本文主要是介绍数据分析英文单词释义Byte,Cube,Dimension,Measures,Cuboid,环比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
维度和度量
维度和度量是数据分析领域中两个常用的概念。
简单地说,维度就是观察数据的角度。比如传感器的采集数据,可以从时间的维度来观察:
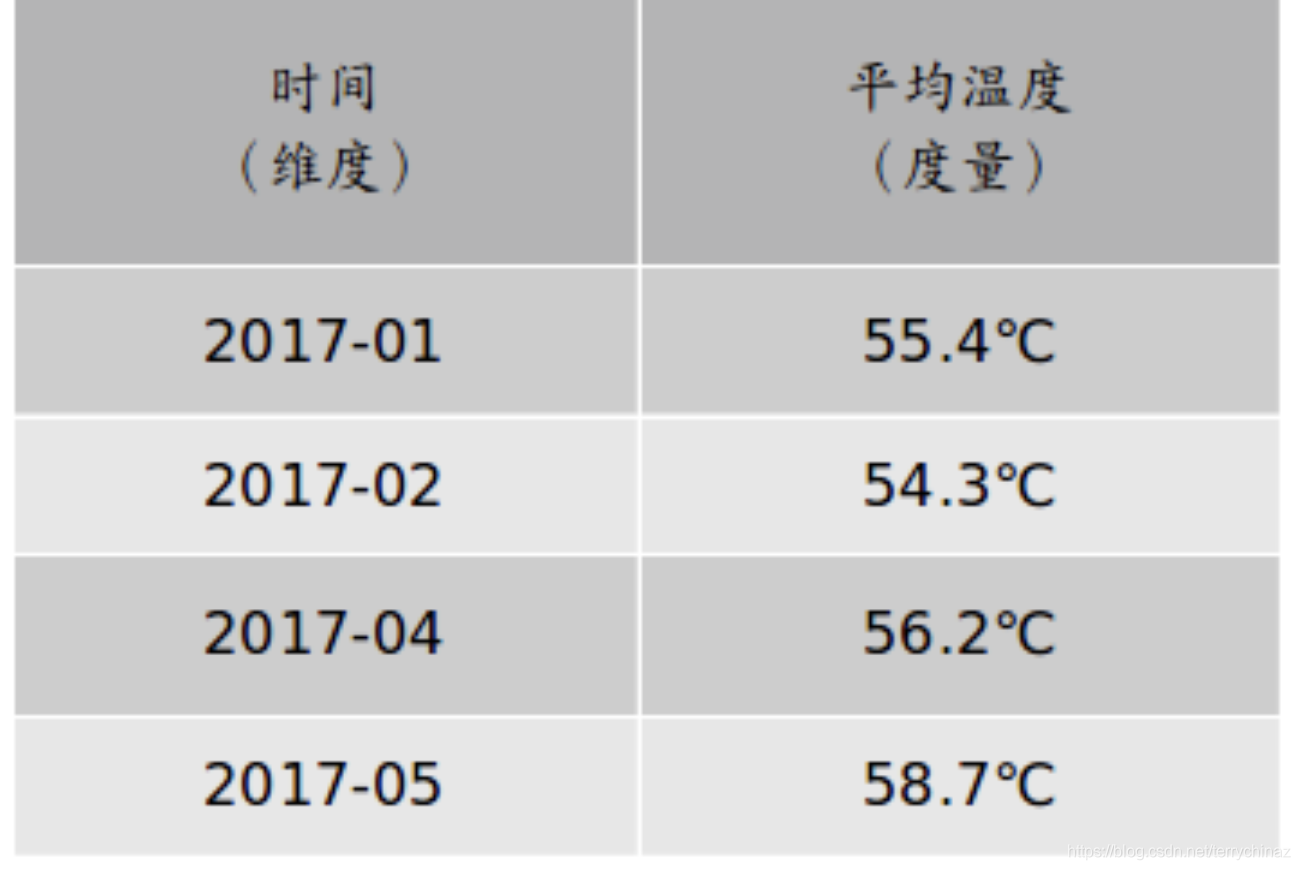
时间维度
也可以进一步细化,从时间和设备两个角度观察:
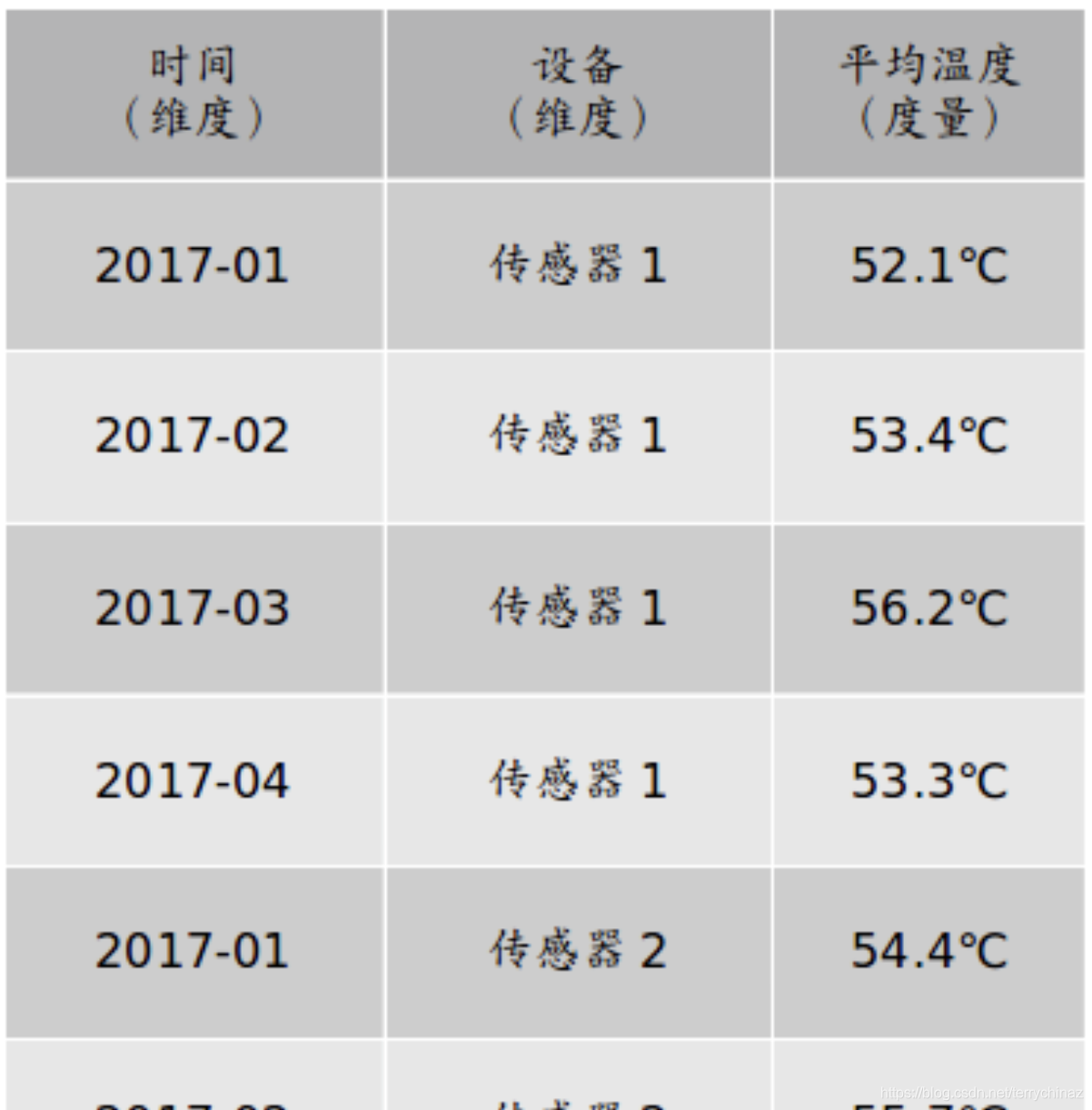
时间和设备维度
维度一般是离散的值,比如时间维度上的每一个独立的日期,或者设备维度上的每一个独立的设备。因此统计时可以把维度相同的记录聚合在一起,然后应用聚合函数做累加、均值、最大值、最小值等聚合计算。
度量就是被聚合的统计值,也就是聚合运算的结果,它一般是连续的值,如以上两个图中的温度值,或是其他测量点,比如湿度等等。通过对度量的比较和分析,我们就可以对数据做出评估,比如这个月设备运行是否稳定,某个设备的平均温度是否明显高于其他同类设备等等。
数据仓库
Data Warehouse,简称DW,中文名数据仓库,是商业智能(BI)中的核心部分。主要是将不同数据源的数据整合到一起,通过多维分析等方式为企业提供决策支持和报表生成。那么它与我们熟悉的传统关系型数据库有什么不同呢?
简而言之,用途不同。数据库面向事务,而数据仓库面向分析。数据库一般存储在线的业务数据,需要对上层业务的改变做出实时反应,涉及到增删查改等操作,所以需要遵循三大范式,需要ACID。而数据仓库中存储的则主要是历史数据,主要目的是为企业决策提供支持,所以可能存在大量数据冗余,但利于多个维度查询,为决策者提供更多观察视角。
在传统BI领域中,数据仓库的数据同样存储在Oracle、MySQL等数据库中,而在大数据领域中最常用的数据仓库就是Apache Hive,Hive也是Apache Kylin默认的数据源。
事实表和维度表
事实表(Fact Table)是指存储有事实记录的表,如系统日志、销售记录、传感器数值等;事实表的记录是动态增长的,所以它的体积通常远大于维度表。
维度表(Dimension Table)或维表,也成为查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等属性)、地区表(包含国家、省/州、城市等属性)等。维度表的变化通常不会太大。使用维度表有许多好处:
缩小了事实表的大小。
便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
维度表可以为多个事实表重用。
星形模型
星形模型(Star Schema)是数据挖掘中常用的几种多维数据模型之一。它的特点是只有一张事实表,以及零到多个维度表,事实表与维度表通过主外键相关联,维度表之间没有关联,就像许多小星星围绕在一颗恒星周围,所以名为星形模型。
另一种常用的模型是雪花模型(SnowFlake Schema),就是将星形模型中的某些维表抽取成更细粒度的维表,然后让维表之间也进行关联,这种形状酷似雪花的的模型称为雪花模型。
还有一种各位复杂的模型,具有多个事实表,维表可以在不同事实表之间公用,这种模型被称为星座模型。
不过,Kylin目前只支持星形模型。
环比
环比,表示连续2个单位周期(比如连续两月)内的量的变化比。
环比增长率=(本期数-上期数)/上期数×100%。 反映本期比上期增长了多少;环比发展速度,一般是指报告期水平与前一时期水平之比,表明现象逐期的发展速度。
同比增长率=(本期数-同期数)/|同期数|×100%。
Cube和Cuboid
了解了维度和度量之后,我们可以将数据模型上的所有字段进行分类:它们要么是维度,要么是度量。根据定义好的维度和度量,我们就可以构建Cube了。
对于一个给定的数据模型,我们可以对其上的所有维度进行组合。对于N个维度来说,组合所有可能性共有2的N次方种。对于每一种维度的组合,将度量做聚合计算,然后将运算的结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,被称为Cube。
举个例子。假设有一个电商的销售数据集,其中维度包括时间(Time)、商品(Item)、地点(Location)和供应商(Supplier),度量为销售额(GMV)。那么所有维度的组合就有2的4次方,即16种,比如一维度(1D)的组合有[Time]、[Item]、[Location]、[Supplier]4种;二维度(2D)的组合有[Time Item]、[Time Location]、[Time Supplier]、[Item Location]、[Item Supplier]、[Location Supplier]6种;三维度(3D)的组合也有4种;最后零维度(0D)和四维度(4D)的组合各有1种,总共16种。
计算Cubiod,即按维度来聚合销售额。如果用SQL语句来表达计算Cuboid [Time, Location],那么SQL语句如下:
select Time, Location, Sum(GMV) as GMV from Sales group by Time, Location
将计算的结果保存为物化视图,所有Cuboid物化视图的总称就是Cube。
这篇关于数据分析英文单词释义Byte,Cube,Dimension,Measures,Cuboid,环比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![Java实现将byte[]转换为File对象](/front/images/it_default.jpg)