结了我们提出的算法。
所提出方法的训练框架如下:

4.实验
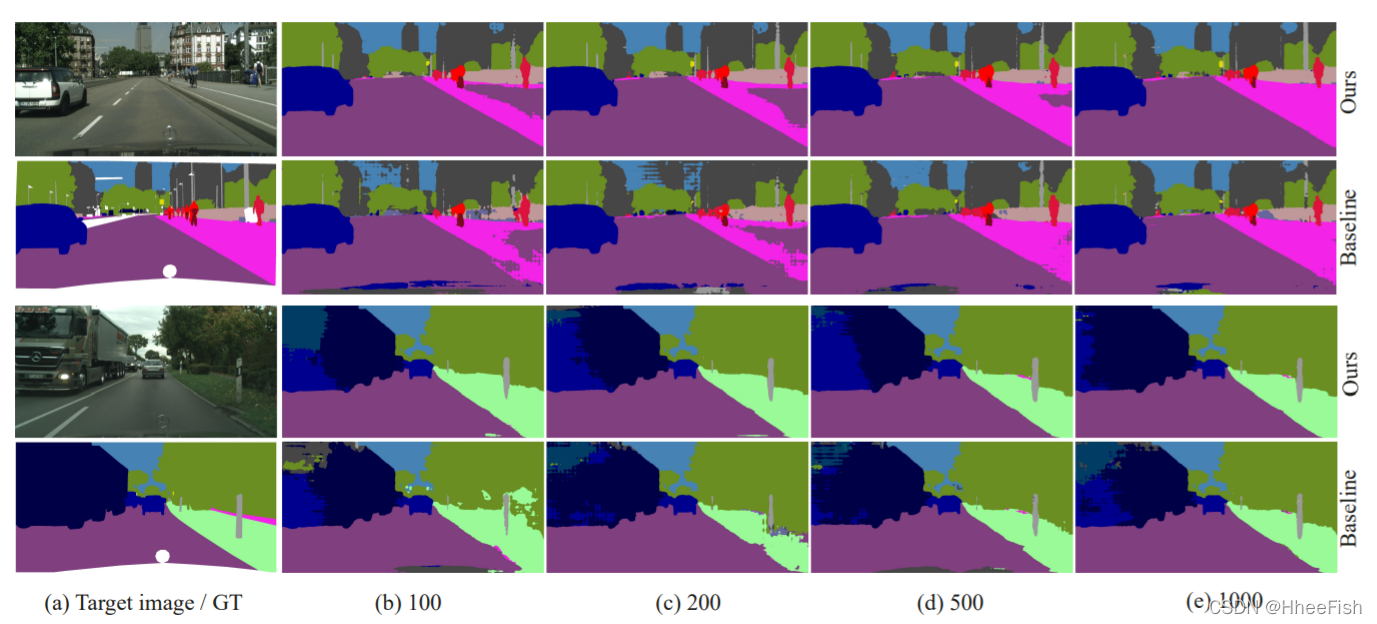
图2我们的方法和基线方法的定性结果不同数量的标记目标图像在GTA5城市景观。
(a)目标图像与对应的ground truth (GT), (b)-(e)标记不同数量目标图像的分割结果。
4.1.实验设置
在语义分割中设置无监督域自适应方法之后,我们还进行了广泛的实验,并在两个常用的合成到真实基准上报告了平均交并比(mIoU)得分,这两个基准分别是GTA5[33]和SYNTHIA[34]到cityscape[7]。
cityscape是一个从真实世界中50个城市采集的自动驾驶数据集。它包含了2,975和500张带有密集注释的图像,固定分辨率为2048×1024,分别用于训练和验证。所有图像都被手工标记为19个语义类别。对于SSDA设置,我们从整个训练集中随机选取不同数量的图像,如(100,200,500,1000),以证明我们的方法在不同设置下的有效性。验证集用于评估我们方法的性能。
GTA5是从游戏视频中收集图像,并通过计算机图形技术自动生成相应语义标签的合成数据集。它包含24,966张合成图像,像素级标签为33个类别。在实验中,我们使用cityscape数据集考虑了19个常见类来训练我们的模型。
SYNTHIA也是一个合成数据集,我们使用SYNTHIA- rand - cityscape作为另一个标记的源域,它包含9,400张完整注释的合成图像,分辨率为1280×960。它有16个常见的类别与城市景观数据集。我们用普通的共有的类训练模型,并在验证集上给出13类mIoU
4.2.应用细节
在接下来的所有实验中,我们使用了一个类似于[42]的DeeplabV2[1]模型,该模型包含Atrous Spatial Pyramid Pooling (ASPP)模块来提取多尺度表示,并利用预先训练的ResNet-101[15]在ImageNet上作为主干,作为我们的语义分割架构。为了训练我们提出的框架,我们使用Pytorch深度学习工具箱来实现它。所有的实验都是在一台拥有32GB内存的特斯拉V100 GPU上进行的,以快速计算。
在训练模型之前,可选的一个操作是对源域图像进行简单的图像平移,以减小源域和目标域的视觉差异。将图像转换为LAB颜色空间,并对目标域进行统计匹配。除另有说明外,大多数实验在开始时都采用图像平移。然后对目标样式标记的源数据和目标数据进行样本级和区域级数据混合;然后,我们在有监督的数据上用交叉熵损失训练领域混合教师。在交叉熵和KL损失条件下,分别对有标记和无标记的目标数据建立学生模型。式4中的权值λkl、λce分别设为0.5、1。对于自训练,选择的伪标签部分和置信阈值分别设置为0.5和0.9,类似于[23]。对于GTA5→cityscape和SYNTHIA→cityscape,迭代回合R分别设置为4和3。所有模型都由随机梯度下降(SGD)优化器训练,初始学习率2.5×10−4,动量0.9,权值衰减10−4,如[42]所述。学习速率随时间的增加而降低,0.9次幂多项式退火程序。
4.3.性能比较
我们提出的方法是在两个常见的从合成到真实的GTA5到cityscape和SYNTHIA到cityscape基准上进行的,以证明所提出的框架的有效性。在UDA、SSL和SSDA设置上,将性能与基线方法和现有的最先进的方法进行了比较。在补充材料中可以看到更广泛的实验
基线:与UDA设置相比,SSDA通过引入额外的少量标记目标数据来缓解域转移问题。
正如在第1节中提到的,解决SSDA问题的一种简单方法是对UDA方法添加额外的监督。
因此,本文采用经典的UDA方法AdaptSeg[41],这是一种多级自适应方法,对多级输出进行对抗学习,对有限标记的目标图像进行额外的监督交叉熵损失作为我们的基线模型。
GTA5到cityscape:《GTA5》与《cityscape》中几种最先进的方法的性能比较如表1所示。实验中,将迭代轮R设为4。经过迭代训练,与现有方法相比,在UDA、SSL和SSDA设置下,我们的方法在不同比例标记的目标域图像上取得了最好的性能。与AdaptSeg、Advent[42]、LTI[21]、PIT[27]等UDA方法相比,我们的方法只需标记100张目标图像,就可以获得10%以上的性能提高,与oracle模型相比,性能差距明显缩小。特别是,我们的方法比分别使用相关CutMix技术和自训练技术的SSL方法CutMix[10]和DST-CBC[9]的性能提高了很多。我们所知的as[44]是SSDA用于语义分割的第一个研究成果,它对标记的源图像和目标图像的输出都采用了额外的语义级自适应,以缓解语义级的偏移,但需要额外的监督。我们将SSDA设置中用于处理图像分类的MME[36]修改为语义分割任务,得到了较差的结果。我们认为这是因为SSDA的分类方法没有考虑图像中的语义上下文,不能直接应用于分割任务。所提出的方法在所有标记数据的比例上都获得了较好的结果。其原因是对抗学习的监督能力较弱,我们可以充分利用现有的标记数据,通过双层数据混合的方式来减少领域差距。此外,我们的方法在2975张图像上也表现良好,性能达到69.8%。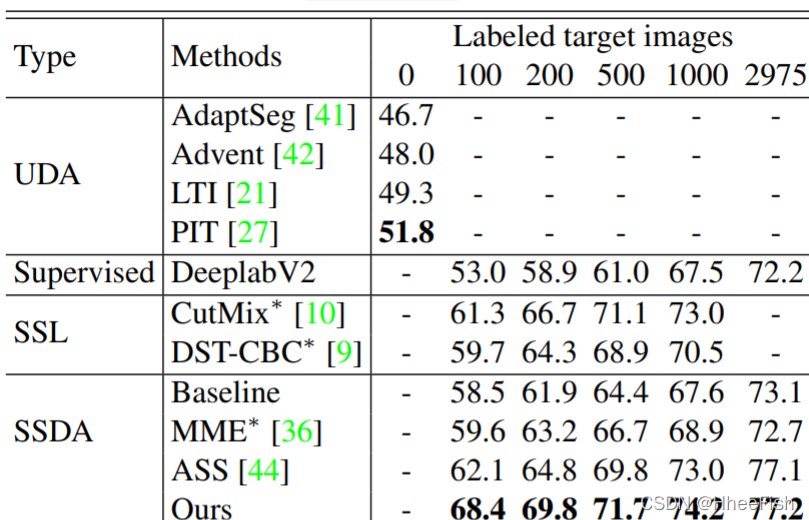
与先进的UDA、SSL和SSDA方法在SYNTHIA→城市景观上的语义分割性能进行了比较。
在本文中,我们对DeeplabV2模型进行了16个等级的训练,并报告了13个等级的mIoU(%)得分。其他设置与表1相同。最好的结果被突出显示。
如表二,我们在100、200、500和1000幅标记的目标图像上的图像分割实验,得到结果。总的来说,在标记图像比例相同的情况下,我们的方法比基线模型获得了更完整的分割结果。随着标记图像数量的增加,我们所提出的方法可以得到更精细的分割结果。
SYNTHIA到cityscape:为了进一步测量我们的方法的性能,我们还将结果与SYNTHIA上的几种最先进的方法和城市景观进行了比较。由于SYNTHIA和cityscape之间只有16个共同类别,所以我们只使用这些共同类别训练一个分割模型。如表2所示,在前人UDA方法的基础上[42,41],我们还报告了13级mIoU得分,与现有的其他方法进行比较。从结果来看,我们的方法明显优于UDA、SSL和SSDA方法,具有较大的性能增益。我们也可以在GTA5 to cityscape中进行类似的讨论。
5.消融实验
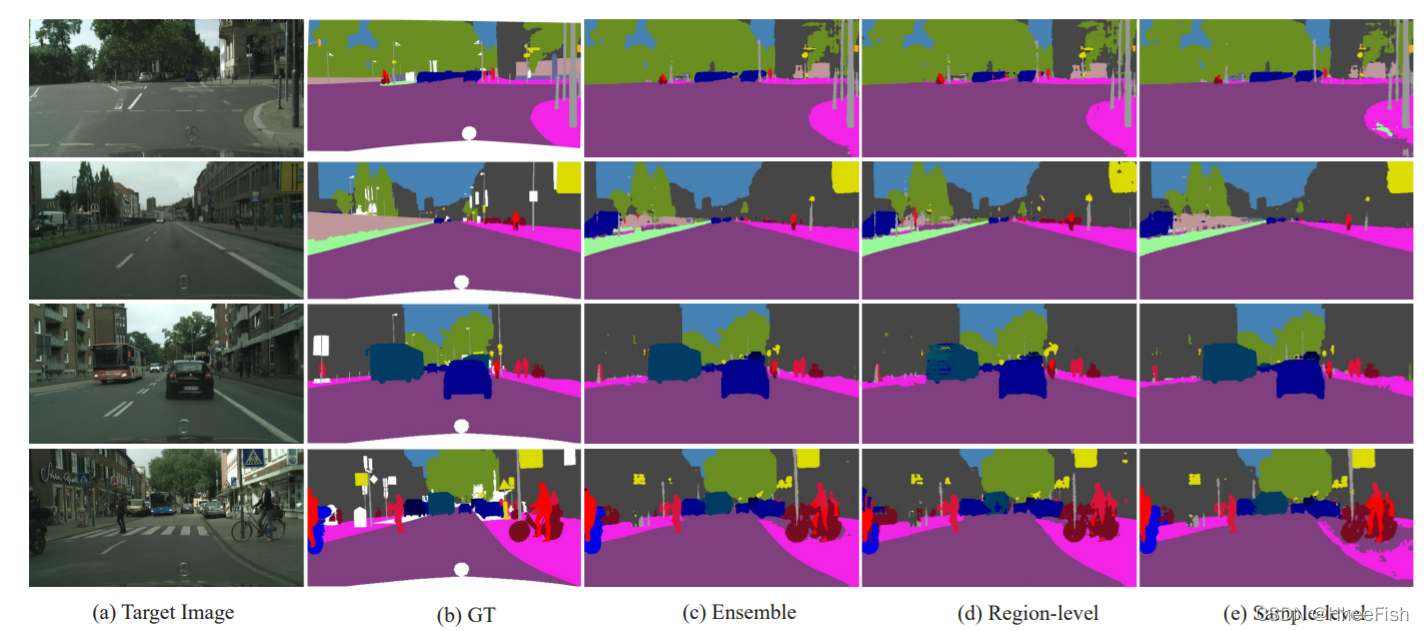
图3。从GT5到Cityscapes的区域级和样本级视图,整体模型的定性结果。
(a)目标图像,(b) ground truth, ©不同视图的模型集成分割结果,(d)区域级混合数据训练的模型结果,(e)样本级混合数据训练的模型结果。
5.1.互补性
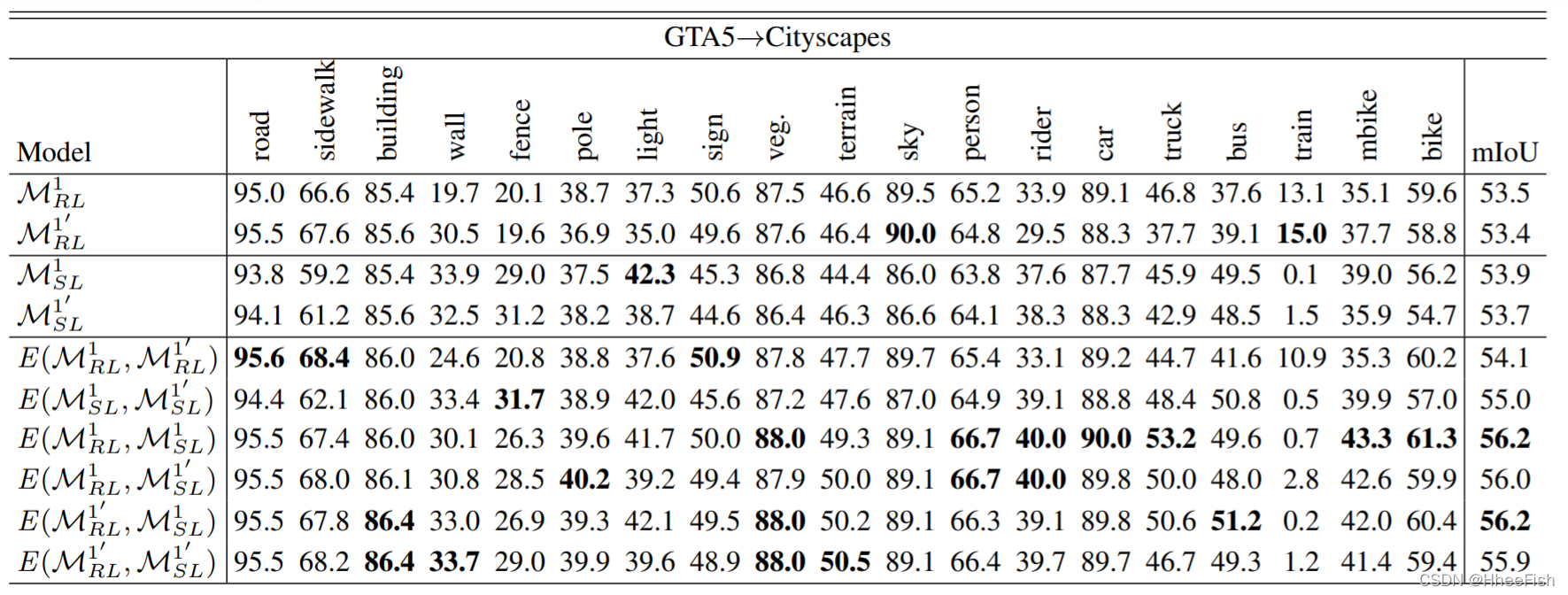
从单个视图和不一致视图对集合模型进行性能比较,以分类iou和mIoU(%)表示。M1 0 RL意味着第一轮M1 RL的重复运行。最好的结果被突出显示。
为了检验从不同视角训练的模型的互补性,我们选择100幅标记的目标图像,分别从样本级和区域级混合数据对领域混合教师进行两次训练。然后对2名区域级教师和2名样本级教师进行不同模型的集成,结果如表3所示。综上所述,从表3中我们可以得出结论,模型集成对提高性能是有效的,从双层数据混合视图集成的模型比从单层数据混合视图集成的模型效果更好。区域级教师在道路、人行道、植被、天空等不需要严格依赖结构信息就可以预测的类别中表现较好。然而,他们对形状独特的围栏、灯光和公交车等级的预测却很糟糕。我们解释了区域级数据混合操作可能会破坏这些类的结构。虽然单一视图下的模型集成可以在自身优势类目上实现令人印象深刻的效果,但性能较差的类目仍表现不佳。例如,来自两个区域级别模型的集成模型在道路和人行道级别上获得了最好的IoU分数,在骑手和围栏级别上获得了最差的结果。这种“最好”和“最差”的现象也出现在样本级教师的整体模式中,但与区域级教师的类别不同。因此,我们可以将具有不同互补层次的模型进行融合,在所有类别中都能取得良好的效果。
我们还将一些不同级别模型集成的分割结果如图3所示。从图3中可以看出,在一个视图中分类错误的像素会在另一个视图中进行校正。
5.2.迭代次数

在GTA5→citylandscapes的整个培训过程中,不同回合的教师与学生模型领域混合的详细结果。对于2975标记的图像,我们的框架经过一轮恰当的训练。
在GTA5到cityscape的整个培训过程中,我们在不同的回合中讨论了表1中报告的结果,三种模型,领域混合的教师和学生的详细结果如表4所示。在训练过程中,这三种模型都可以得到改进,与第一轮相比都有明显的性能提高。在不同的轮次中,学生模型的表现会优于两名教师,表现较强的学生会通过生成更准确的伪标签来纠正教师的学习,从而使教师和学生进步成长。这证明了我们所提出的迭代框架的有效性。我们注意到,最佳模型是在不同的轮对不同数量的标签图像实现的。
5.3.图像翻译
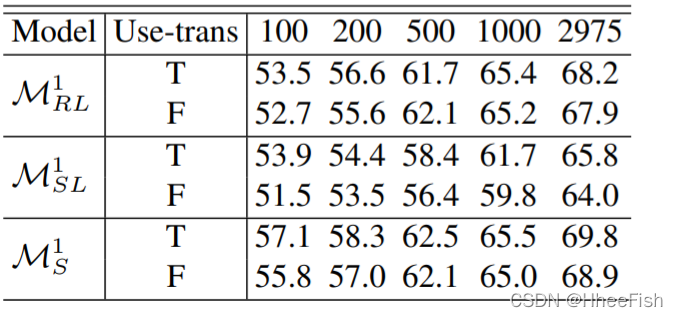
在我们的框架中,两名领域混合的教师和学生在第一轮实验中,无论是否在不同数量的标记目标图像上使用风格迁移的结果
在上述实验中,首先在LAB颜色空间中采用了一种简单的图像平移方法,进一步减小了不同域图像之间的视觉差异。另外,在没有风格转移的情况下,我们也进行了实验来验证我们的方法的有效性。我们只是在第一轮框架中比较了双域混合教师和学生模型的结果。
从表5中,我们可以得出以下三个观察结果。首先,使用风格迁移的学生模型比不使用风格迁移的学生模型有更好的性能。因此,双级数据混合和样式转换可以进一步减少跨域的分布不匹配。其次,区域级混合数据训练的教师模型随着图像数量的增加而变得不敏感。在500幅标配的目标图像上,无样式转换的效果优于使用样式转换的效果。我们认为,这是因为区域级的数据混合对于是否在从源图像中裁剪的一个patch中进行样式转换相对健壮。由于在样本级数据混合方面的显著改进,我们也可以通过样式转换获得更好的结果。最后,在100、200、500、1000张标签图像上,即使没有样式转换,我们提出的框架也能获得比ASS更好的结果。
6.结论
本文提出了一种基于双层域混合的结构来解决半监督域自适应问题。在区域级和样本级两种数据混合方法的基础上,可以得到两种互补的领域混合教师。然后,一个更强的目标领域的学生模型可以通过提取这两个领域混合教师的知识。最后,通过自我培训的方式生成伪标签,对混合领域教师进行下一轮培训。大量的实验表明,所提出的框架能够充分利用现有的数据,并在两个常用的合成到真实的基准测试上取得优异的性能。
参考
[1] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017. 1, 5
[2] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018. 1
[3] Minmin Chen, Kilian Q Weinberger, and John Blitzer. Cotraining for domain adaptation. In Advances in neural information processing systems, pages 2456–2464, 2011. 3
[4] Shuai Chen, Gerda Bortsova, Antonio Garc´ıa-Uceda Juarez, ´ Gijs van Tulder, and Marleen de Bruijne. Multi-task attention-based semi-supervised learning for medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 457–465. Springer, 2019. 2
[5] Yuhua Chen, Wen Li, and Luc Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7892–7901, 2018. 2
[6] Yi-Hsin Chen, Wei-Yu Chen, Yu-Ting Chen, Bo-Cheng Tsai, Yu-Chiang Frank Wang, and Min Sun. No more discrimination: Cross city adaptation of road scene segmenters. In Proceedings of the IEEE International Conference on Computer Vision, pages 1992–2001, 2017. 2
[7] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 5, 11
[8] Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111(1):98–136, 2015. 1
[9] Zhengyang Feng, Qianyu Zhou, Guangliang Cheng, Xin Tan, Jianping Shi, and Lizhuang Ma. Semi-supervised semantic segmentation via dynamic self-training and classbalanced curriculum. arXiv preprint arXiv:2004.08514, 2020. 1, 2, 5, 6, 11
[10] Geoff French, Timo Aila, Samuli Laine, Michal Mackiewicz, and Graham Finlayson. Semi-supervised semantic segmentation needs strong, high-dimensional perturbations. arXiv preprint arXiv:1906.01916, 2019. 1, 2, 5, 6, 11
[11] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361. IEEE, 2012. 1
[12] Rui Gong, Wen Li, Yuhua Chen, and Luc Van Gool. Dlow: Domain flow for adaptation and generalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2477–2486, 2019. 1
[13] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in neural information processing systems, pages 529–536, 2005. 2
[14] Jianzhong He, Xu Jia, Shuaijun Chen, and Jianzhuang Liu.
Multi-source domain adaptation with collaborative learning for semantic segmentation. In Proceedings of the IEEE international conference on computer vision, 2021. 2
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5
[16] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell.Cycada: Cycle-consistent adversarial domain adaptation. In International conference on machine learning, pages 1989– 1998. PMLR, 2018. 1, 2
[17] Judy Hoffman, Dequan Wang, Fisher Yu, and Trevor Darrell.
Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 1, 2
[18] Wei-Chih Hung, Yi-Hsuan Tsai, Yan-Ting Liou, Yen-Yu Lin, and Ming-Hsuan Yang. Adversarial learning for semi-supervised semantic segmentation. arXiv preprint arXiv:1802.07934, 2018. 2
[19] Takashi Isobe, Xu Jia, Shuaijun Chen, Jianzhong He, Yongjie Shi, Jianzhuang Liu, Shengjin Wang, and Huchuan Lu. Multi-target domain adaptation with collaborative consistency learning. In Proceedings of the IEEE international conference on computer vision, 2021. 2
[20] Hoel Kervadec, Jose Dolz, Eric Granger, and Ismail Ben ´ Ayed. Curriculum semi-supervised segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 568–576. Springer, 2019. 2
[21] Myeongjin Kim and Hyeran Byun. Learning texture invariant representation for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12975– 12984, 2020. 2, 5, 6
[22] Taekyung Kim and Changick Kim. Attract, perturb, and explore: Learning a feature alignment network for semi-supervised domain adaptation. arXiv preprint arXiv:2007.09375, 2020. 3
[23] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6936–6945, 2019. 2, 4, 5
[24] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755.
Springer, 2014. 1
[25] Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen-Change Loy, and Xiaoou Tang. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE international conference on computer vision, pages 1377–1385, 2015. 1
[26] Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek, and Yann LeCun. Predicting deeper into the future 9 of semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 648–657, 2017. 1
[27] Fengmao Lv, Tao Liang, Xiang Chen, and Guosheng Lin.
Cross-domain semantic segmentation via domain-invariant interactive relation transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4334–4343, 2020. 5, 6
[28] Andres Milioto, Philipp Lottes, and Cyrill Stachniss. Realtime semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in cnns.
In 2018 IEEE international conference on robotics and automation (ICRA), pages 2229–2235. IEEE, 2018. 1
[29] Sudhanshu Mittal, Maxim Tatarchenko, and Thomas Brox.
Semi-supervised semantic segmentation with high-and lowlevel consistency. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. 1, 2
[30] Yassine Ouali, Celine Hudelot, and Myriam Tami. Semi- ´ supervised semantic segmentation with cross-consistency training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12674– 12684, 2020. 1, 2
[31] Fei Pan, Inkyu Shin, Francois Rameau, Seokju Lee, and In So Kweon. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3764–3773, 2020. 1
[32] Can Qin, Lichen Wang, Qianqian Ma, Yu Yin, Huan Wang, and Yun Fu. Opposite structure learning for semi-supervised domain adaptation. arXiv preprint arXiv:2002.02545, 2020.
[33] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In European conference on computer vision, pages 102–118. Springer, 2016. 1, 5, 11
[34] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3234–3243, 2016. 1, 5
[35] Danila Rukhovich and Danil Galeev. Mixmatch domain adaptaion: Prize-winning solution for both tracks of visda 2019 challenge. arXiv preprint arXiv:1910.03903, 2019. 3
[36] Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, and Kate Saenko. Semi-supervised domain adaptation via minimax entropy. In Proceedings of the IEEE International Conference on Computer Vision, pages 8050–8058, 2019. 5, 6, 11
[37] Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and Kate Saenko. Adversarial dropout regularization. arXiv preprint arXiv:1711.01575, 2017. 2
[38] Swami Sankaranarayanan, Yogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3752–3761, 2018. 2
[39] Alexey A Shvets, Alexander Rakhlin, Alexandr A Kalinin, and Vladimir I Iglovikov. Automatic instrument segmentation in robot-assisted surgery using deep learning. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 624–628. IEEE, 2018. 1
[40] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pages 1195–1204, 2017. 2
[41] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker.Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7472–7481, 2018. 1, 2, 3, 5, 6, 7, 11
[42] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Perez. Advent: Adversarial entropy mini- ´ mization for domain adaptation in semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2517–2526, 2019. 1, 2, 5, 6, 7, 11
[43] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Perez. Dada: Depth-aware domain adap- ´ tation in semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 7364– 7373, 2019. 1
[44] Zhonghao Wang, Yunchao Wei, Rogerio Feris, Jinjun Xiong, Wen-Mei Hwu, Thomas S Huang, and Honghui Shi. Alleviating semantic-level shift: A semi-supervised domain adaptation method for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 936–937, 2020. 2, 3, 5, 6
[45] Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing. arXiv preprint arXiv:1810.08705, 2018. 11
[46] Luyu Yang, Yan Wang, Mingfei Gao, Abhinav Shrivastava, Kilian Q Weinberger, Wei-Lun Chao, and Ser-Nam Lim.
Mico: Mixup co-training for semi-supervised domain adaptation. arXiv preprint arXiv:2007.12684, 2020. 3
[47] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision, pages 6023–6032, 2019. 2, 4
[48] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017. 3
[49] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017. 1
[50] Xinge Zhu, Hui Zhou, Ceyuan Yang, Jianping Shi, and Dahua Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 568– 583, 2018. 2
[51] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of 10 the European conference on computer vision (ECCV), pages 289–305, 2018. 2
这篇关于CVPR2021-Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentati的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







