bge专题

深入RAG优化:BGE词嵌入全解析与Landmark Embedding新突破
前面已经写过一篇关于Embedding选型的文章,《如何高效选择RAG的中文Embedding模型?揭秘最佳实践与关键标准!》,主要介绍通过开源网站的下载量和测评效果选择Embedding模型。 一、Embedding选型建议与结果 选型建议: 1、大部分模型的序列长度是 512 tokens。8192 可尝试 tao-8k,1024 可尝试 stella。 2、在专业数据领域上,嵌入

LLM大语言模型调用本地知识库+faiss+m3e-base或是bge-m3 超级简单教程本地存储
LLM大语言模型调用本地知识库+faiss超级简单教程本地存储: 1、新建数据集./data/dz.json: [{"id": "0","text": "你的名字","answer": "张三"}, {"id": "1","text": "你是哪个公司开发的","answer": "xxxxxxxxx公司"},.......更多知识库] 2、下载模型如: moka-ai/m3e-ba

【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding)
【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding) 1. 环境准备2. 数据准备3. RAG框架构建3.1 数据读取 + 数据切块3.2 构建向量索引3.3 检索增强3.4 main函数 参考 基于LlamaIndex框架,以Qwen2-7B-Instruct作为大模型底座,bge-base-

BGE向量模型架构和训练细节
模型论文:https://arxiv.org/pdf/2309.07597 模型数据:https://data.baai.ac.cn/details/BAAI-MTP 训练数据 由无标签数据和有标签数据组成。 无标签数据使用了悟道等数据集,有标签数据使用了dureader等数据集。 都是文本对,对于无标签数据还使用Text2Vec-Chinese过滤掉得分低于0.43的pair。 有标签数
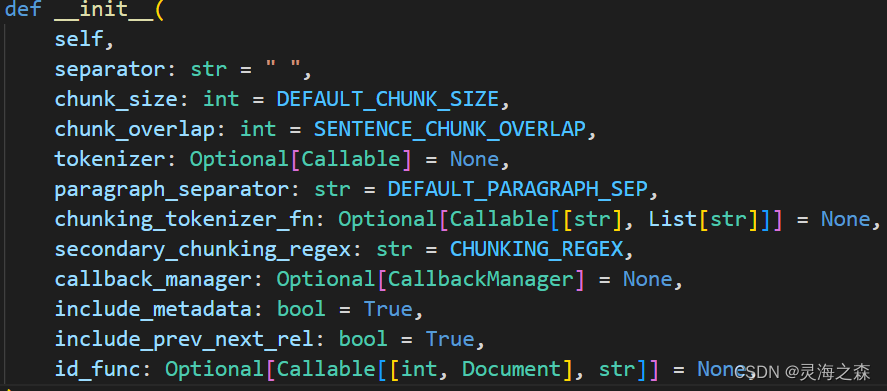
llama_index微调BGE模型
微调模型是为了让模型在特殊领域表现良好,帮助其学习到专业术语等。 本文采用llama_index框架微调BGE模型,跑通整个流程,并学习模型微调的方法。 一、环境准备 Linux环境,GPU L20 48G,Python3.8.10。 pip该库即可。 二、数据准备 该框架实现了读取各种类型的文件,给的示例就是pdf。 因此准备了一些网络舆情相关的论文pdf,选择70%作为训练数据,剩

【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式,本地运行main成功
1,关于 localai LocalAI 是一个用于本地推理的,与 OpenAI API 规范兼容的 REST API。 它允许您在本地使用消费级硬件运行 LLM(不仅如此),支持与 ggml 格式兼容的多个模型系列。支持CPU硬件/GPU硬件。 【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式

BGE 模型转 onnx
BGE 模型 下载地址:https://hf-mirror.com/BAAI/bge-small-zh-v1.5 from transformers import AutoTokenizer, AutoModel, AutoConfigBGE_MODEL_PATH = '.../bge_small'tokenizer = AutoTokenizer.from_pretrained(BGE_M

知道智源开源最强语义向量模型BGE是什么吗?
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,可以满足大多数大模型应用场景的需求。同时它还支持商用许可,真是太棒了!
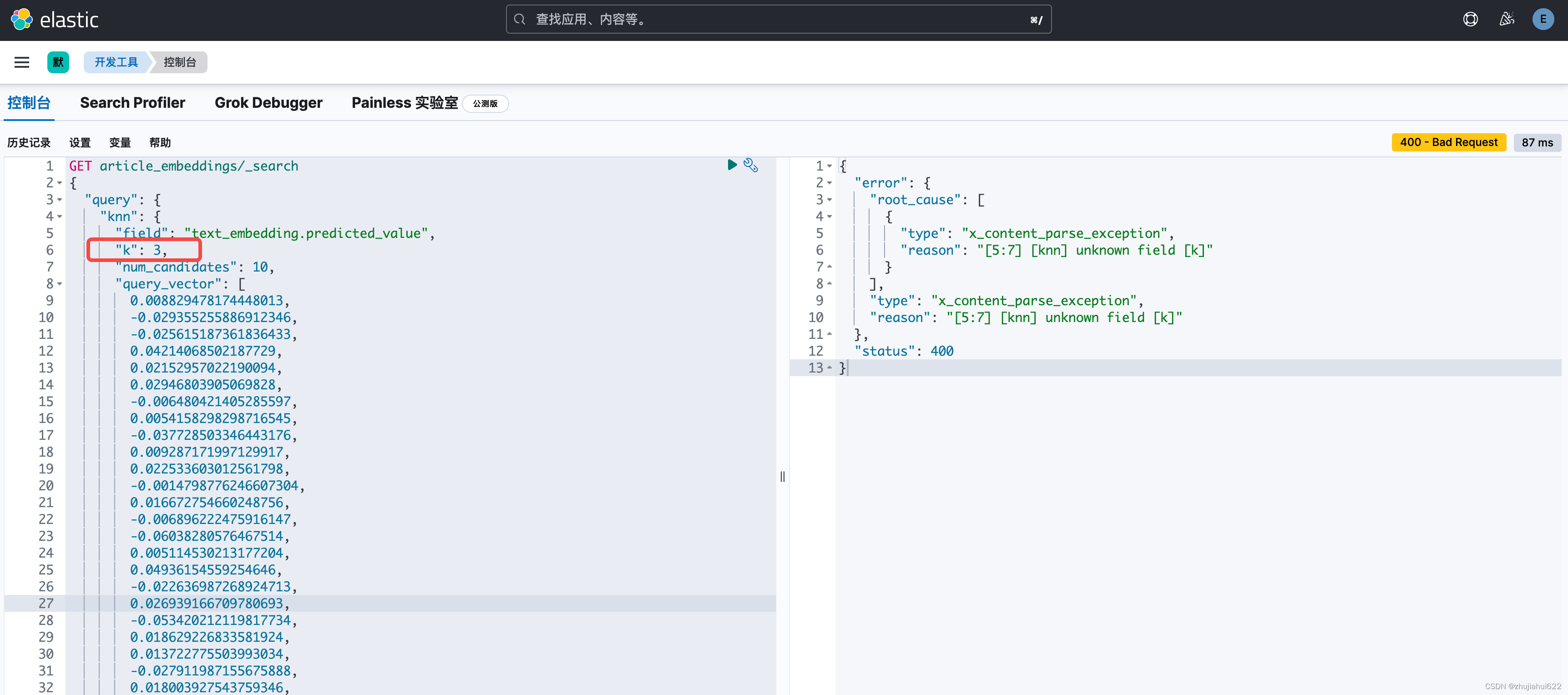
ElasticSearch中使用bge-large-zh-v1.5进行向量检索(一)
一、准备 系统:MacOS 14.3.1 ElasticSearch:8.13.2 Kibana:8.13.2 BGE是一个常见的文本转向量的模型,在很多大模型RAG应用中常常能见到,但是ElasticSearch中默认没有。BGE模型有很多版本,本次采用的是bge-large-zh-v1.5。下载地址: HuggingFace:https://huggingface.co/BA
Eland上传bge-base-zh-v1.5向量化模型到ElasticSearch中
最近需要做一些向量检索,试试ES 一、准备 系统:MacOS 14.3.1 ElasticSearch:8.13.2 Kibana:8.13.2 本地单机环境,无集群,也不基于Docker BGE是一个常见的文本转向量的模型,在很多大模型RAG应用中常常能见到,但是ElasticSearch中默认没有。BGE模型有很多版本,本次采用的是bge-base-zh-v1.5。下载

BGE M3:论文解读与代码实践,检索增强RAG实践新策略,BGE M3-Embedding方法实践与解读;检索增强生成
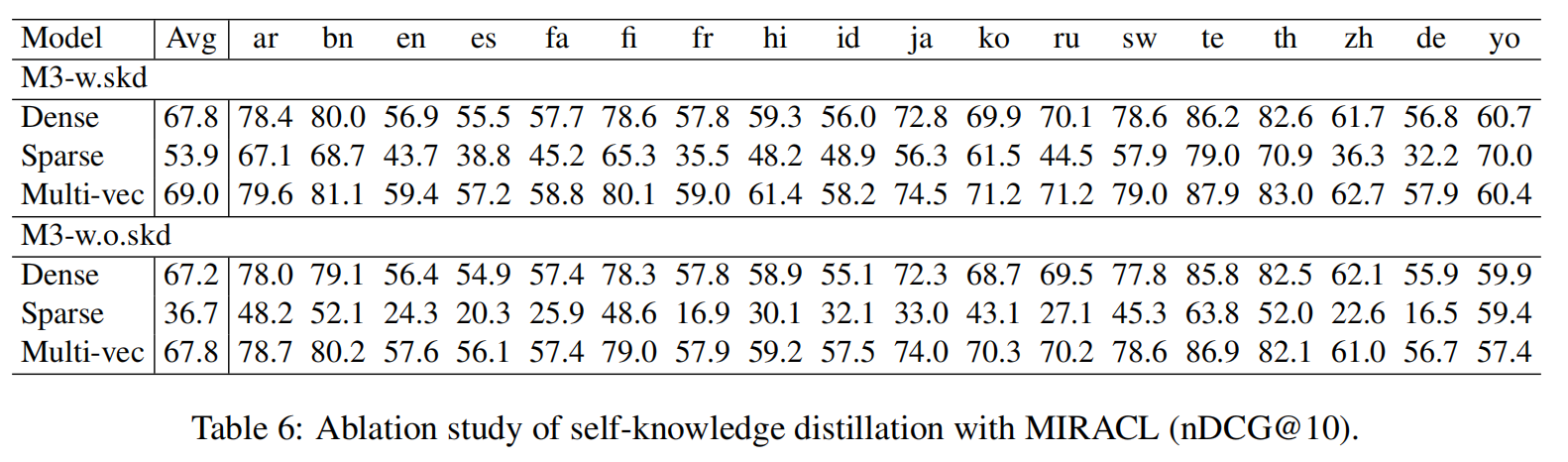
《BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation 》 1. 论文解读 In this project, we introduce BGE-M3, which is distinguished f
LLM大语言模型(八):ChatGLM3-6B使用的tokenizer模型BAAI/bge-large-zh-v1.5
背景 BGE embedding系列模型是由智源研究院研发的中文版文本表示模型。 可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。 BAAI/BGE embedding系列模型 模型列表 ModelLanguageDescriptionquery instruction for retrieval [1]BAAI/bge-m3Mu

langchain+chatglm3+BGE+Faiss Linux环境安装依赖
前言 本篇默认读者已经看过之前windows版本,代码就不赘述,本次讲述是linux环境配置 超短代码实现!!基于langchain+chatglm3+BGE+Faiss创建拥有自己知识库的大语言模型(准智能体)本人python版本3.11.0(windows环境篇) 依赖 1.pip包安装 python版本至少3.10以上 要注意python还有那些依赖包版本问题,不然乱七八糟的问题都会出
【LLM-RAG】BGE M3-embedding模型(模型篇|混合检索、多阶段训练)
note M3-Embedding联合了3种常用的检索方式,对应三种不同的文本相似度计算方法。可以基于这三种检索方式进行多路召回相关文档,然后基于三种相似度得分平均求和对召回结果做进一步重排。 多阶段训练过程: 第一阶段:第一阶段的自动编码预训练采用的是RetroMAE,在105种语言的网页跟wiki数据上进行,从而获得一个基底模型 第二阶段:在第一个数据源的弱监督数据进行预训练,这阶

一文通透Text Embedding模型:从text2vec、openai-ada-002到m3e、bge
前言 如果说半年之前写博客,更多是出于个人兴趣 + 读者需要,那自我司于23年Q3组建LLM项目团队之后,写博客就成了:个人兴趣 + 读者需要 + 项目需要,如此兼备三者,实在是写博客之幸运矣 我和我司更非常高兴通过博客、课程、内训、项目,与大家共同探讨如何把先进的大模型技术更好、更快的落地到各个行业的业务场景中,赋能千千万万公司的实际业务 而本文一开始是属于:因我司第三项目组「知识库问答项
![[论文笔记]BGE](https://img-blog.csdnimg.cn/img_convert/b1719d974e103a39ca7e66ff844f21f4.png)
RAG之微调垂域BGE的经验之谈
文章目录 前言数据格式部分代码训练参数接下来的尝试总结 前言 随着大模型的爆火,很多垂域行业都开始使用大模型来优化自己的业务,最典型的方法就是RAG(检索增强生成)了。简单来说就是利用检索技术,找出与用户问题相关性最高的段落,再让LLM基于以上段落,去回答用户的提问。这样的事情,在CSDN的时候其实也做过一次,参考:CSDN问答机器人。只不过当时是在SBERT模型上微调,也取

智源发布最强开源可商用中英文语义向量模型 BGE,超越同类模型,解决大模型制约问题
0.介绍 语义向量模型(Embedding Model)已经被广泛应用于搜索、推荐、数据挖掘等重要领域。 在大模型时代,它更是用于解决幻觉问题、知识时效问题、超长文本问题等各种大模型本身制约或不足的必要技术。然而,当前中文世界的高质量语义向量模型仍比较稀缺,且很少开源。 为加快解决大模型的制约问题,近日,智源发布最强开源可商用中英文语义向量模型 BGE(BAAI General Embe