chatglm专题

什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选? 答:Bert 的模型由多层双向的Transformer编码器组成,由12层组成,768隐藏单元,12个head,总参数量110M,约1.15亿参数量。NLU(自然语言理解)任务效果很好,单卡GPU可以部署,速度快,V100GPU下1秒能处理2千条以上。 ChatGLM-6B, LLaMA-7B模型分别是60亿参数量和

LongAlign:ChatGLM 团队发布的超长文指令数据及训练评估方案
前言 LongAlign: A Recipe for Long Context Alignment of Large Language Models 这是一个由清华 ChatGLM 团队提出的长上下文指令微调数据、模型训练、评测方案一条龙。主要包括: 长文数据集:从九个来源收集长序列,通过 Self-Instruct 用 Claude 2.1 构建的一个长指令遵循数据集,10000条,长度在

深度解析:万字文章全面解读ChatGLM系列发展历程与功能特点
介绍 Github:https://github.com/THUDM/ChatGLM-6B 模型文件:https://huggingface.co/THUDM/chatglm-6b 博客:https://chatglm.cn/blog 论文:https://arxiv.org/pdf/2103.10360.pdf ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于

ModuleNotFoundError: No module named ‘transformers_modules.chatglm-6b-v1‘
ModuleNotFoundError: No module named 'transformers_modules.chatglm-6b-v1' 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,

【自用】chatglm-sdk-java详解
chatglm-sdk-java详解 整体项目的流程大致为: 通过工厂模式创建ChatGLMSessionFactory工厂,每个请求创建一个ChatGLMSession,通过ChatGLMSession中的方法来实现与ChatGLM的交互对接。 分为几个模块,executor,interceptor,model,session,utils,GLMApi接口, 其中session用来构建sess
从几个角度分析chatgpt、chatglm、通义千问之间的实际使用差距
第一个问题 chatglm作为经济实力最弱的一家无法实现平峰的使用体验,在很多时候会出现因为网络问题、集群计算上限问题导致的客户体验较差,无法快速返回用户所期待的内容。 在日常生活中因为本人是一名程序员,在方案、代码纠错、自然语言转代码的场景应用比较多。例如我提出几个关键词希望获取到一份有效的方案这个方面chatglm本来应该是表现得最好的。而实际上我们通过一个简单地问题就可以测试出来这几个

chatglm-6b部署加微调
这里不建议大家使用自己的电脑,这边推荐使用UCloud优刻得-首家公有云科创板上市公司 我们进去以后会有一个新人优惠,然后有一个7天30元的购买,购买之后可以去选择镜像,然后在镜像处理的这个位置,可以选择镜像,直接选择chatglm6b的就可以了,非常的方便和简单。 然后去控制台,找到这个这个ip还有链接,直接登录就可以了。 登录之后会有这个东西,这个时候有什么需求安装上面的命令来弄就可
使用 OKhttp3 实现 智普AI ChatGLM HTTP 调用(SSE、异步、同步)
SSE 调用 SSE(Sever-Sent Event),就是浏览器向服务器发送一个HTTP请求,保持长连接,服务器不断单向地向浏览器推送“信息”(message),这么做是为了节约网络资源,不用一直发请求,建立新连接。 // 创建请求对象Request request = new Request.Builder().url(String.format(sseApi, seeId))//

大模型ChatGLM的部署与微调
前言:最近大模型太火了,导师让我看看能不能用到自己的实验中,就想着先微调一个chatGLM试试水,微调的过程并不难,难的的硬件条件跟不上,我试了一下lora微调,也算跑通了吧,虽然最后评估的时候报错了,淦! 真正设计lora微调的就那一行代码,仅以此博客作为记录,希望有大佬能够告知为啥评估的时候会出现那两个bug,不胜感激! 环境准备 GPU:3090两块 系统镜像:Ubuntu 9.4

ChatGLM lora微调时出现KeyError: ‘context‘的解决方案
问题概述 在使用 ChatGLM Lora 进行微调时,您遇到了 KeyError: 'context' 错误,这通常表明代码中缺少对 context 变量的定义或赋值。 ChatGLM Lora 介绍 ChatGLM Lora 是基于 Transformer 架构的大型语言模型,它具有强大的文本生成和理解能力。Lora 是对其进行微调的技术,可以使其在特定领域或任务上表现更好。 解决方案

阿里云部署ChatGLM-6B及ptuning微调教程
一、模型部署 1.进入阿里云人工智能平台PAI。 2.申请免费试用。 3.打开交互式建模 PAI-DSW。 4.新建实例。 5.填写配置。 6.实例准备完成后点击打开。 7.打开实例后点击Teminal。 8.在Teminal中依次输入以下命令并执行。 apt-get updateapt-get install g

LLM大语言模型(十五):LangChain的Agent中使用自定义的ChatGLM,且底层调用的是remote的ChatGLM3-6B的HTTP服务
背景 本文搭建了一个完整的LangChain的Agent,调用本地启动的ChatGLM3-6B的HTTP server。 为后续的RAG做好了准备。 增加服务端role:observation ChatGLM3的官方demo:openai_api_demo目录 api_server.py文件 class ChatMessage(BaseModel):# role: Litera

window 安装大模型 chatglm-6b
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一、 前言二、准备工作2.1 电脑2.2 组件安装2.3 开始安装2.3.1下载官方代码,安装Python依赖的库2.3.2 下载INT4量化后的预训练结果文件2.3.3 Windows+C

从零开始大模型开发与微调:基于PyTorch与ChatGLM 书籍PDF分享
大模型是深度学习自然语言处理皇+冠上的一颗明珠,也是当前AI和NLP研究与产业中最重要的方向之一。本书使用PyTorch 2.0作为学习大模型的基本框架,以ChatGLM为例详细讲解大模型的基本理论、算法、程序实现、应用实战以及微调技术,为读者揭示大模型开发技术。 😝有需要此本<从零开始 大模型开发与微调>的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓 本书共18章,
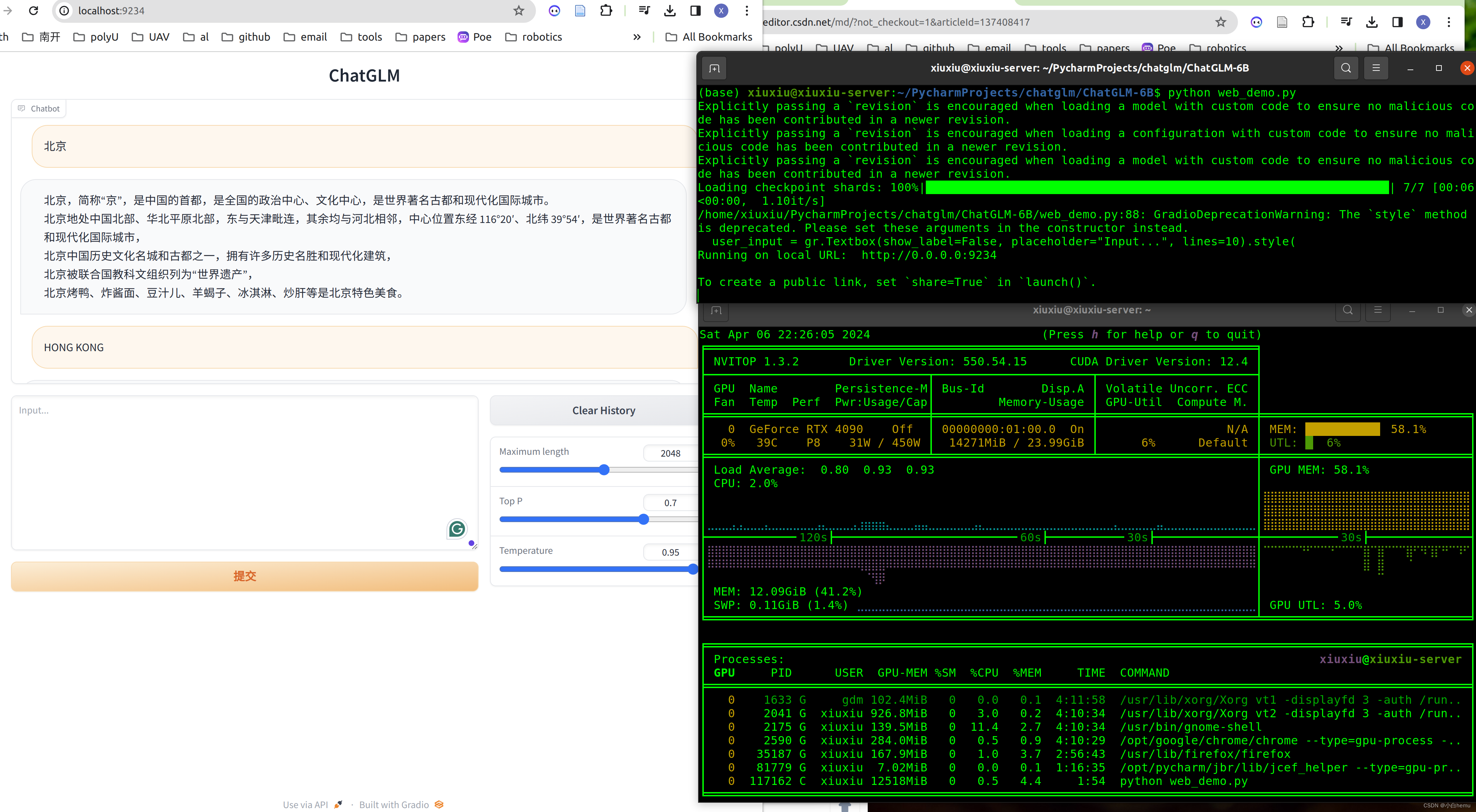
复现ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 项目代码https://github.com/THUDM/ChatGLM-6B 权重开放:https://huggingface.co/TH
基于chatGLM在llama index上建立Text2SQL
基于chatGLM在llama index上建立Text2SQL 文中使用了chatglm的llm和embedding modle,利用的智谱的免费token Text2SQL Text2SQL其实就是从文本到SQL,也是NLP中的一种实践,这可以降低用户和数据库交互的门槛,无需懂SQL就可以拿到数据库数据。Text2SQL实现了从自然语言到SQL语言的生成,更加进一步的是直接给出数据
LLM-在CPU环境下如何运行ChatGLM-6B
ChatGLM-6B-INT4 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT4 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT4 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 6G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。 在 CPU 上运行时,会根据硬

更改chatglm认知
ChatGLM-Efficient-Tuning 下载源代码 下载ChatGLM-Efficient-Tuning 解压 创建虚拟环境 conda create --prefix=D:\CondaEnvs\chatglm6btrain python=3.10cd D:\ChatGLM-Efficient-Tuning-mainconda activate D:\CondaEnvs\c
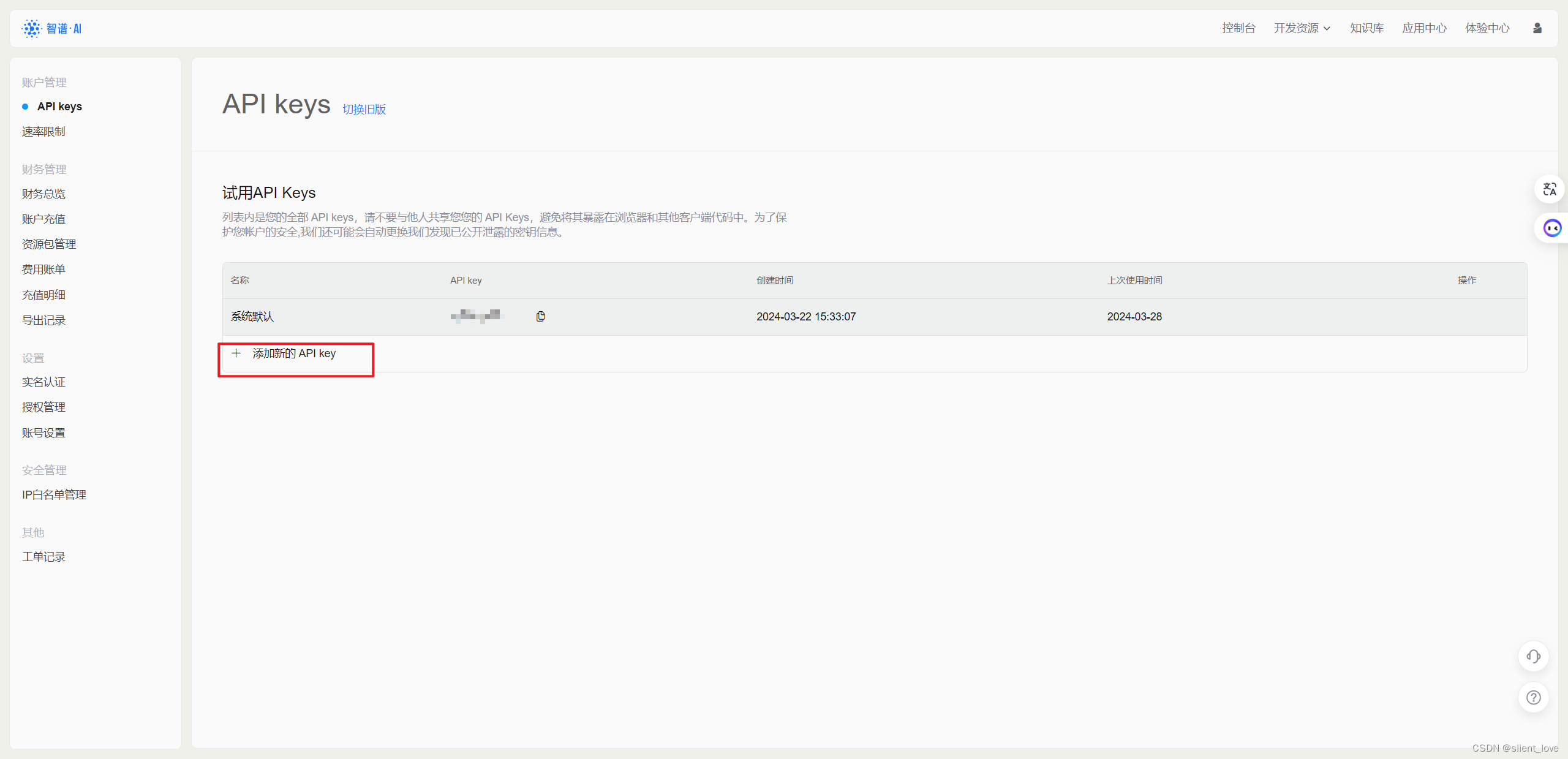
python实现在线 ChatGLM调用
python实现在线 ChatGLM调用 1. 申请调用权限: 收钱进入到质谱AI开放平台,点击“开始使用”或者“开发者工具台”进行注册: 对于需要使用 API key 来搭建应用的话,需要点击右边红框中的查看 API key,就会进入到我们个人的 API 管理列表中。 在该界面,我们就可以看到我们获取到的 API 所对应的应用名字和 API key 了。 我们可以点击 添加新的 API
【DataWhale学习】用免费GPU线上跑chatGLM、SD项目实践
用免费GPU线上跑chatGLM、SD项目实践 DataWhale组织了一个线上白嫖GPU跑chatGLM与SD的项目活动,我很感兴趣就参加啦。之前就对chatGLM有所耳闻,是去年清华联合发布的开源大语言模型,可以用来打造个人知识库什么的,一直没有尝试。而SD我前两天刚跟着B站秋叶大佬和Nenly大佬的视频学习过,但是生成某些图片显存吃紧,想线上部署尝试一下。 参考:DataWhale

人工智能_大模型007_CPU微调ChatGLM大模型_使用P-Tuning v2进行大模型微调_007_微调_002---人工智能工作笔记0142
这里我们先试着训练一下,我们用官方提供的训练数据进行训练. 也没有说使用CPU可以进行微调,但是我们先执行一下试试: https://www.heywhale.com/mw/project/6436d82948f7da1fee2be59e 可以看到说INT4量化级别最低需要7GB显存可以启动微调,但是 并没有说CPU可以进行微调.我们来尝试一下: 可以看到有这两种微调方式,然后
【腾讯云 HAI域探秘】整合腾讯云HAI的ChatGLM模型到NUXT官网:实现智能IM功能
文章目录 脑图分析im效果演示前言腾讯云HAI介绍HAI 服务优势场景介绍 创建NUXT模板配置im相关内容客服图标客服对话框主体 物料准备ChatGLM2 6B 创建选择应用等待创建完成启动 ChatGLM2-6B 提供的 API 服务更新软件源列表指令解释 查看api.py 文件修改api.py文件引入中间件添加跨域中间件修改接口地址 开启API服务新增服务器端口规则测试接口 对接nu
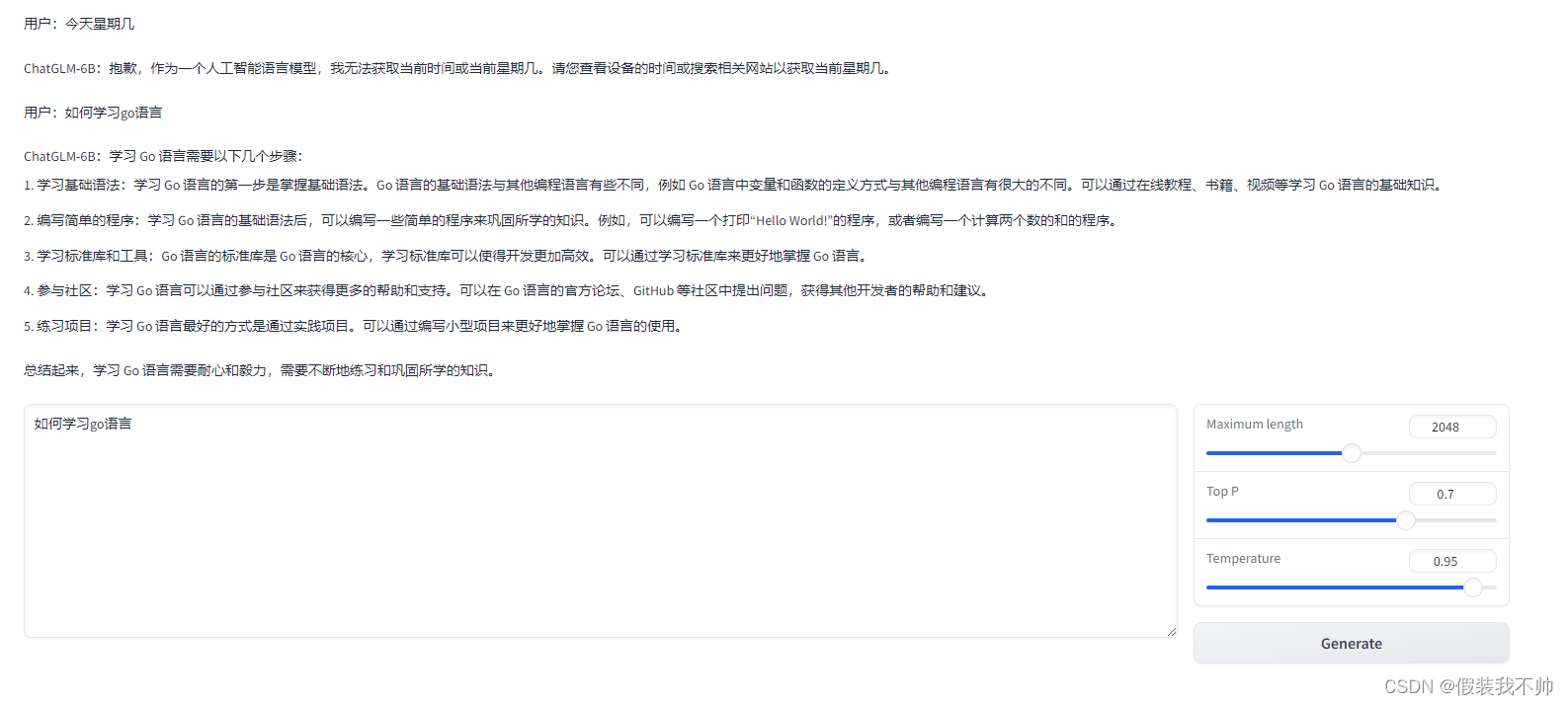
利用colab部署chatglm
登录colab 创建新的notebook 选择notebook设置 选择GPU然后保存,需要选择GPU 克隆代码 !git clone https://github.com/THUDM/ChatGLM-6B.git 切换到目录安装所需要的依赖 %cd /content/ChatGLM-6B%pwd!pip install -r requirements.txt 安装所

CPU服务器安装运行智谱大模型ChatGLM-6B
CPU运行智谱大模型ChatGLM-6B 说明 我的服务器配置是16C32G,跑大模型最好内存要大一些才行,不然跑不起来。 下载 git clone https://github.com/THUDM/ChatGLM-6B.git 安装依赖包 pip install -r requirements.txt 下载模型文件 在huggingface上需要翻墙,有条件的可以直接下载,不行可
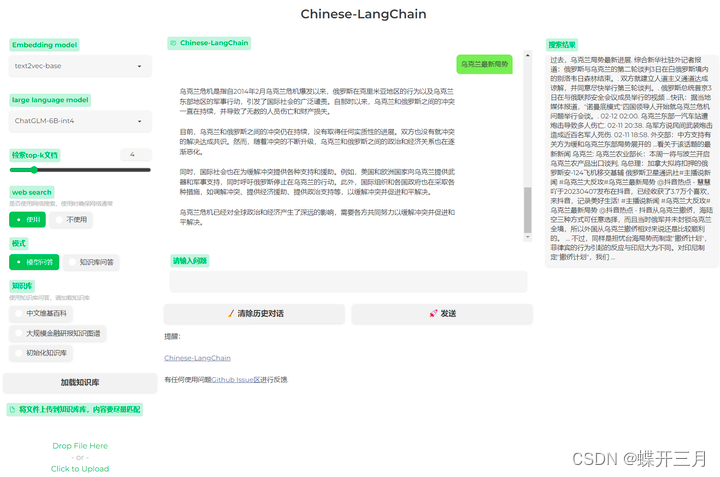
ChatGLM:CPU版本如何安装和部署使用
前段时间想自己部署一个ChatGLM来训练相关的物料当做chatgpt使用,但是奈何没有gpu机器,只能使用cpu服务器尝试使用看看效果 我部署的 Chinese-LangChain 这个项目,使用的是LLM(ChatGLM)+embedding(GanymedeNil/text2vec-large-chinese)+langChain的组合 一、环境
利用chatglm进行问答对生成 自动问答对生成
最近设计了一些prompt提示词,感觉在glm等模型上达到了可用的程度。以下是几类提示词,这些提示词可以用来从一些文本中生成问题和对应的答案。在2024年3月5日左右,能够达到接近人类70%的水平(主要指问题的合理程度、回答的有用成都、语言的美观程度等,属于紫的个人主观评价)。 以下示例中的素材均由大模型生成,不具备真实性。 在开始之前,你可以给大模型设定一个角色,我的提示词是: 你善于根据