bias专题

方差(Variance) 偏差(bias) 过拟合 欠拟合
机器学习中方差(Variance)和偏差(bias)的区别?与过拟合欠拟合的关系? (1)bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。 低偏差和高方差(对应右上图)是使得模型复杂,增加了模型的参数,这样容易过拟合。 这种情况下,形象的讲,瞄的很准,但手不一定稳。 (2)varience描述的是样本上训练出来的模型

PyTorch 入坑十:模型泛化误差与偏差(Bias)、方差(Variance)
问题 阅读正文之前尝试回答以下问题,如果能准确回答,这篇文章不适合你;如果不是,可参考下文。 为什么会有偏差和方差?偏差、方差、噪声是什么?泛化误差、偏差和方差的关系?用图形解释偏差和方差。偏差、方差窘境。偏差、方差与过拟合、欠拟合的关系?偏差、方差与模型复杂度的关系?偏差、方差与bagging、boosting的关系?偏差、方差和K折交叉验证的关系?如何解决偏差、方差问题? 本文主要参考知

Andrew Ng机器学习week6(Regularized Linear Regression and Bias/Variance)编程习题
Andrew Ng机器学习week6(Regularized Linear Regression and Bias/Variance)编程习题 linearRegCostFunction.m function [J, grad] = linearRegCostFunction(X, y, theta, lambda)%LINEARREGCOSTFUNCTION Compute cost an

bias和variance
在A Few Useful Thingsto Know about Machine Learning中提到,可以将泛化误差(gener-alization error)分解成bias和variance理解。 Bias: a learner’s tendency to consistently learn the same wrong thing,即度量了某种学习算法的平均估计结果所能逼
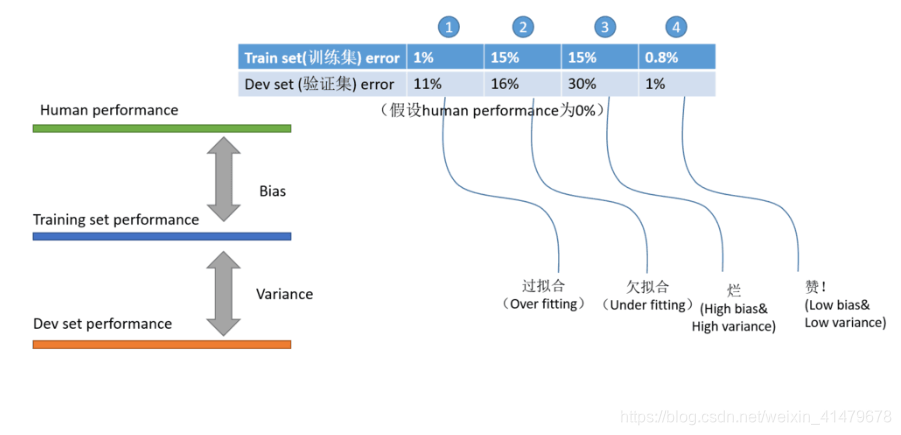
(done) 机器学习中的方差 variance 和 偏差 bias 怎么理解?
来源:https://blog.csdn.net/weixin_41479678/article/details/116230631 情况1属于:低 bias,高 variance (和 human performance 相近,但和 验证集dev set 相远) 通常意味着模型训练轮数太多 情况2属于:高 bias,低 variance (和 human performance 相远,

偏差Bias和方差Variance的区别 不要只会画靶子图 P值
偏差 Bias 偏差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的平均值和真实模型输出之间的偏差。 方差 Variance 方差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。方差通常是由于模型的复杂度相对于训练样本数m过高导致的,比如一共有100个训练样本,而我们假设模型是阶数不大于200的多项式函数。由方差带来的误差通常体现在测试误差相对于训练

神经网络中的偏置bias
https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408## https://blog.csdn.net/mmww1994/article/details/81705991
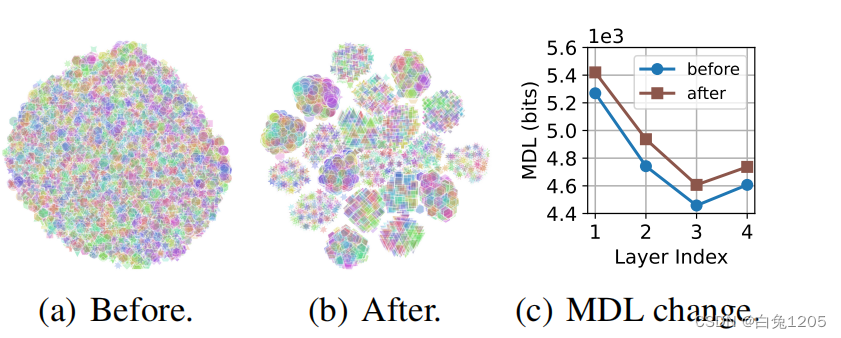
Eliminating Domain Bias for Federated Learning in Representation Space【文笔可参考】
文章及作者信息: NIPS2023 Jianqing Zhang 上海交通大学 之前中的NeurIPS'23论文刚今天传到arxiv上,这次我把federated learning的每一轮看成是一次bi-directional knowledge transfer过程,提出了一种促进server和client之间bi-directional knowledge transfer的方
偏差-方差分解bias-variance decomposition
方差、偏差的直观意义 方差维基百科定义: Var ( X ) = E [ ( X − μ ) 2 ] 其 中 μ = E ( X ) \operatorname{Var}(X)=\mathrm{E}\left[(X-\mu)^{2}\right] 其中\mu=\mathrm{E}(X) Var(X)=E[(X−μ)2]其中μ=E(X) 在给定数据集中 方差: var ( x ) =
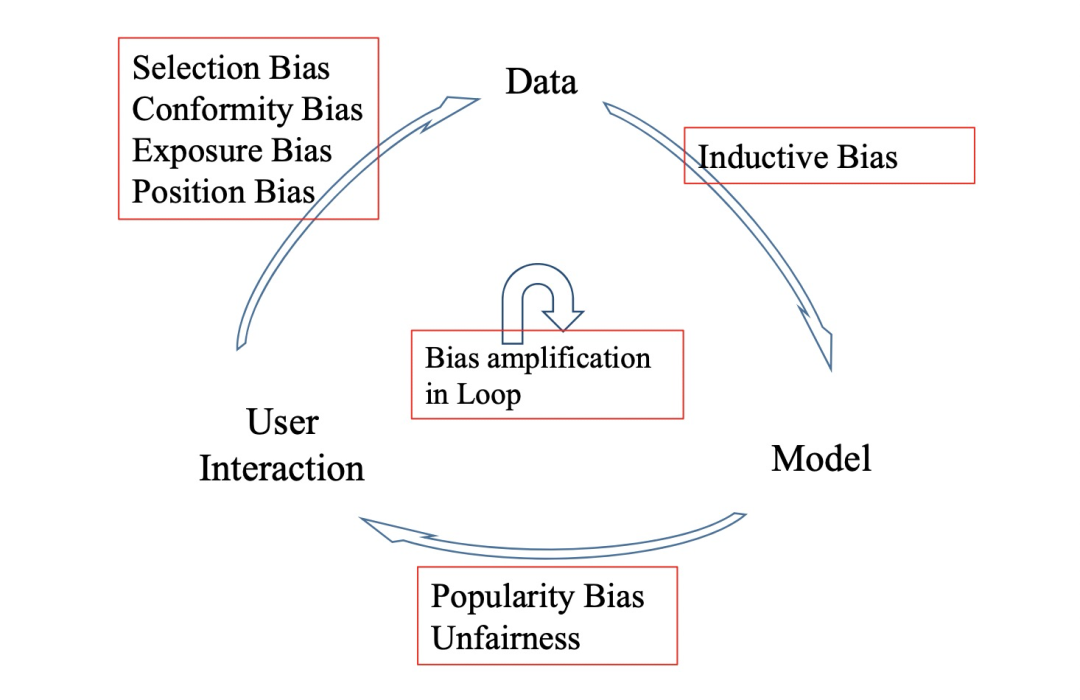
搜索推荐中的 Position Bias
在搜索推荐系统中,Bias可以说无处不在。之前我们整理过搜索、推荐、广告中的曝光偏差问题,今天来看看 position bias。 1. 什么是position bias Position-Bias是指 item 在展示页面的排序位置,及其相对广告的位置等。经验和有关论文都告诉我们,这种位置会影响item的点击率。这种影响跟用户的「真实兴趣」无关,而是跟用户的注意力、用户对广告的情绪有关。 例
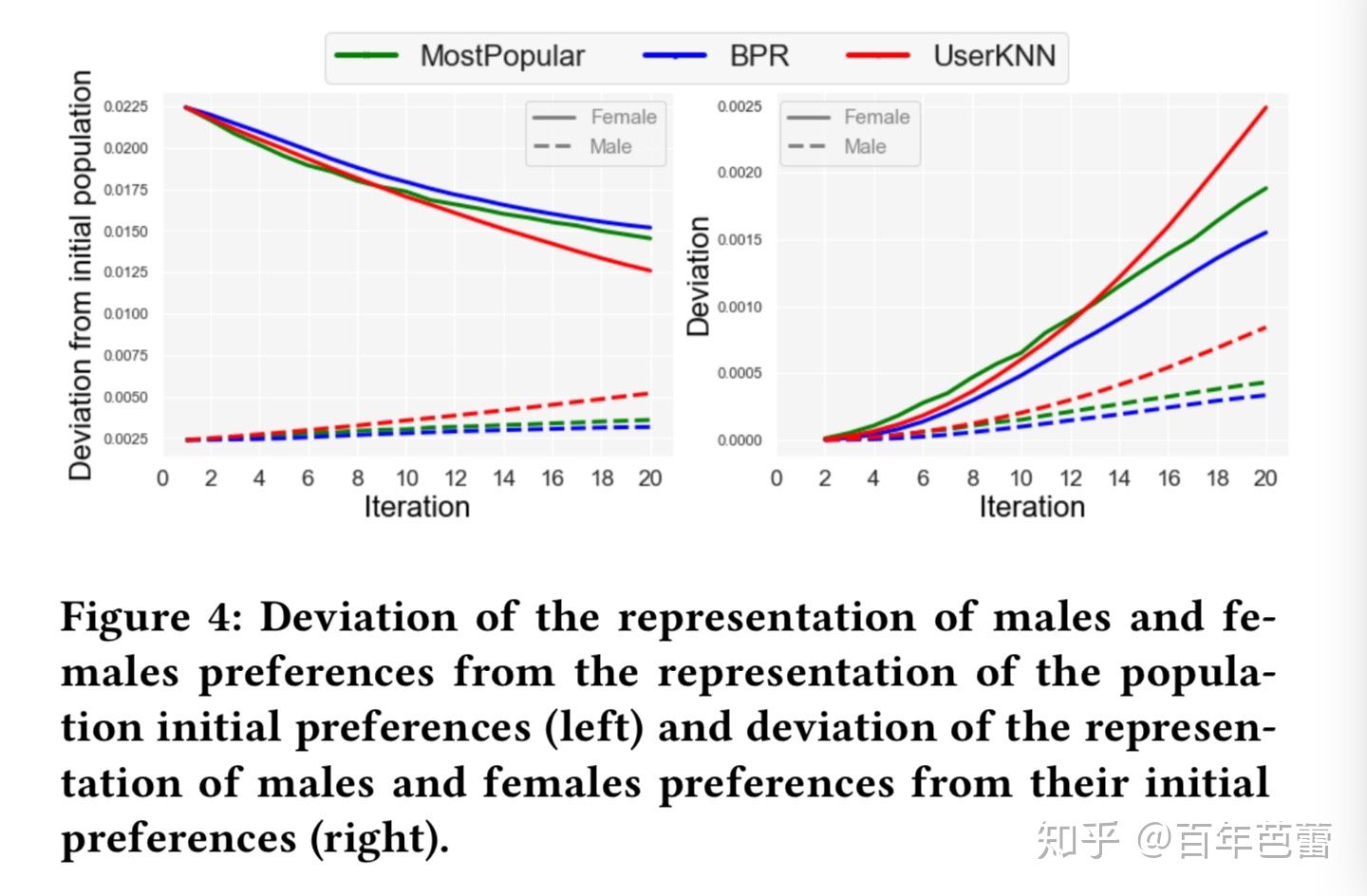
推荐系统漫谈之流行度偏置(popularity bias)与数据链路(Feedback Loop)
转自:https://zhuanlan.zhihu.com/p/272792754 推荐系统存在 popularity bias,即少部分物品被频繁曝光。系统记录下频繁曝光的日志,并基于日志数据制定推荐策略,这种反馈链路(Feedback Loop)进一步放大推荐系统的popularity bias,从而对推荐多样性、挖掘用户真实兴趣、用户体验等有着不利影响。引起popularity bias问
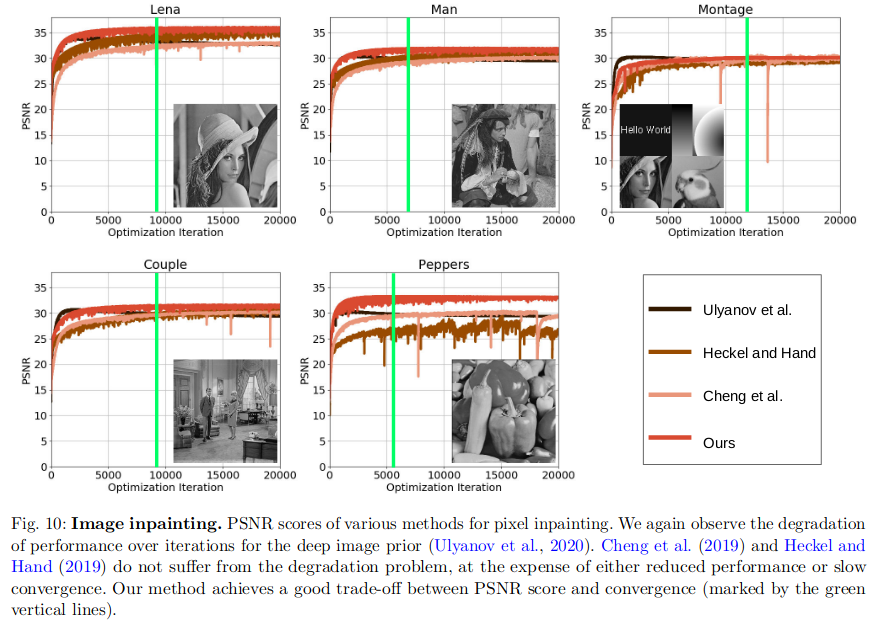
DIP: Spectral Bias of DIP 频谱偏置解释DIP
On Measuring and Controlling the Spectral Bias of the Deep Image Prior 文章目录 On Measuring and Controlling the Spectral Bias of the Deep Image Prior1. 方法原理1.1 动机1.2 相关概念1.3 方法原理频带一致度量与网络退化谱偏移和网
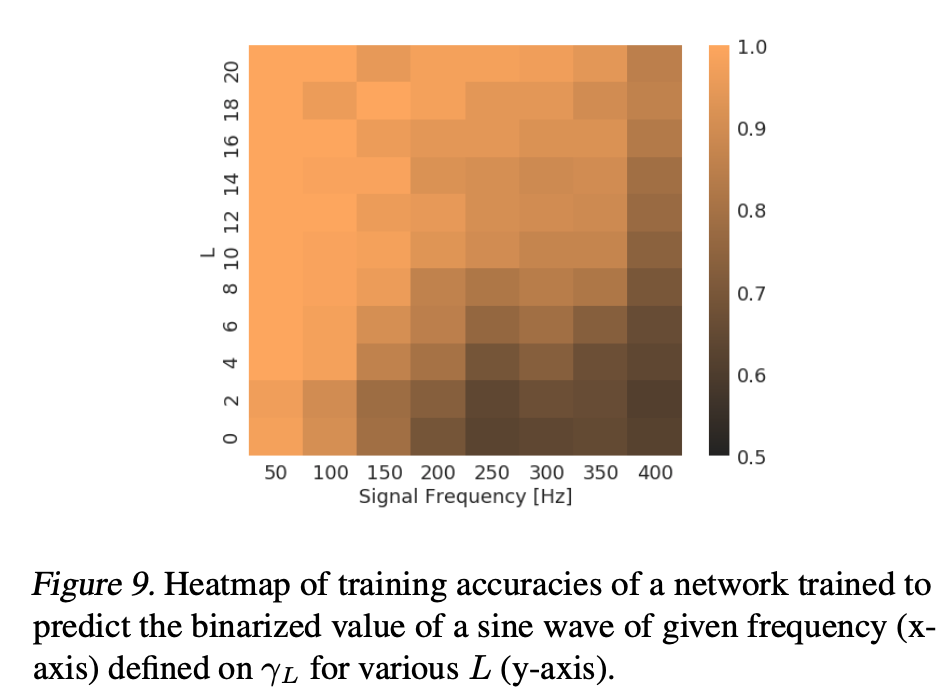
On the Spectral Bias of Neural Networks论文阅读
1. 摘要 众所周知,过度参数化的深度神经网络(DNNs)是一种表达能力极强的函数,它甚至可以以100%的训练精度记忆随机数据。这就提出了一个问题,为什么他们不能轻易地对真实数据进行拟合呢。为了回答这个问题,研究人员使用傅里叶分析来研究深层网络。他们证明了具有有限权值(或训练有限步长)的深度网络天生偏向于表示输入空间上的平滑函数。具体地说,深度ReLU网络函数的特定频率分量(k)的衰减速度至少与

【深度学习每日小知识】Bias 偏差
计算机视觉是人工智能的一个分支,它使机器能够解释和分析视觉信息。然而,与任何人造技术一样,计算机视觉系统很容易受到训练数据产生的偏差的影响。计算机视觉中的偏见可能会导致不公平和歧视性的结果,从而使社会不平等长期存在。本文深入探讨了计算机视觉中偏见的复杂性及其影响,并探讨了减轻偏见、促进公平和公正结果的方法。 了解计算机视觉中的偏差 计算机视觉算法经过大量视觉数据(例如图像和视频)的训练。如果训

机器学习基础题——什么是Bias?什么是Variance?如何解决过拟合和欠拟合问题?
机器学习基础 1.什么是Bias?什么是Variance?2.如何解决过拟合和欠拟合问题? Bias:反映的是模型在样本上的输出与真实值之间的误差,即模型的精准度(单个模型的学习能力) Variance:反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性(同一个算法在不同的数据集上的不稳定性) 机器学习中的调优方向:High Bias + Low Variance,即上图左

零样本学习Domain-aware Visual Bias Eliminating for Generalized Zero-Shot Learning
文章目录 提出背景ZSL的常见问题跨数据集偏差异构特征对齐本真语义表示 Domain-aware Visual Bias Eliminating for Generalized Zero-Shot LearningAbstractIntroductionRelated WorksGZSL的范式semantic-visual alignment?biased recognition probl
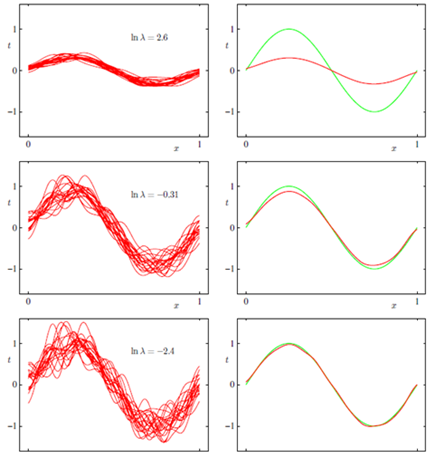
机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
原文:http://www.zhihu.com/question/20448464 5 个回答 Jason Gu, 肖子达、RainVision、舟舟舟 等人赞同 偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。 方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下
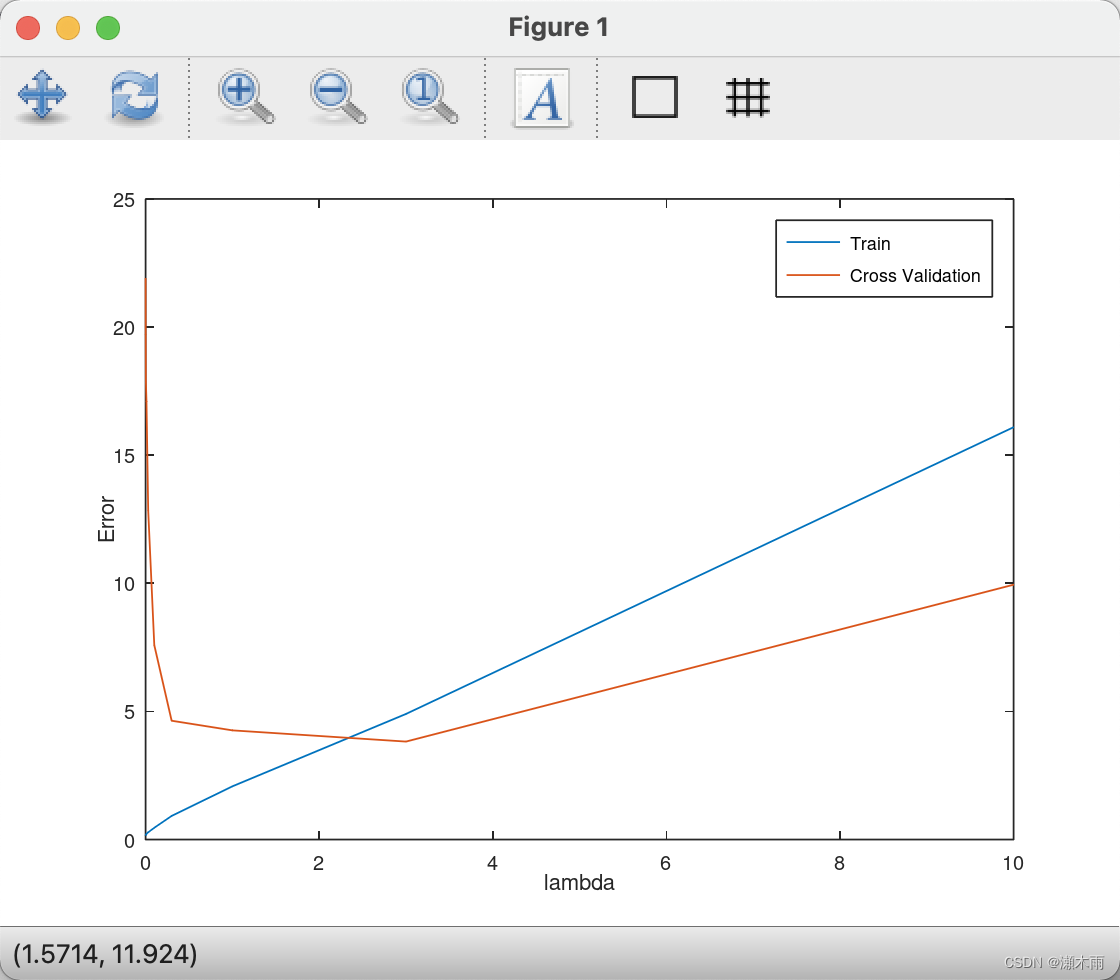
吴恩达老师机器学习ex5.Regularized Linear Regression and Bias v.s.Variance
吴恩达 机器学习 第六周作业 Regularized Linear Regression and Bias v.s.Variance Octave代码 linearRegCostFunction.m function [J, grad] = linearRegCostFunction(X, y, theta, lambda)%LINEARREGCOSTFUNCTION Compute co

Seq2Seq中的Exposure Bias现象的原因以及解决办法
文章目录 参考资料原因解决办法Scheduled SamplingSentence Level Oracle Word + Gumbel Noise对抗训练基于强化学习直接优化BLEU 参考资料 本文是下列资料的总结: [1] 李宏毅视频 59:36 开始 [2] Seq2Seq中Exposure Bias现象的浅析与对策 [3] Bridging the Gap bet

Transformer-Attention优化:ALiBi(Attention with Linear Bias)【提升外推性】
论文地址: https://arxiv.org/pdf/2108.12409.pdf 我们都知道,文本长度一直是 transformer 的硬伤。 不同于 RNN,transformer 在训练时必须卡在一个最大长度上, 而这将会导致训练好的模型无法在一个与训练时的长度相差较远的句子上取得较好的推理结果。 ALiBi 是 22 年提出的一种方法,其目的就是解决 transformer
Bias in Emotion Recognition with ChatGPT
本文是LLM系列文章,针对《Bias in Emotion Recognition with ChatGPT》的翻译。 chatGPT在情绪识别中的偏差 摘要1 引言2 方法3 结果4 讨论5 结论 摘要 本技术报告探讨了ChatGPT从文本中识别情绪的能力,这可以作为交互式聊天机器人、数据注释和心理健康分析等各种应用程序的基础。虽然先前的研究已经表明ChatGPT在情绪分析方面

tensorflow bias_add
import tensorflow as tfa=tf.constant([[1,1],[2,2],[3,3]],dtype=tf.float32)b=tf.constant([1,-1],dtype=tf.float32)c=tf.constant([1],dtype=tf.float32)with tf.Session() as sess:print('bias_add:')print
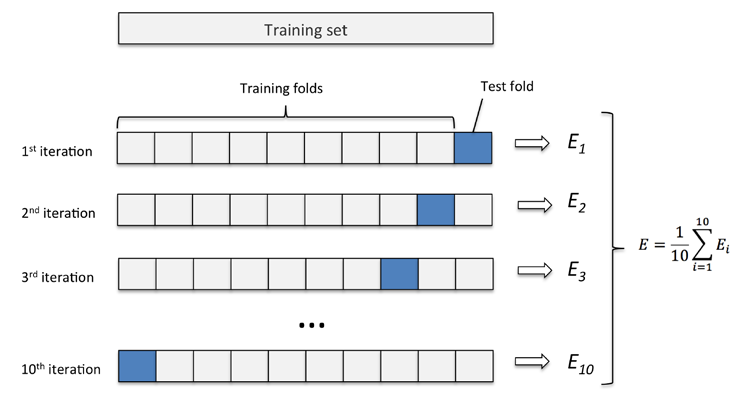
Bias-Variance Tradeoff (权衡偏差与方差)
转自:https://blog.csdn.net/qq_30490125/article/details/52401773 对学习算法除了通过实验估计其泛化性能,我们还希望了解“为什么”具有这样的性能。“偏差-方差分解”(bias-variance decomposition)是解释学习算法泛化性能的一种重要工具。 偏差和方差 理解偏差和方差这两个不同来源导致的误差可以帮助我们更好得拟合数据