本文主要是介绍Eliminating Domain Bias for Federated Learning in Representation Space【文笔可参考】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章及作者信息:
NIPS2023 Jianqing Zhang 上海交通大学
之前中的NeurIPS'23论文刚今天传到arxiv上,这次我把federated learning的每一轮看成是一次bi-directional knowledge transfer过程,提出了一种促进server和client之间bi-directional knowledge transfer的方法,从而同时提升generalization和personalization性能,该方法可以用在现有的FL和pFL算法上,提高它们的性能。对于improved bi-directional knowledge transfer我还提供了理论支持。大家感兴趣的话,可以先看看,论文地址https://arxiv.org/abs/2311.14975,项目地址(包含代码、ppt、poster):https://github.com/TsingZ0/DBE。希望能给大家一点从knowledge transfer角度看federated learning的启发。
knowledge transfer是普遍存在的一个问题,而且有很多现有的工具和理论支撑。站在这个角度思考问题,比较能理解模型学习过程的深层原理
摘要:
针对表征偏差——>提出通用框架域偏差消除器(Domain Bias Eliminator ,DBE)—>促进服务器和客户端之间的双向知识转移
在统计异构场景下,客户端上有偏差的数据域会导致表征偏差现象,并在局部训练过程中进一步退化一般表征,即表征退化现象。
这个现象是不是客户端灾难遗忘问题?
——>提出通用框架域偏差消除器(Domain Bias Eliminator ,DBE)
理论分析表明,DBE可以促进服务器和客户端之间的双向知识转移,因为它减少了服务器和客户端在表示空间中的域差异
理论分析是在文章中进行公式或数学证明吗
四个数据集上从泛化能力和个性化验证
泛化能力(最小描述长度衡量)和个性化能力(精度衡量)分别的实验是哪些?
优于十种最先进的个性化FL方法
十种比较方法的选择与参数呢?
统计异质性:每个客户端的数据域是有偏差的,不包含所有标签的数据
传统联邦学习:通过在客户端本地训练模型和在服务器上聚合客户端模型,以迭代的方式学习一个单一的全局模型
存在统计异构—>准确率下降(每个客户端的数据域有偏差,不包含所有标签数据)
表征偏差:
由于接收到的全局模型是在个别客户的有偏差数据域上进行局部训练的,该模型在局部训练期间提取有偏差(即形成特定于客户的聚类)表示。通过训练接收到的带有缺失标签的全局模型,在局部训练过程中,所有标签的通用表征质量也会下。
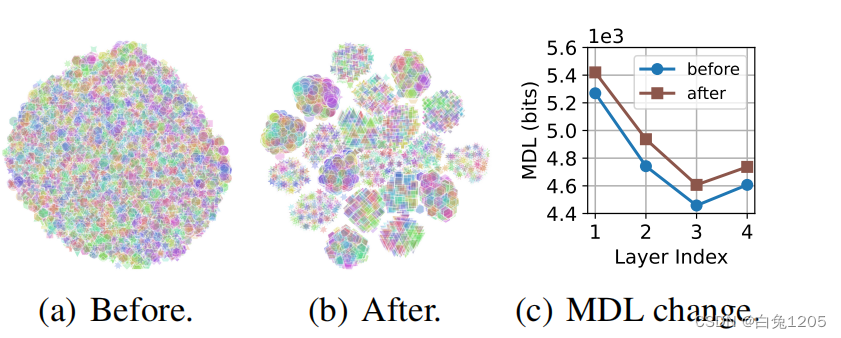
t-SNE学会如何使用!!!
t-SNE(t-分布随机邻近嵌入)是一种流行的机器学习算法,主要用于数据降维。在联邦学习中,t-SNE的使用通常集中在以下几个方面:
- 数据可视化:由于联邦学习中的数据通常分布在多个客户端上,而且每个客户端可能拥有大量的高维数据点,t-SNE可以帮助我们将这些数据点降到2维或3维,以便于进行可视化分析,更好地理解数据分布和模式。
- 特征抽取:在联邦学习模型训练之前,可以使用t-SNE对数据进行降维,提取出最重要的特征,这有助于减少模型训练的复杂性,并且可能提高模型在低维空间中的表现。
- 提高通信效率:通过降维,可以减少需要传输的数据量,从而提高联邦学习中的通信效率。这对于带宽受限的联邦学习环境尤为重要。
- 促进模型聚合:在联邦学习的聚合阶段,各个客户端的数据需要被综合起来。使用t-SNE可以确保不同客户端的数据在降维后能够更好地匹配,有助于提高模型聚合的效果。
- 辅助模型解释性:降维后的数据更容易被人类理解,这对于解释联邦学习模型的预测和决策是有益的。
提出架构:
为解决FL中的表示偏差和表示退化问题—>提出了一个用于FL的通用框架域偏差消除器(DBE)
模块一:从原始表征中分离表征偏差,并将其保存在每个客户端的个性化表征偏差记忆(PRBM)中;
模块二:设计了一种均值正则化(Mean Regularization, MR),明确引导局部特征提取器在局部训练过程中提取具有共识全局均值的表征,使局部特征提取器专注于剩余的无偏信息,提高一般表征质量—>将每个客户端的特征提取器和分类器之间的一层表示分别转换为具有客户端特定偏差和客户端不变平均值的两层表示。
模块一和二的最终目标——>消除为客户需求提取具有客户特定偏差的表示的冲突,同时在相同的表示空间中为服务器需求提取具有客户不变特征的表示
效果:DBE能够以较低的泛化界限促进服务端和客户端之间的双向知识传递
客户端:特征提取器和分类器
理解:
场景:经典的联邦学习多类分类任务中的统计异构场景(N个客户端共享相同的模型结构)
针对表征偏差提出DBE—>可结合FedAvg方法(FedAvg+DBE){形成新的个性化联邦学习架构}
实验与十种最先进的个性化联邦学习比较
基于FedAvg方法解决统计异构问题:
基于更新校正的FL
基于正则化的FL
基于模型分裂的FL
基于知识蒸馏的FL
个性化联邦学习:
基于元学习的pFL
基于正则化的pFL
基于个性化聚合的pFL
基于模型分裂的pFL
联邦学习中的表示学习:
在联邦学习中,表示学习(Representation Learning)是一个重要方面,它涉及到如何在本地数据集上训练模型,以便在保护隐私的同时获得有效的模型参数。表示学习通常包括以下几个步骤:
- 特征提取:在本地数据集上进行训练之前,首先进行特征提取。这涉及从原始数据中提取有助于模型训练的信息。这些特征可以是图像的直方图、文本的词嵌入等。
- 模型训练:使用提取的特征,在本地数据集上训练模型。训练过程可以是监督学习、无监督学习或半监督学习,具体取决于应用场景和需求。
- 模型更新:一旦模型在本地训练完毕,参与者会比较各自的模型参数,并基于某种共识算法(如联邦平均算法)更新全局模型。
- 模型聚合:在多次迭代后,全局模型会在参与者之间聚合,以获得一个共同的模型,这个模型在所有参与者上都是可用的。
为了保护隐私,联邦学习中的表示学习通常遵循以下原则:
- 差分隐私:在模型训练过程中应用技术,如噪声添加,以保证训练数据的隐私。
- 同态加密:在参与者之间传输信息时使用同态加密,确保数据在传输过程中的安全。
- 联邦学习框架的隐私和安全设计:设计时考虑如何保护用户数据,避免数据泄露。
表示学习的有效性和安全性对于联邦学习的成功至关重要。它不仅保证了数据的隐私,还能确保训练出的模型具有较高的预测性能。
这篇关于Eliminating Domain Bias for Federated Learning in Representation Space【文笔可参考】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








