本文主要是介绍更改chatglm认知,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGLM-Efficient-Tuning
下载源代码
下载ChatGLM-Efficient-Tuning
解压

创建虚拟环境
conda create --prefix=D:\CondaEnvs\chatglm6btrain python=3.10
cd D:\ChatGLM-Efficient-Tuning-main
conda activate D:\CondaEnvs\chatglm6btrain
安装所需要的包
pip install -r requirements.txt
修改测试数据
修改data下self_cognition.json
NAME和AUTHOR修改为自己想起的名字即可
训练
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的 bitsandbytes 库, 支持 CUDA 11.1 到 12.1.
查看cuda版本
nvcc --version

满足条件,安装windows下的LoRA
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whl
开始训练
单 GPU 微调训练
# 选择gpu显卡二选一,看自己的操作系统
# linux
# CUDA_VISIBLE_DEVICES=0
# windows
# set CUDA_VISIBLE_DEVICES=0
python src/train_bash.py --stage sft --model_name_or_path path_to_your_chatglm_model --do_train --dataset alpaca_gpt4_zh --finetuning_type lora --output_dir path_to_sft_checkpoint --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16

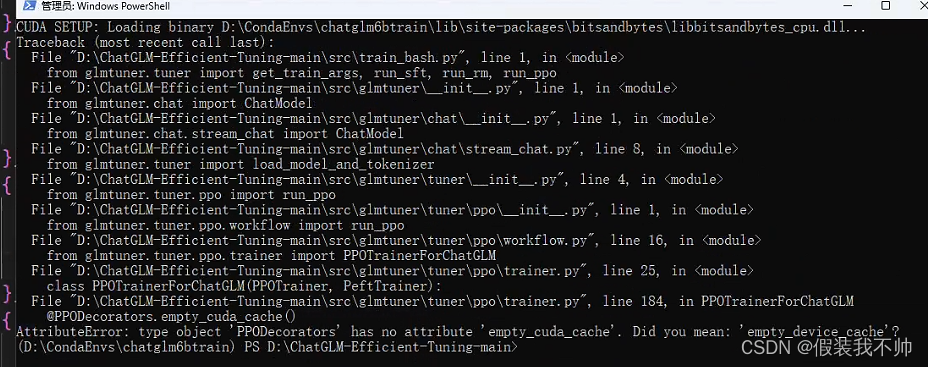
AttributeError: type object ‘PPODecorators’ has no attribute ‘empty_cuda_cache’. Did you mean: ‘empty_device_cache’?
修改trl版本trl==0.7.2
pip install trl==0.7.2

ImportError: cannot import name ‘top_k_top_p_filtering’ from ‘transformers’
pip install torch==1.13.1
pip install accelerate==0.21.0
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
ImportError: cannot import name ‘COMMON_SAFE_ASCII_CHARACTERS’ from 'charset_normalizer.constant
pip install chardet
cannot import name ‘LRScheduler’ from ‘torch.optim.lr_scheduler’
pip install transformers==4.29.1

下载数据集
https://huggingface.co/THUDM/chatglm-6b
python src/train_bash.py --stage sft --model_name_or_path path_to_your_chatglm_model --do_train --dataset self_cognition --finetuning_type lora --output_dir path_to_sft_checkpoint --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16 --model_name_or_path chatglm-6b
ValueError: Attempting to unscale FP16 gradients
pip install peft==0.4.0

Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
修改train_bash.py
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"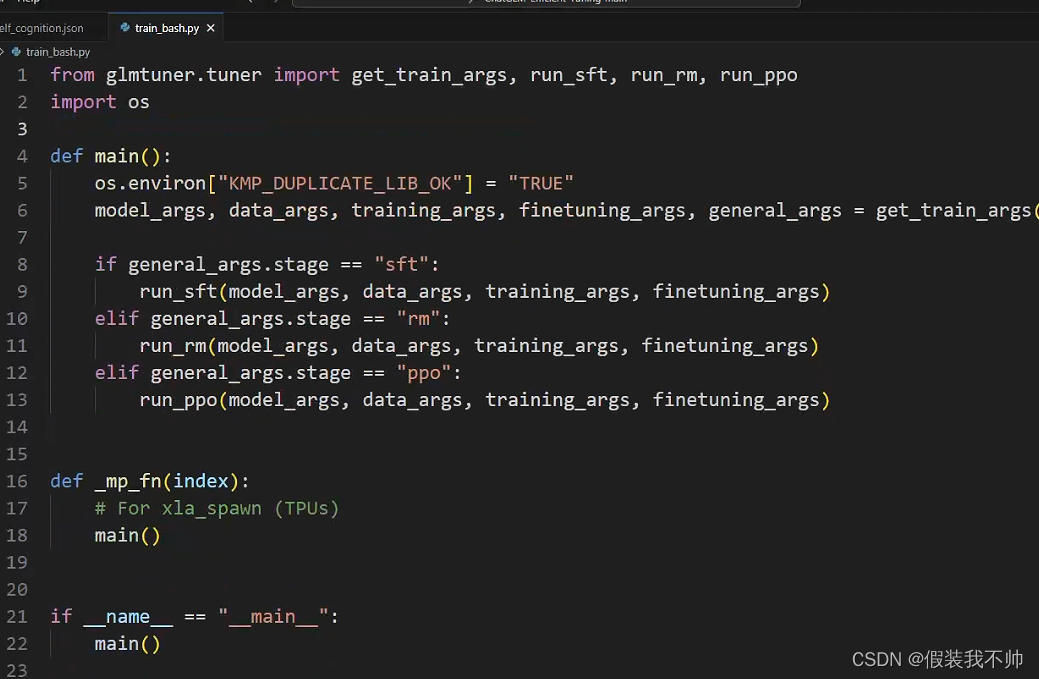
或者设置一下环境变量
set KMP_DUPLICATE_LIB_OK=TRUE
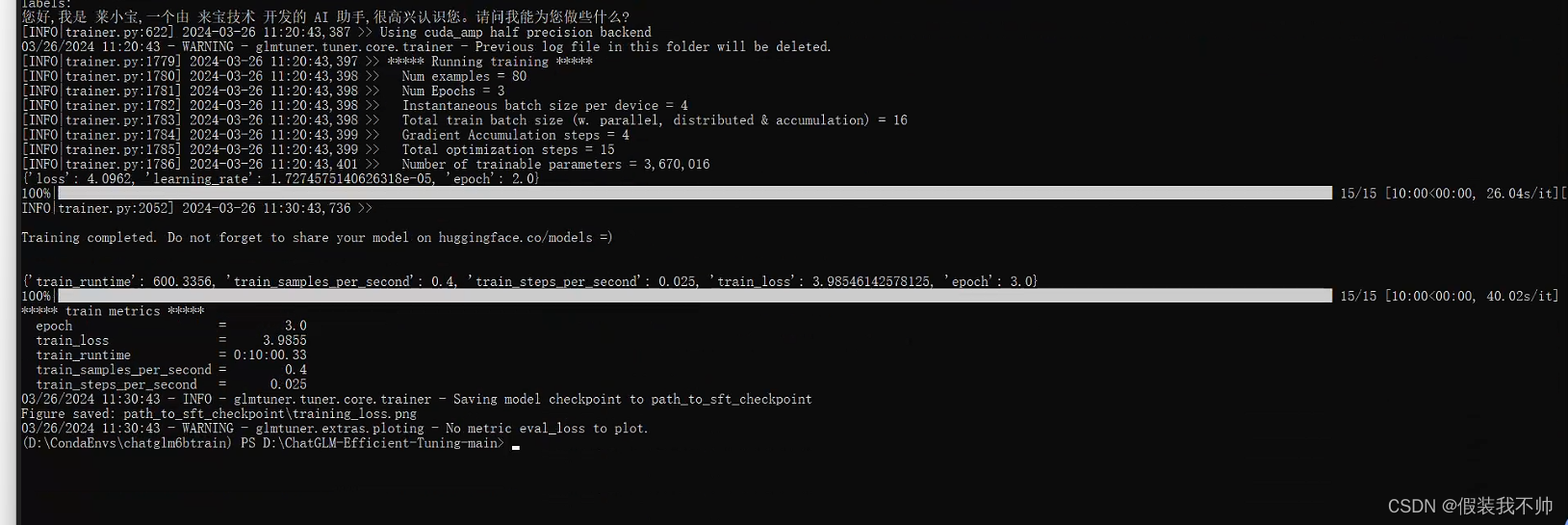
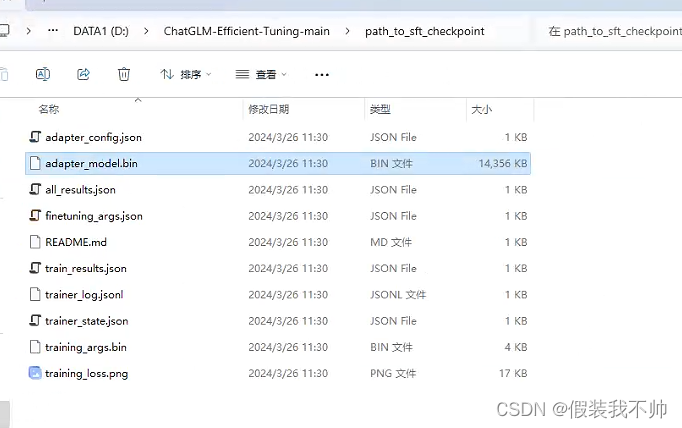
测试训练结果
python src/cli_demo.py --model_name_or_path chatglm-6b --checkpoint_dir path_to_sft_checkpoint

训练的结果好像并不理想

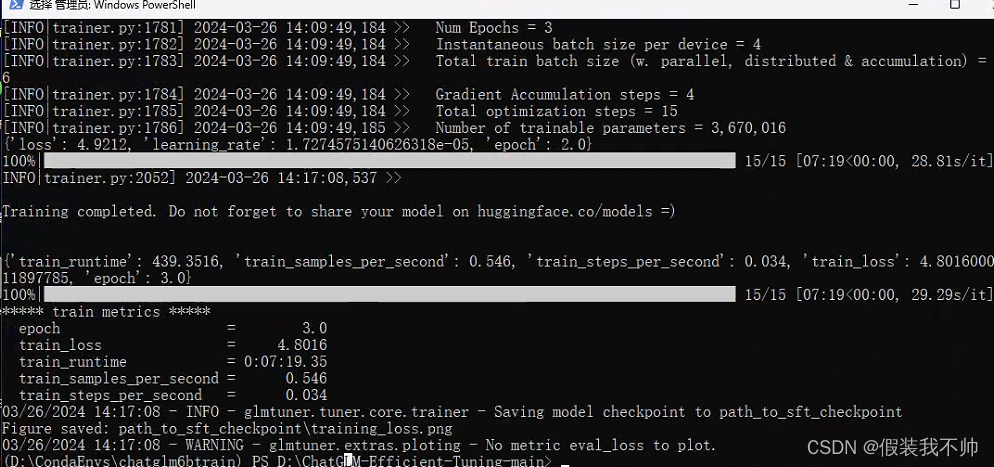
下载0.1.0版本试试
git lfs install
git clone -b v0.1.0 https://huggingface.co/THUDM/chatglm-6bpython src/train_bash.py --stage sft --model_name_or_path path_to_your_chatglm_model --do_train --dataset self_cognition --finetuning_type lora --output_dir path_to_sft_checkpoint --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16 --model_name_or_path chatglm6b010python src/cli_demo.py --model_name_or_path chatglm6b010 --checkpoint_dir path_to_sft_checkpoint
LLaMA-Efficient-Tuning
下载源代码
尝试还是不行,尝试LLaMA-Efficient-Tuning
下载源代码解压,创建新的虚拟环境

conda create --prefix=D:\CondaEnvs\llama python=3.10
cd D:\LLaMA-Factory-main
conda activate D:\CondaEnvs\llama
安装所需要的包
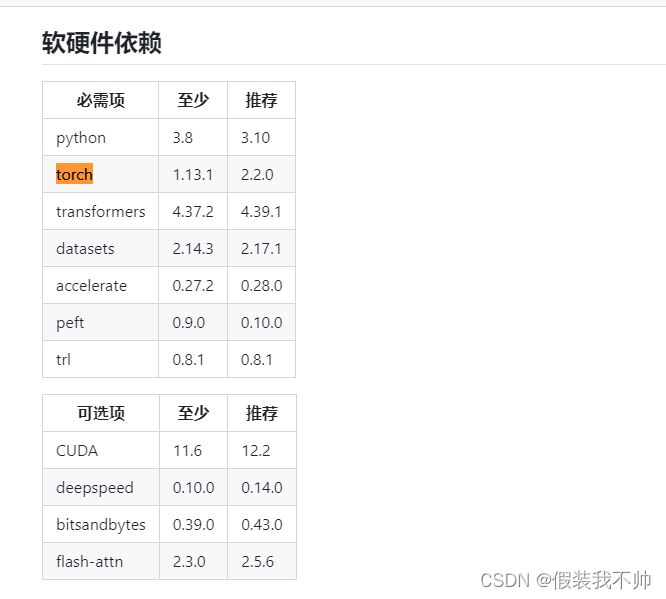
# pytorch GPU版本
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install transformers==4.37.2
pip install datasets==2.14.3
pip install accelerate==0.27.2
pip install peft==0.9.0
pip install trl==0.8.1pip install -r requirements.txt
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
如果您在 Hugging Face 模型和数据集的下载中遇到了问题,可以通过下述方法使用魔搭社区。
# linux
# export USE_MODELSCOPE_HUB=1
# Windows
set USE_MODELSCOPE_HUB=1
接着即可通过指定模型名称来训练对应的模型
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--model_name_or_path modelscope/Llama-2-7b-ms \... # 参数同下
开启网页
# set CUDA_VISIBLE_DEVICES=0
python src/train_web.py
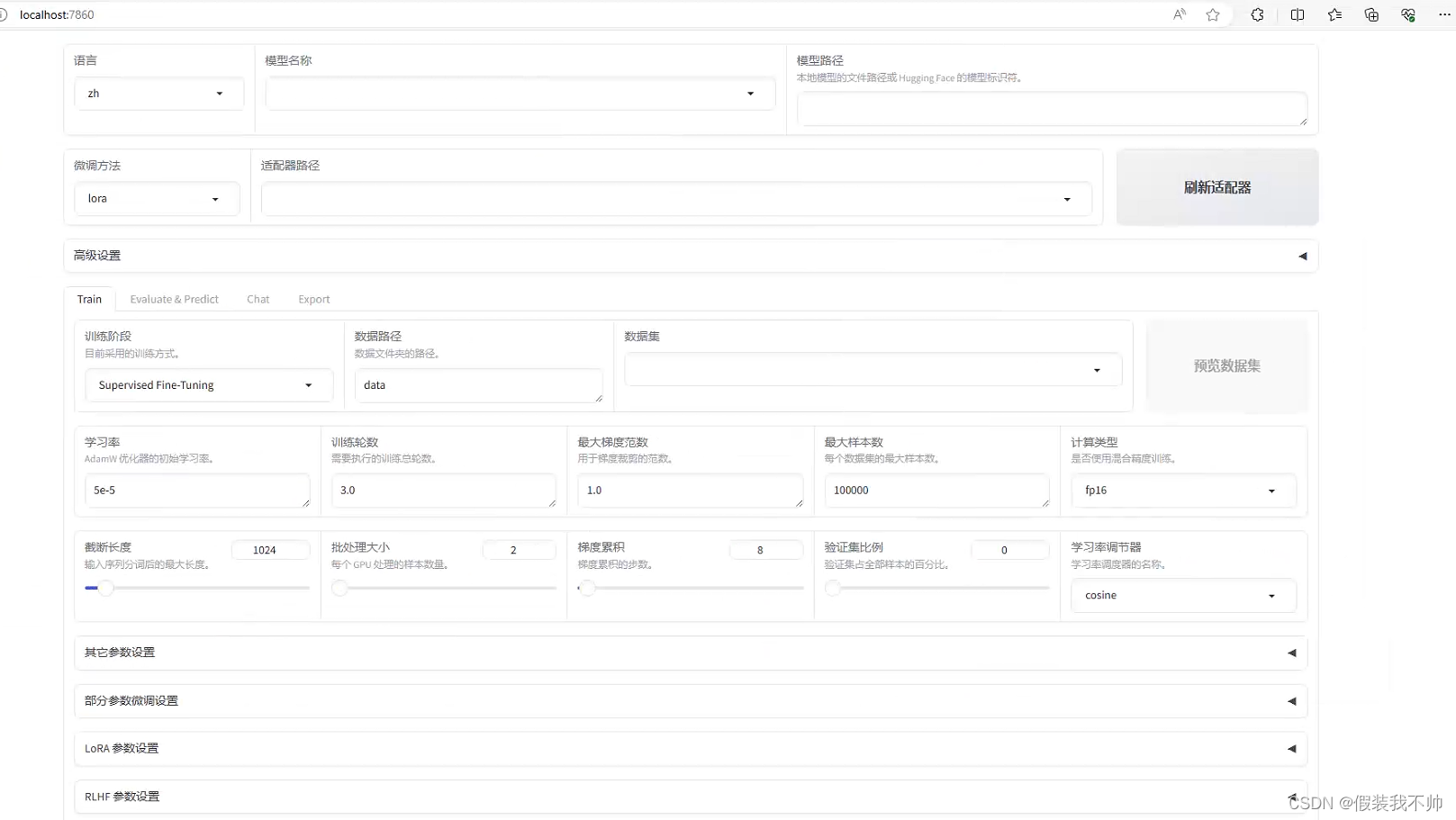
命令行使用
set CUDA_VISIBLE_DEVICES=0
python src/train_bash.py --stage pt --do_train --model_name_or_path path_to_llama_model --dataset wiki_demo --finetuning_type lora --lora_target q_proj,v_proj --output_dir path_to_pt_checkpoint --overwrite_cache --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16
qwen1.5-0.5b模型huggingface
qwen1.5-0.5b模型魔搭社区

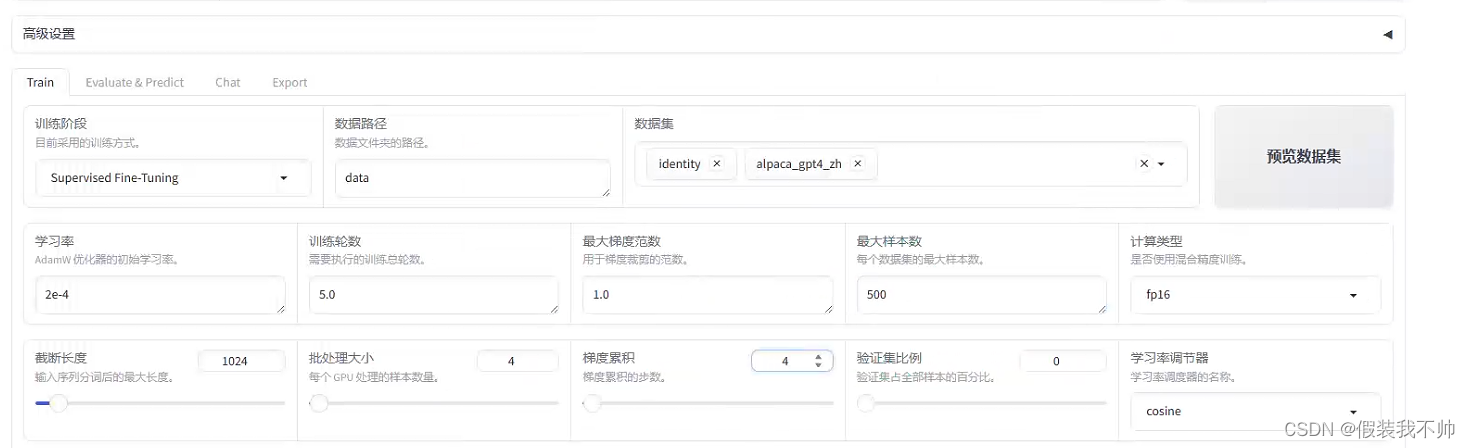
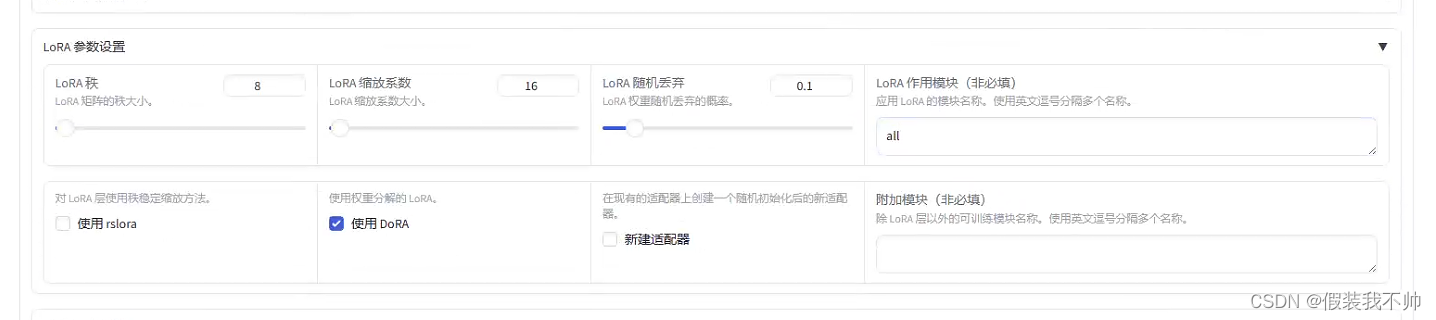
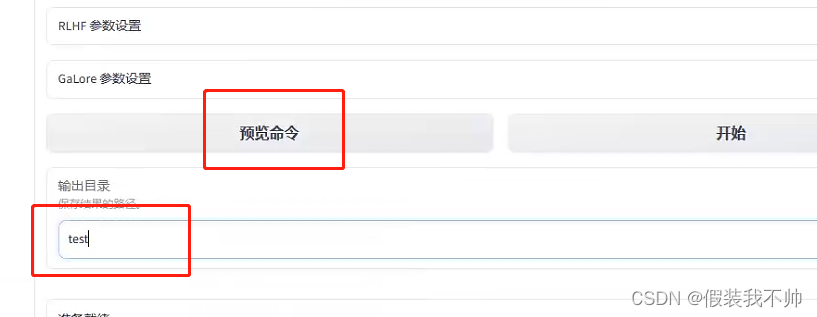
预览命令
python src/train_bash.py --stage sft --do_train True --model_name_or_path Qwen/Qwen1.5-0.5B-Chat --finetuning_type lora --template qwen --dataset_dir data --dataset identity,alpaca_gpt4_zh --cutoff_len 1024 --learning_rate 0.0002 --num_train_epochs 5.0 --max_samples 500 --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --max_grad_norm 1.0 --logging_steps 5 --save_steps 100 --warmup_steps 0 --optim adamw_torch --output_dir saves\Qwen1.5-0.5B-Chat\lora\test --fp16 True --lora_rank 8 --lora_alpha 16 --lora_dropout 0.1 --lora_target all --use_dora True --plot_loss True
NotImplementedError: Loading a dataset cached in a LocalFileSystem is not supported.

pip install fsspec==2023.9.2
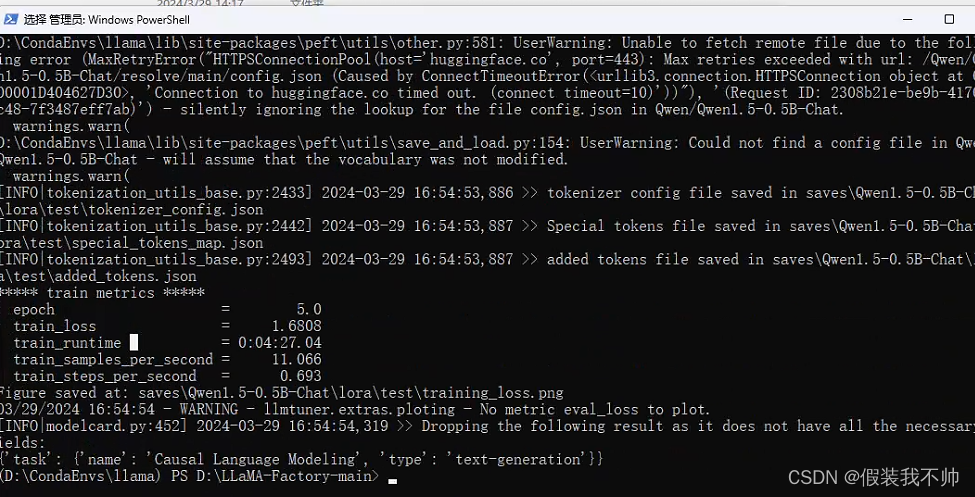
训练完毕,刷新适配器然后加载

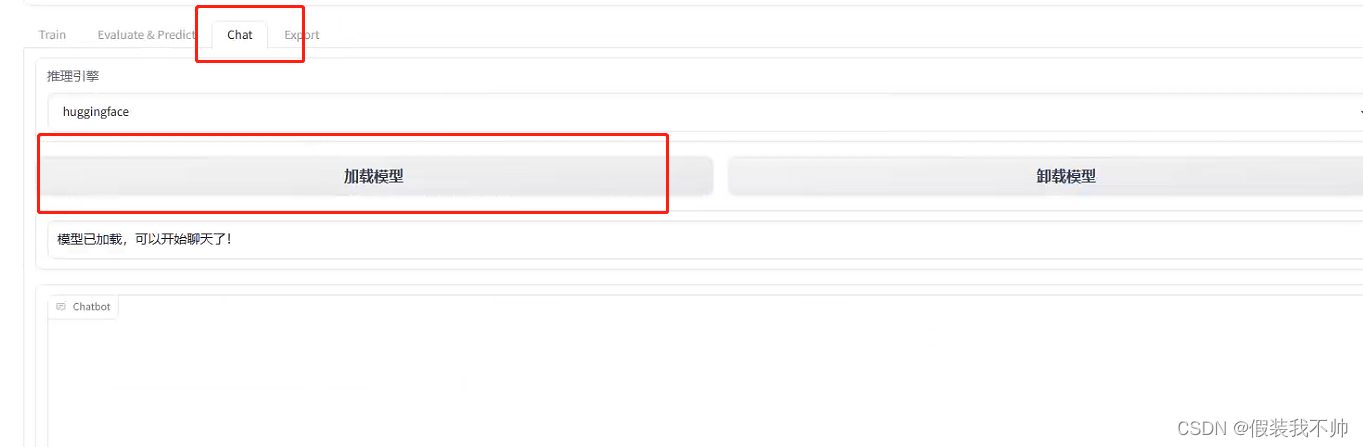

chatglm类似,它支持很多模型
白嫖手册
参考
参考
参考
ChatGLM2-6B
https://github.com/hiyouga/ChatGLM-Efficient-Tuning/tree/main
https://github.com/hiyouga/ChatGLM-Efficient-Tuning/blob/main/examples/alter_self_cognition.md
微调
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
这篇关于更改chatglm认知的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







