cube专题

Kylin使用Spark构建Cube
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。下面是单机安装采坑记,直接上配置和问题解决。找一台干净的机器,把hadoop hive hbase从原有节点分别拷贝一份,主要目的是配置文件,可以不在kylin所在机器

6-通过Java代码build cube
转:http://www.cnblogs.com/hark0623/p/5580632.html 通常是用于增量 代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 3

震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集
震惊,从仿真走向现实,3D Map最大提升超12,Cube R-CNN使用合成数据集迁移到真实数据集 Abstract 由于摄像机视角多变和场景条件不可预测,在动态路边场景中从单目图像中准确检测三维物体仍然是一个具有挑战性的问题。本文介绍了一种两阶段的训练策略来应对这些挑战。我们的方法首先在大规模合成数据集RoadSense3D上训练模型,该数据集提供了多样化的场景以实现稳健的特征学习。随后,

【HDU】4670 Cube number on a tree 点分治
传送门:【HDU】4670 Cube number on a tree 题目分析:首先因为至多30个素数,3^30在long long以内,如果一条路径上的数的乘积是个立方数,则这条路径上每个素数因子的个数都应该是3的倍数,于是我们用三进制表示含有素数的状态,当且仅当状态为0(即所有素数的个数都是3的倍数)时这条路径上数的乘积为完全立方数。考虑树分治,每层分治,求出当前重心的一个儿子的一个
Kylin源码解析——Cube构建过程中如何实现降维
-维度简述 Kylin中Cube的描述类CubeDesc有两个字段,rowkey和aggregationGroups。 @JsonProperty("rowkey")private RowKeyDesc rowkey;@JsonProperty("aggregation_groups")private List<AggregationGroup> aggregationGroups; 其
253 - Cube painting
题目:253 - Cube painting 题目大意:每个面用一个字符表示,给出每个面(字符)输出顺序看这两个六面体是否为同一个。 解题思路:如果旋转立方体,会发现位置1 6, 2 5, 3,4上的字符一定还会在相对应的位置出现,例如ab出现在16,那么他们会出现在25,或34,顺序不要求。所以只要判断是否这些位置上的字符会再次出现在相对应的位置上就可以判断是否是同一个立方体。

Cube Texture与环境纹理
一. Cube Texture: cube texture顾名思义是一个立方体纹理,普通纹理一般是一张二维图, 由二维坐标(u,v)决定贴图目标的像素点, 立方体纹理即是由一个立方体 (六个面/六张纹理)每个面上的二维图组成,是一个包含了上下左右前后 六个面的纹理组。因此在使用立方体纹理时也就不能简单的使用(u,v)坐标 来对纹理采样,需要对二维纹理坐标扩展到三维,由三维坐标(u,
HDU3584 Cube【树状数组】【三维】
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=3584 题目大意: 给定一个N*N*N多维数据集A,其元素是0或是1。A[i,j,k]表示集合中第 i 行,第 j 列与第 k 层的值。 首先由A[i,j,k] = 0(1 <= i,j,k <= N)。 给定两个操作: 1:改变A[i,j,k]为!A[i,j,k]。 2:查询A
Hive分析窗口函数(四) GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP 这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。 数据准备: CREATE EXTERNAL TABLE lxw1234 (month STRING,day STRING, cookieid STRING ) ROW FORMAT DELIM
hive Cube, Rollup介绍
https://blog.csdn.net/moon_yang_bj/article/details/17200367 参考资料 apache hive窗口函数官方介绍:http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.0.2/ds_Hive/language_manual/ptf-window.html apache h
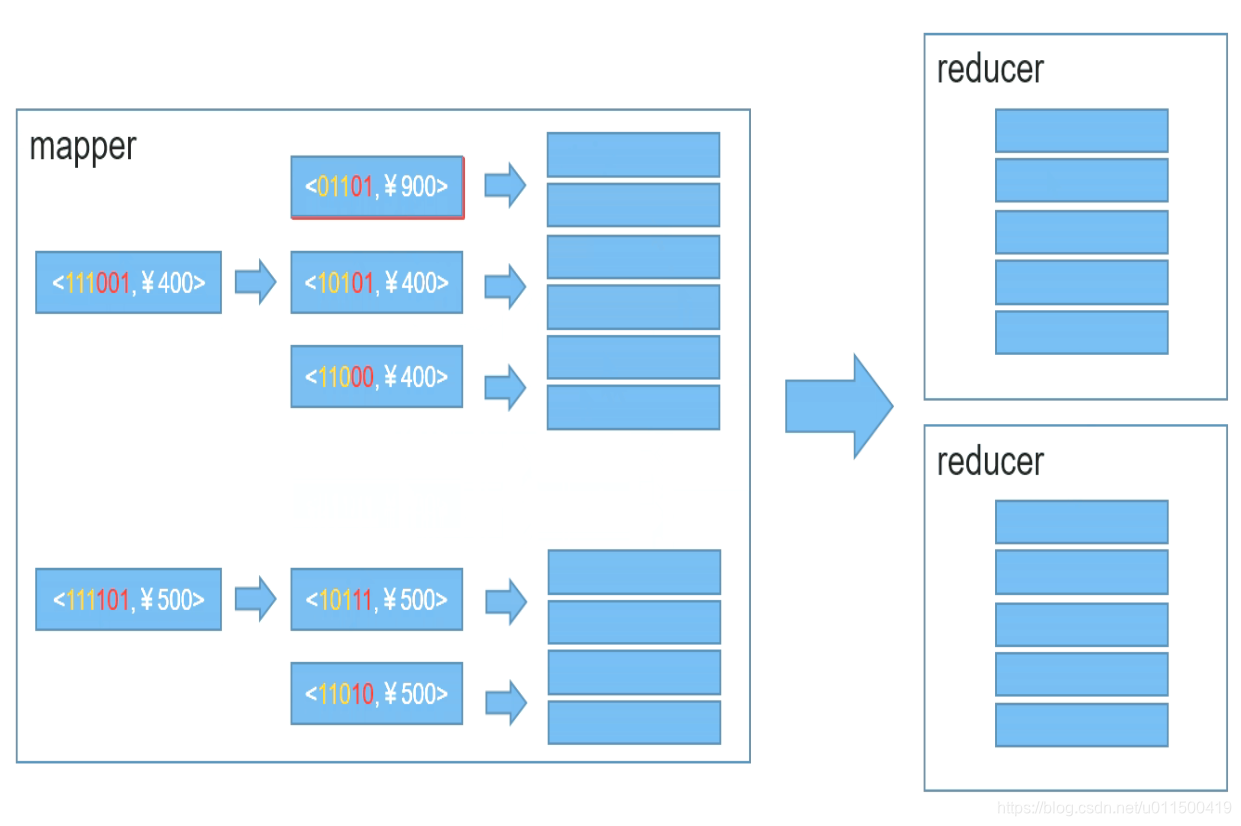

QT与OPENGL一:用dock显示cube例子
刚开始想用vs搭建环境,初步了解了一下,glut似乎太旧,glew,glfw比较难整合到window窗体中。 于是还是选择了QT,QT下开发opencv也很容易。 使用QT过程中会遇到一些错误,有时更改了工程后,需要重新qmake一下。 可以一点点把cube例子加到dock例子中。 提示: QOpenGLShader: Unable to open file “:/vshader.gls
POJ 1988 Cube Stacking (带权并查集)
题目链接:Cube Stacking num数组表示集合个数,under表示比他小的个数即可 代码: #include <stdio.h>#include <string.h>const int N = 30005;int p, a, b, parent[N], under[N], num[N];char q[2];void init() {for (int i = 1; i <

POJ 2155 Matrix ( 二维树状数组 ) || HDU 3584 Cube ( 三维树状数组 )
题目链接~~> 做题感悟:这题只要把一维的树状数组扩展到二维就可以了。 解题思路:树状数组插线问点:先简化一下,如果是一维的树状数组的插线问点让区间 [ a,b ] 同时加 x ,可以先让 [ 1,b ] + 1 ,再让 [ 1 ,a-1 ] -1 ,跟前缀和一样这样区间 [ a,b ] 就实现了 +1 ,但这时数组 c [ ] 代表是它管辖范围内每个点的值为 c [ ] ( 此时c 数组
理解BW DSO/Cube 增量/全量抽数
1.对于数据删除后,怎么抽数使得DSO/Cube实现数据同步? 首先需要说明的是:BW在处理删除没有优势,通过Delta或Full DTP都不能满足要求,目前有两种方法可以实现 第一种:从数据源上下手,增加一个删除标记,在报表展示的时候,filter删除的数据,使得不显示 第二种:伪增量,从Transformation入手,在开始例程中,比较上载的数据和已有数据,设置其指

如何在kylin中构建一个cube
前面的文章介绍了Apache Kylin的安装及数据仓库里面的星型和雪花模型的概念,这篇文章我们来看下,如何构建一个kylin的cube进行查询。这里不得不吐槽一下Kylin的资料,少之又少出现问题网上基本找不到解决方案,所以想要学习kylin,建议大家买一本书系统的学习一下,这里推荐一本入门的书《基于Apache kylin构建大数据分析平台》,介绍的还可以。 下面来看下如何构建一个
Cube MX的多通道ADC DMA配置用于matlab的自动代码生成。
网络文章的参考。 ADC-多通道采集(DMA) https://bbs.21ic.com/icview-1596444-1-1.html :数据宽度为字Word,连续转换模式-使能,不连续转换-禁止。STM32CubeMX教程14 ADC - 多通道DMA转换 https://blog.csdn.net/lc_guo/article/details/135308025 :使用HAL_ADC_St
![bzoj3376/poj1988[Usaco2004 Open]Cube Stacking 方块游戏 — 带权并查集](https://img-blog.csdn.net/20161026144241380?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
bzoj3376/poj1988[Usaco2004 Open]Cube Stacking 方块游戏 — 带权并查集
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3376 题目大意: 编号为1到n的n(1≤n≤30000)个方块正放在地上.每个构成一个立方柱. 有P(1≤P≤100000)个指令.指令有两种: 1.移动(M):将包含X的立方柱移动到包含Y的立方柱上. 2.统计(C):统计名含X的立方柱中,在X下方的方块数目. 题解: 带
杭电OJ 1220:Cube
这纯粹是一道数学题目,推理如下:给你一个正方体,切割成单位体积的小正方体,求所有公共顶点数<=2的小正方体的对数。公共点的数目只可能有:0,1,2,4.很明显我们用总的对数减掉有四个公共点的对数就可以了。总的公共点对数:n^3*(n^3-1)/2(一共有n^3块小方块,从中选出2块)(只有两个小方块之间才存在公共点,我们从所有的小方块中任意选出两个,自然就确定了这两个小方块的公共点的对数,从所
poj 1988 Cube Stacking (poj 1182 食物链(转))
昨晚上和今一早,做了食物链后,便做了这个题,做的郁闷。刚开始的时候我拿最下面的当根节点,做出来后发现这样会漏情况的。比如:11M 1 10M 2 10M 3 10M 4 10M 5 10M 10 6C 10C 4M 4 8C 3C 4 这组测试数据,在M 4 8 合并后,元素3的下方就会漏掉一个箱子。 后来实在没办法了,上网看了看,大家都是以最上面的为根节点o(╯□╰)o(自己好笨。。。),那样
kylin创建 Cube
创建 Cube 是 Kylin 中非常重要的一步,它定义了多维度数据的聚合模型,为后续的多维分析查询提供了基础。以下是一个具体的 Kylin 创建 Cube 的教程: 登录 Kylin Web 界面: 首先,打开浏览器,输入 Kylin 的 Web 地址,进入 Kylin 的 Web 界面。输入用户名和密码登录,进入 Kylin 的主界面。 选择项目: 在 Kylin 主界面中,选择或创建一个

pentaho 示例Cube配置详解(SQL Server版本)
1 首先下载SQL SERVER对应的JDBC driver.见如下链接地址: [1] http://msdn.microsoft.com/en-US/data/aa937724.aspx [2] Google 输入入sql server jdbc亦可. [3] 这里sqljdbc4.jar 是我们需要的Jar包 2 下载Pentaho的多维数据服务器 Mond

sql sum,group by 分组求和后在求总和,with rollup,with cube的区别
有表数据如下: create table tt(name varchar(10),num decimal(18,2),ph int)insert into tt(name,num,ph) values ('test1',10,1)insert into tt(name,num,ph) values ('test1',30,1)insert into tt(name,num,ph) value
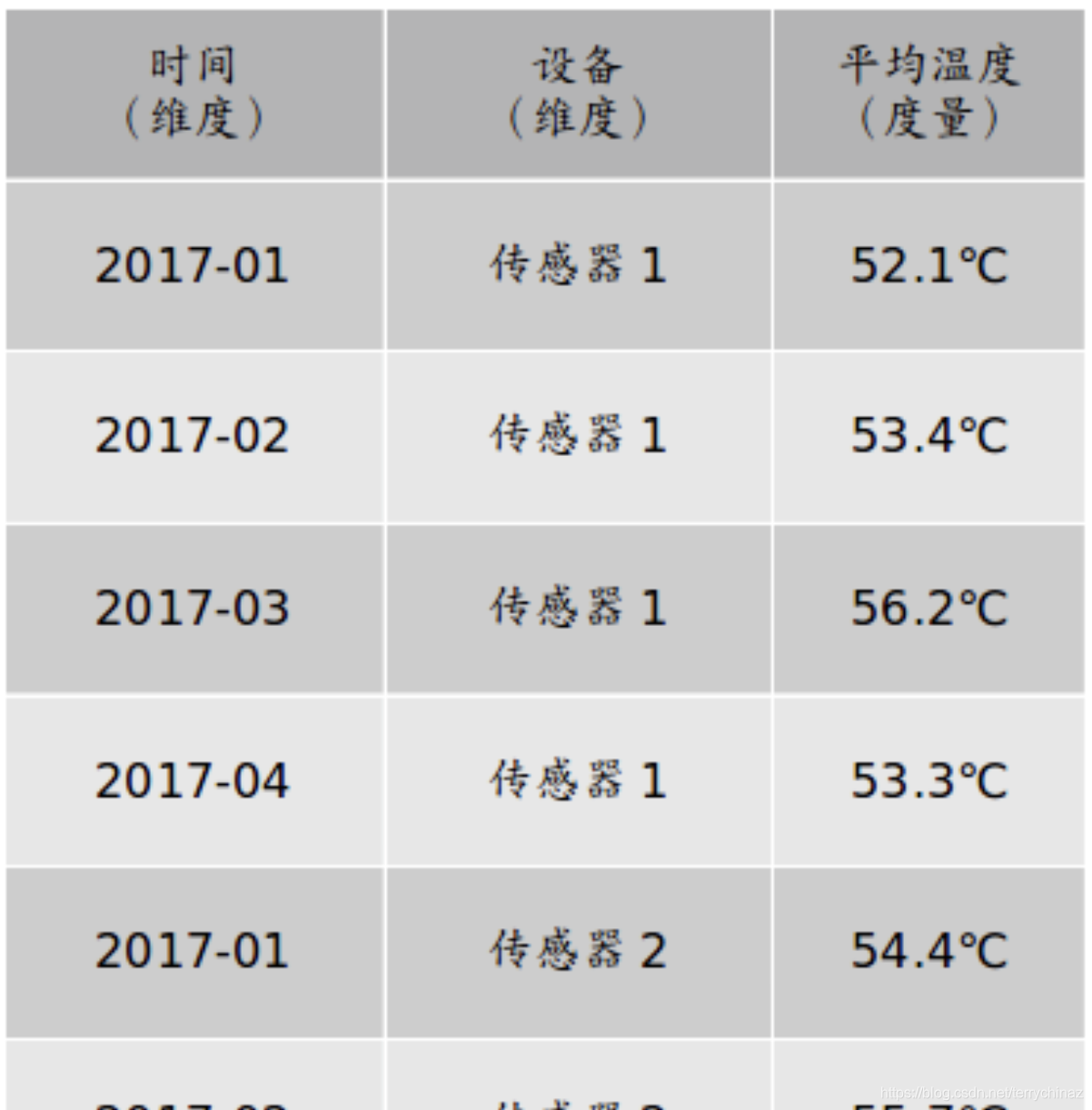
数据分析英文单词释义Byte,Cube,Dimension,Measures,Cuboid,环比
维度和度量 维度和度量是数据分析领域中两个常用的概念。 简单地说,维度就是观察数据的角度。比如传感器的采集数据,可以从时间的维度来观察: 时间维度 也可以进一步细化,从时间和设备两个角度观察: 时间和设备维度 维度一般是离散的值,比如时间维度上的每一个独立的日期,或者设备维度上的每一个独立的设备。因此统计时可以把维度相同的记录聚合在一起,然后应用聚合函数做累加、均值、最大值、最

2U支持24块3.5”硬盘,ZStack Cube存储一体机存储密度提升116%
不同于传统超融合产品的有限虚拟化功能,ZStack Cube超融合一体机提供完善的云计算功能,并作为新一代云基础设施入选IDC《中国超融合基础架构市场评估2023》报告。ZStack Cube超融合系列产品包括ZStack Cube超融合一体机、ZStack Cube信创超融合一体机、ZStack Cube高性能超融合一体机、ZStack Cube CDP备份一体机、ZStack Cube存储一体
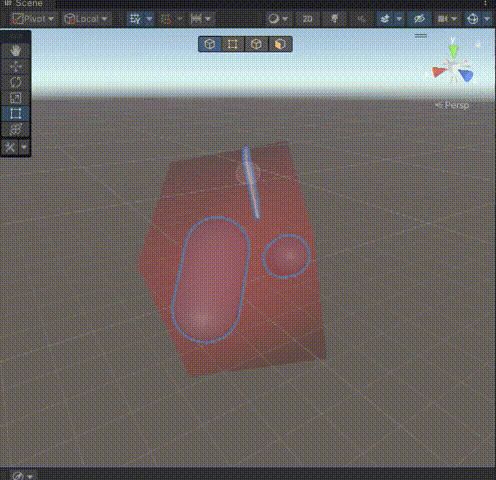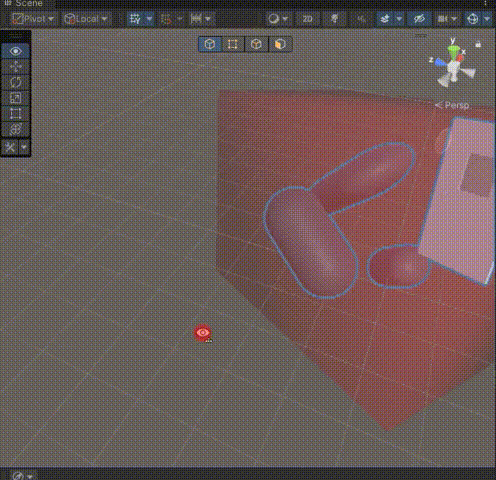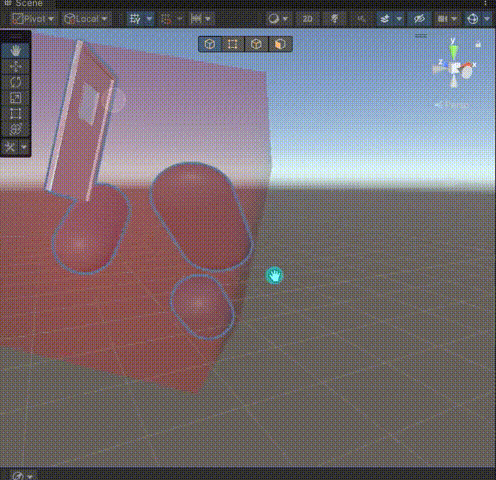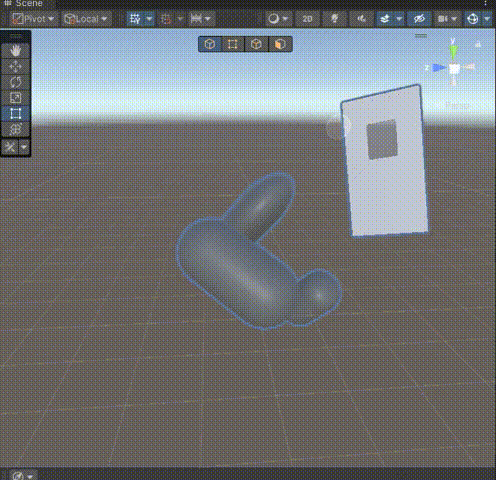
Unity Mesh简化为Cube mesh
Mesh简化为Cube mesh 🍳食用🥙子物体独立生成CubeMesh🥪合并成一个CubeMesh🌭Demo 🍳食用 下载并导入插件👈即可在代码中调用。 🥙子物体独立生成CubeMesh gameObject.ToCubeMesh_Invidual(); 🥪合并成一个CubeMesh gameObject.ToCubeMesh(); 🌭Demo