本文主要是介绍On the Spectral Bias of Neural Networks论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 摘要
众所周知,过度参数化的深度神经网络(DNNs)是一种表达能力极强的函数,它甚至可以以100%的训练精度记忆随机数据。这就提出了一个问题,为什么他们不能轻易地对真实数据进行拟合呢。为了回答这个问题,研究人员使用傅里叶分析来研究深层网络。他们证明了具有有限权值(或训练有限步长)的深度网络天生偏向于表示输入空间上的平滑函数。具体地说,深度ReLU网络函数的特定频率分量(k)的衰减速度至少与O(k^2)一样快,宽度和深度分别以多项式和指数的方式帮助建模更高的频率。例如,这说明了为什么DNNs不能完美地记忆峰形三角函数。他们还表明,DNNs可以利用低维数据流形的几何形状,用简单函数近似流形上存在的复杂函数。因此,研究人员发现,所有被网络分类为属于某一类的样本(包括对抗本)都通过一条路径连接,这样网络沿着那条路径的预测就不会改变。最后,一般来说高频分量函数所对应的神经网络参数所占比重较小,这有助于正则化与抗过拟合。
2. 引言
低频信息指的是颜色缓慢变化,代表着连续渐变的一块区域,这部分为低频信息。对于一副图像来说,除去高频就是低频,也就是边缘以内的内容为低频,而边缘内的内容就是图像的大部分信息,即图像的大致概貌和轮廓,是图像的近似信息。
反之,图像边缘的灰度值变化快,就对应着高频。图像的细节处也就是属于灰度值急剧变化的区域,正是因为灰度值的急剧变化,才会出现细节。另外对于噪声,在一个像素所在的位置,之所以是噪点,是因为它与正常的点颜色不一样了,也就是说该像素点灰度值明显不一样,所以是高频部分。
通常,图像的低频是图像中对象的大致概况内容,高频对应噪声和细节。神经网络更倾向于拟合高频信息,而人类主要关注低频信息,然而对低频分量的学习,更有助于网络提高在对抗干扰过程中的鲁棒性。
主要贡献:
- 利用连续分段线性结构对ReLU网络的傅里叶谱分量进行分析。
- 发现了谱分量偏差(Spectrum bias)的经验证据,来源于低频分量,然而对低频分量的学习,有助于网络在对抗干扰过程中的鲁棒性。
- 通过流形理论,给予学习理论框架分析。
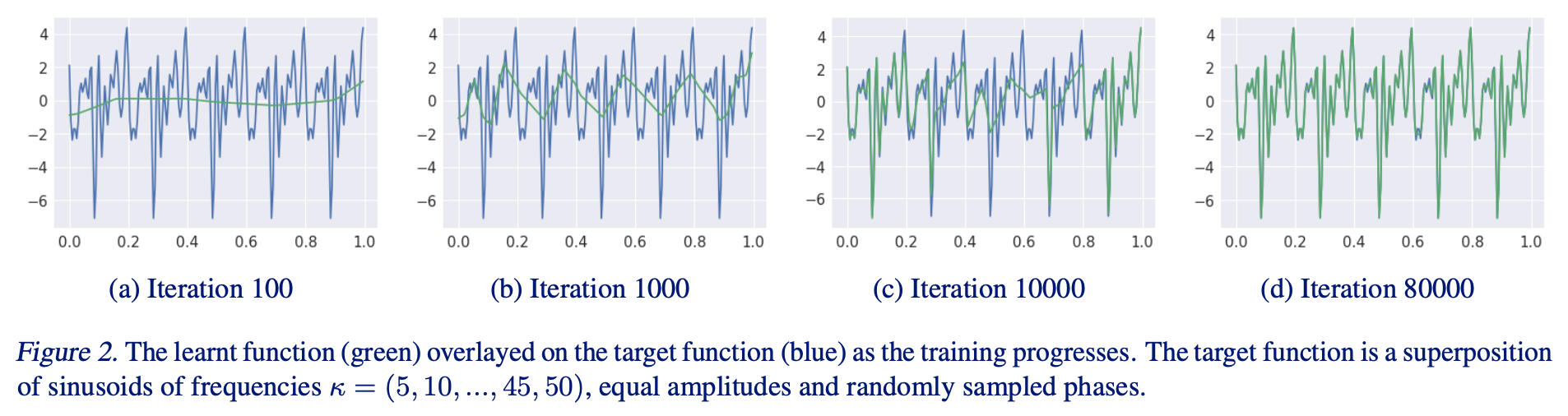
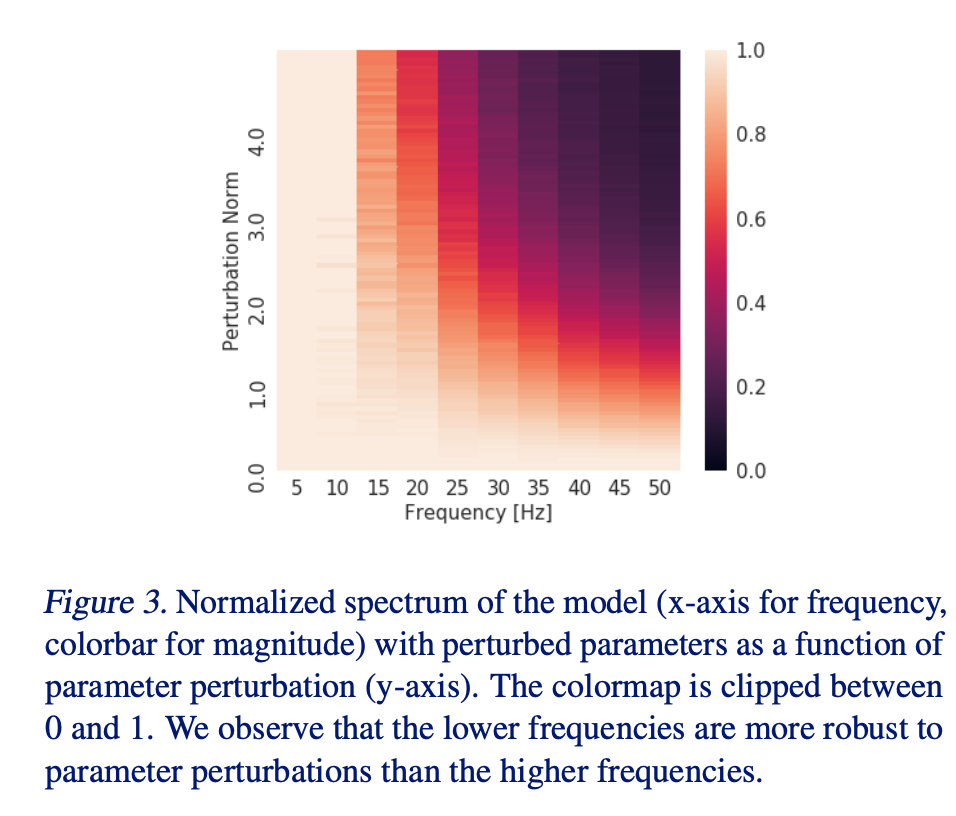
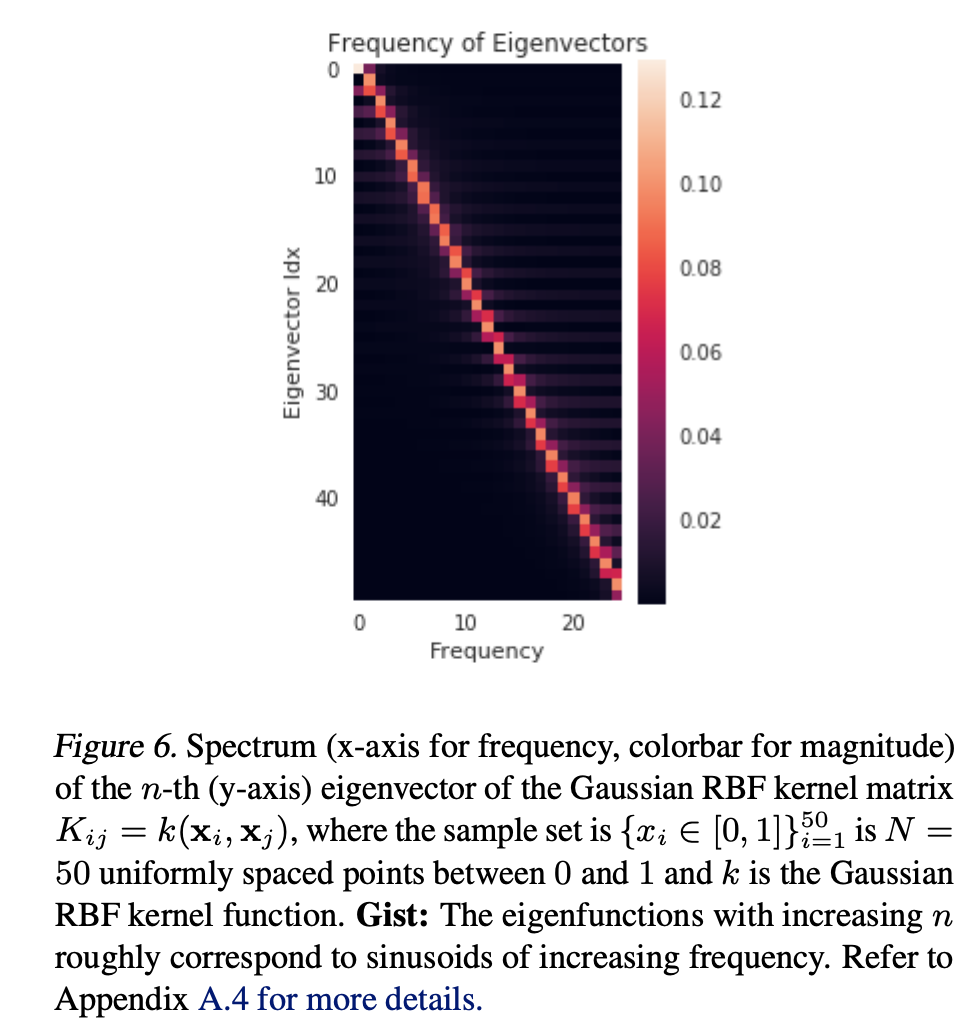
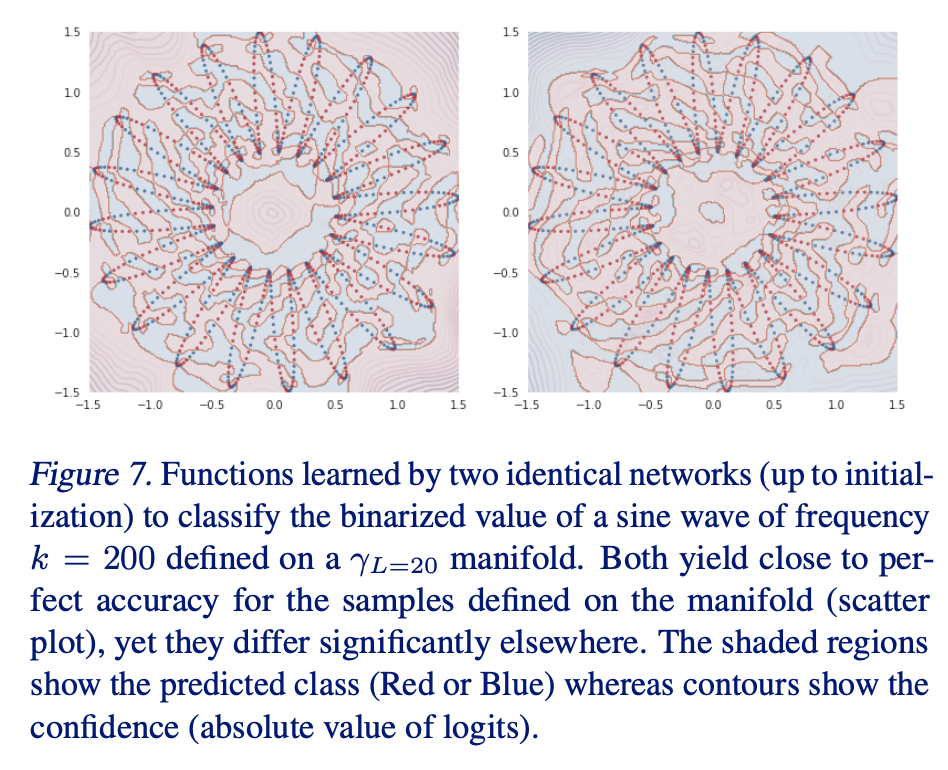
3. 实验结果



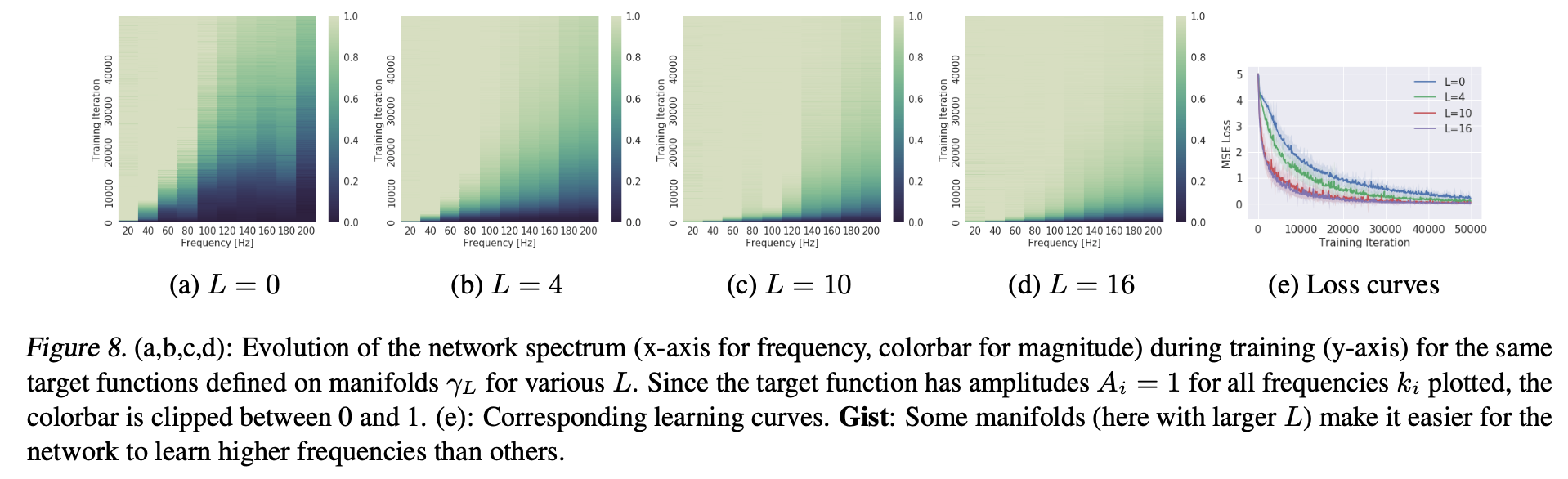
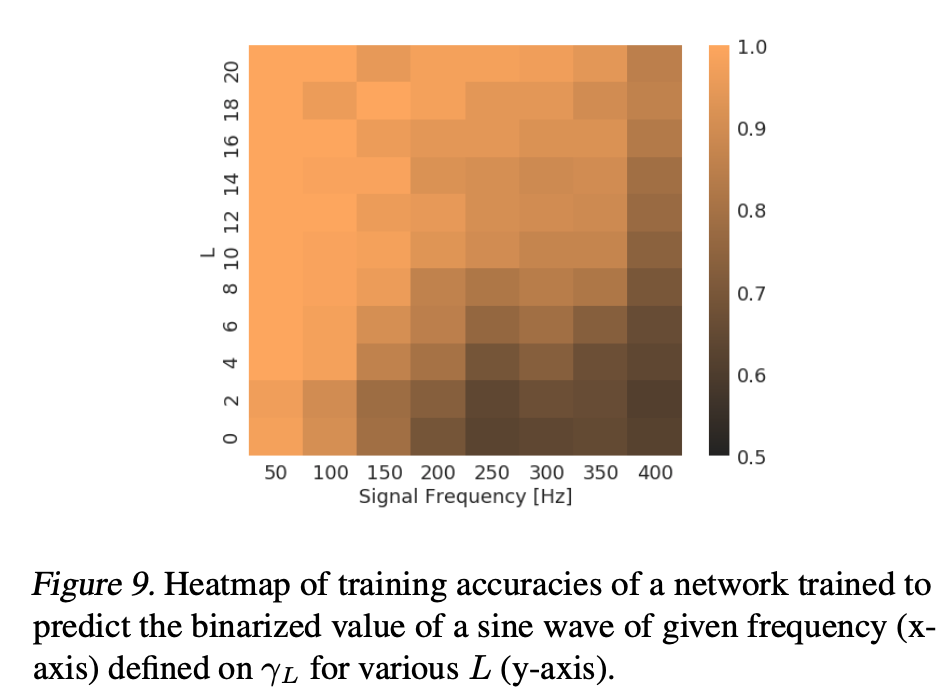
参考文献
On the Spectral Bias of Neural Networks
On the Spectral Bias of Deep Neural Networks笔记 - 知乎
去芜存三菁,On Spectral Bias of Deep Neural Networks精读上 - 知乎
这篇关于On the Spectral Bias of Neural Networks论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
